【HyperMesh宝典】之名字和ID

本讲假设求解器是Altair OptiStruct,但是对ANSYS,NASTRAN等一系列求解器也适用。
《唐伯虎点秋香》里,唐伯虎进华府做下人的时候,他的编号是9527,为什么不用名字而用编号呢?大概这样管家可以少用一点内存😄。

回到HyperMesh中来,HyperMesh中的对象除了以下37种对象有名字之外,其余类型的对象都只有编号。

名字基本上是前处理的概念,几乎所有对象到了求解器就只剩ID号了。
求解器读取fem文件的时候是自动跳过这些信息的(fem文件的注释)。大部分时候我们都希望名字里面能包含比较多的信息,比如component的名字要包含材料厚度信息,工况名字要包含工况的物理意义等。
不同的应用场景会对名字和ID号有不同的要求,本文通过9个虚拟应用场景展开讲解,方便大家理解。
场景1:增加/修改/删除asm/component/material/
prop名的字后缀或者前缀
场景2:将prop的名字修改为component的名字,如果prop同时赋给了多个component,需要分别复 制一份
场景3:比场景2再进一步,把属性按照单元进行分拆
场景4:把component的ID号改为属性的ID号
场景5:按照空间位置的排列进行编号
场景6:基于相邻单元的连接关系对单元和节点进行重新编号
场景7:载荷工况是标准化的include文件,要求网格文件中的加载点有确定的ID号
场景8:为各个include文件指定不重叠的id范围
场景9:没有include文件,但希望各个component的单元ID号放在规定的ID号范围内

名字
名字
场景1:增加/修改/删除asm/component/material/
prop名的字后缀或者前缀
Step 1
运行脚本syncTools8.tcl
Step 2
找到最后的工具并填写相应的后缀/前缀
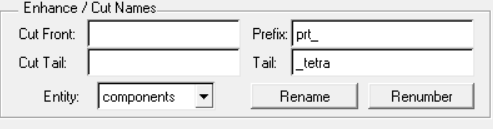
Step 3
点击rename并在弹出的界面下选中要修改名称的component,在model browser里面看到已经完成了名字的修改



思考题
思考题
思考
会写tcl脚本的同学可以想一想,如何避免对本来就是prt_开头的零件不追加前缀?
场景2:将prop的名字修改为component的名字,如果prop同时赋给了多个component,需要分别复 制一份
模型如下:

它们的prop都是同一个叫做frm的壳单元属性。
Step 1
运行脚本syncTools8.tcl
Step 2
找到工具
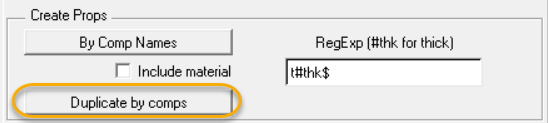
运行脚本后实现了属性按照零件进行分拆
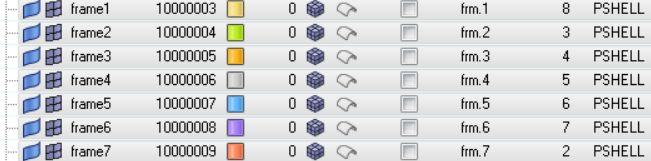
场景3:比场景2再进一步,把属性按照单元进行分拆
Step 1
先为每一个单元创建一个component,并将该单元move进去。
开始时模型是这样的一个component,只有一个属性frm

运行如下tcl命令,为每个单元创建一个component

运行结果如下:

接下来选中这些components,并把frm1属性赋给
所有选中的components,这在HyperMesh2017
版本中很容易实现。
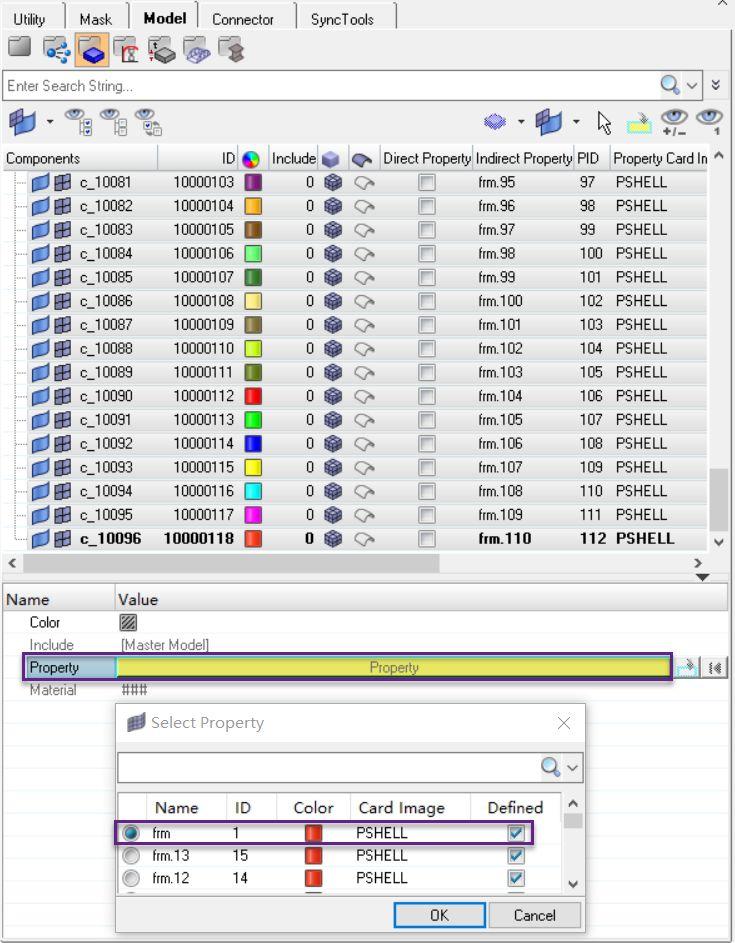
Step 2
运行脚本syncTools8.tcl中的功能后结果如下(只显示了一小部分)

