HyperStudy和Optimus中使用样本数据快速创建代理模型(1/3)


背景
已有一组或一系列样本数据,如下图所示,目的是基于该组数据直接创建代理模型,以便于后续快速预测结果以及寻优。
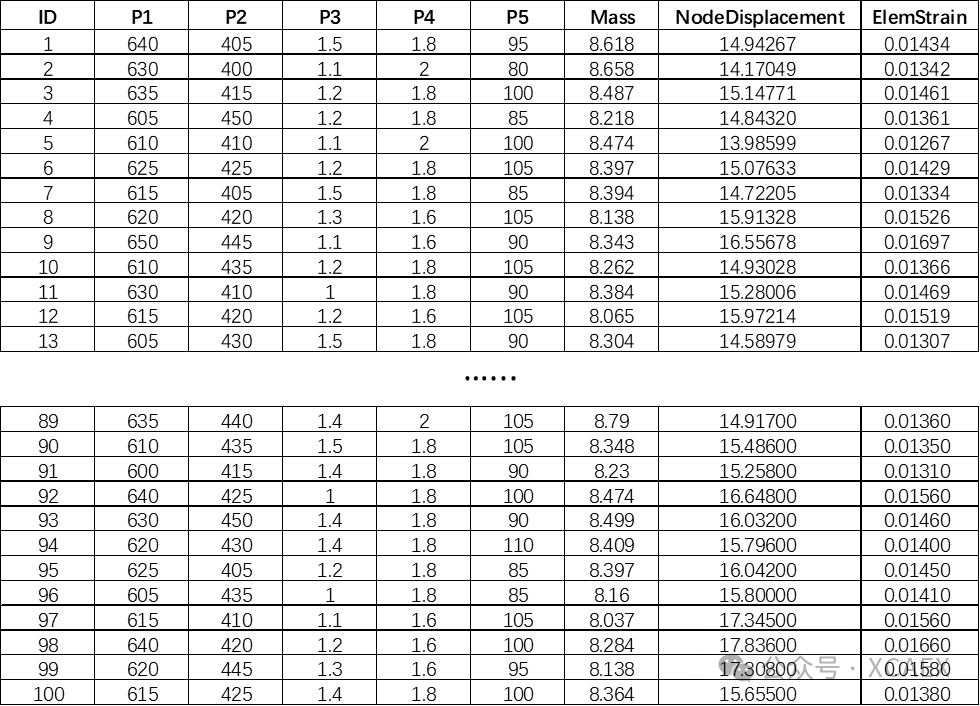
*上图数据中,第一列是ID,P1~P5为自变量(如模型中的料厚、尺寸等),Mass、NodeDisplacement、ElemStrain为因变量(也称响应,如模型的重量、计算结果的节点位移、单元应变等指标数据)
工具
本次将分别使用Altair HyperStudy和Noesis Optimus两款软件来基于数据快速创建代理模型。
数据准备
本次将分别使用Altair HyperStudy和Noesis Optimus两款软件来基于数据快速创建代理模型。 1、删除ID列:ID列的数据不参与训练,因此,需要现在表格工具中将其删除,如下图所示:


3、HyperStudy的数据准备到这一步就完成了;
4、Optimus需要对上述csv文件进行进一步编辑:

模型训练-HyperStudy
1、新建Study:打开界面,新建Study,并配置好路径和名称:

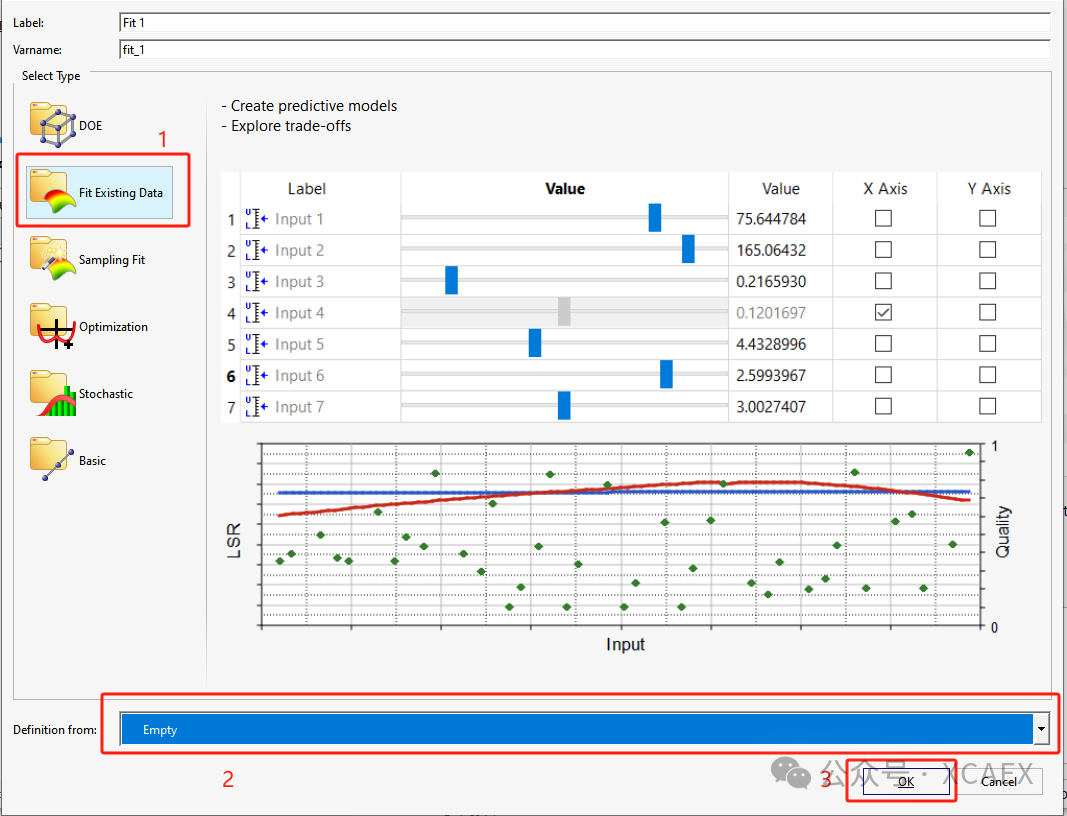
2、右键模型树空白处,选择Add,新增数据拟合模块“Fit Existing Data”,“Definition From”选择“Empty”,最后,点击界面右下方的“OK”按钮,完成添加:
3、选中模型定义节点“Define Models”:
4、切换到“Directory”,将准备好的csv文件拖入右侧模型窗体中,会自动创建一个名为“Model 1”的模型,type为“Lookup”。
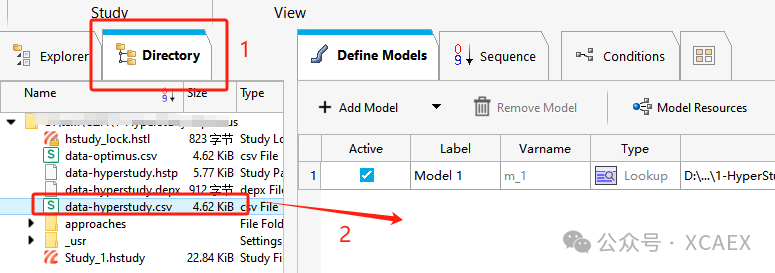
也可以手动单击右侧模型窗体的空白处,或者点击“+Add Model”按钮,添加类型为“Lookup”的模型,然后在Resource中手动关联数据文件:
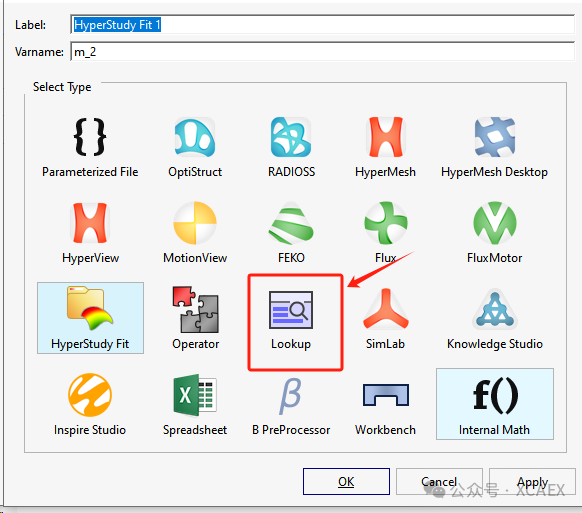
5、点击界面右下方的“Import Variables”或者模型行右侧的“Import”按钮,开始导入和定义数据:

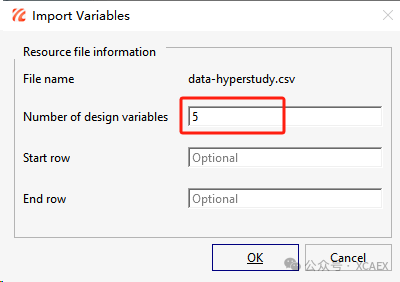
6、点击上述按钮后,界面会弹出如下对话框,分别有三行数据可填写,第一行是设计变量(自变量)的个数,本例中有五个设计变量(自变量),因此填入数字5;第二行为数据起始行,可选择填入或不填入;第三行为数据终止行,可选择填入或不填入。本例中第二行和第三行均不填入。最后,点击“ok”按钮完成变量的导入:
7、点击界面右下角“Next”按钮,进入下一步,输入变量的定义:

8、如下图所示,软件已经按照数据文件中的第一行的名称,以及第5步定义的自变量个数,自动解析并完成了输入变量(自变量)的设置,因此,如无特殊需求,可直接进入下一步:

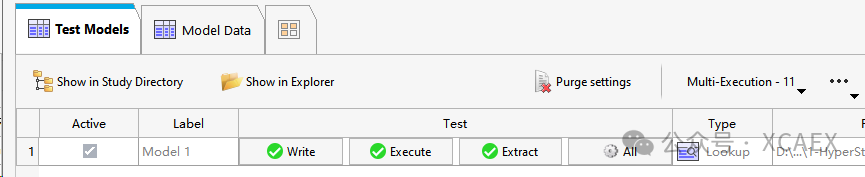
9、进入模型测试界面,点击下方的“Run Definition”,主要是测试是否能够跑通:

运行完成后,全部显示绿色,表示通过,可以进行下一步:
10、进入下一步,输出响应的定义“Define Output Response”,如下图所示,软件已经根据前面的设置,自动识别了输出响应,并且完成了Expression的生成,此处可以点击下方的“Evaluate”按钮,测试结果,界面中“Value”列,就是数据表格中第一行的数据,可自行检查,看是否正确:
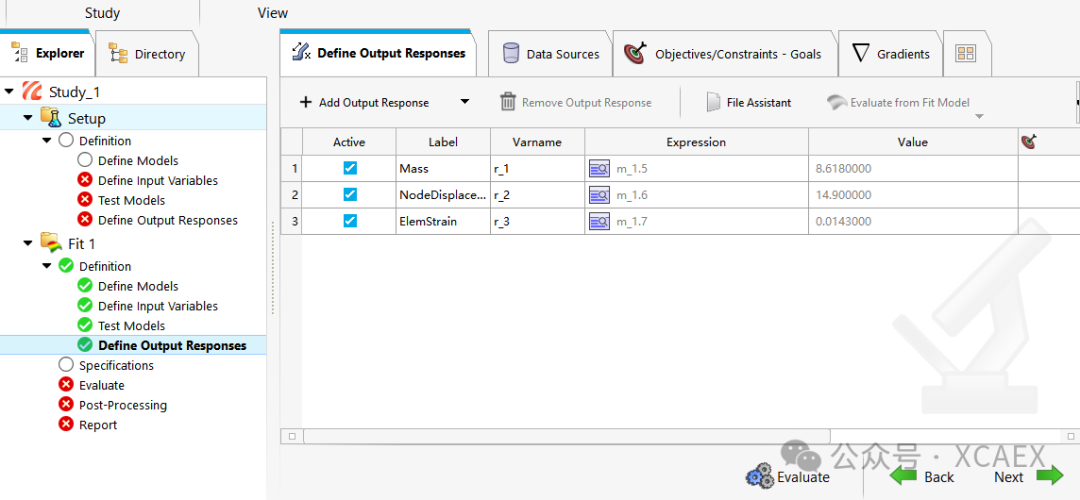
至此,便完成了HyperStudy软件中的数据导入工作。
由于篇幅原因,将在下一篇文章中介绍如何在HyperStudy中进行代理模型的创建,数据验证等操作。
希望大家点个关注,不迷路。
最后,大家有什么想了解的,也可以后台留言,感谢各位的观看。