ID
ID
名字是给人看的,而ID号基本上是给程序用的。
在开始正式介绍各种ID管理功能之前,先说一下控制ID号有什么应用上的价值。
1
方便选择
HyperMesh在选择对象的时候总是可以按照ID号进行选择,比如1-10000,选择后你可以复 制、移动、加载、创建几何等等各种操作。
HyperMesh支持各种书写方式,总的规则是由5个部分组成:
<start number> - <end number> by <increment value>
后面的4个部分都是可以省略的
-可以用through或thru或t简写
by可以写成b
以下是一些例子:
127
127 – 722
300 through 600
300 thru 600
300 t 600
1000 - 2000 by 100
1000 - 2000 b 100
另外,也可以使用英文的逗号将多个列表连接起来。
例如:
1, 3, 4, 5, 100
3, 5, 8 - 10, 800, 850
1 - 100 by 2, 77, 400 t 500 b 3
2
方便写脚本
大部分HyperMesh用户都是通过交互的方式使用软件,但是对于脚本开发人员来说很多时候在脚本运行期间需要通过命令自动选中需要的对象。
如果ID号的规律是事先知道的,那脚本中就不需要再处理ID号了。
3
模型的重用
如果ID号是彼此分开的,模型的网格和工况只需要通过include文件就可以实现重用。
场景4:把component的ID号改为属性的ID号(当然这就要求每个component有专属的属性,否则就会有ID号重复的错误了)
这个工具也是在这个脚本里面

结果如下:

除了以上功能该脚本还提供了很多别的功能 ⬇
01
同步HyperMesh数据库id和求解器id,二次开发的人会关心,主要是对显式分析求解器有影响,不搞二次开发的放心跳过。
02
各种rename功能,看名字就知道怎么用了

03
通过属性创建component

一个脚本不可能解决所有问题,如果你在实际工作中遇到其它类似的问题又没有解决方式,记得联系澳汰尔公司的技术支持。
场景5:按照空间位置进行编号。
这部分内容可以从帮助文件找到。用这种方法可以在用户定义的局部坐标系(笛卡尔坐标或柱状坐标)两个相互垂直的方向上对四边形单元或节点进行重编号。
使用该工具需要先把user profile选择为Aerospace

然后就可以在新增的Aerospace下拉菜单中找到Spatial ID manager

重新编码前单元的ID如下:
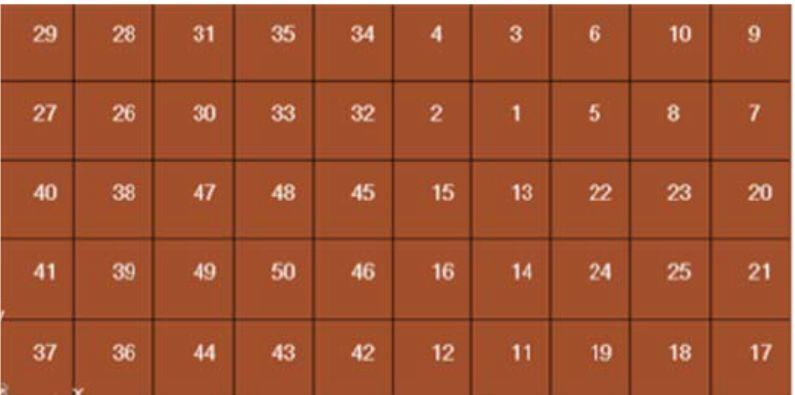
按坐标系重编号的步骤如下:
Step 1. 选择需要重新编号的一组节点或者单元;
Step 2. 选择局部坐标系;
Step 3. 在Start Id那栏填入一个数字ID编号,新编号范围不能与与现有的编号冲突;
Step 4. 指定第一根轴方向、容差和ID编号增量1;
Step 5. 指定第二根轴方向、容差和ID编号增量100。

Step 6. 点击Renumber单元重新编码后X增量为1,Y增量为100。
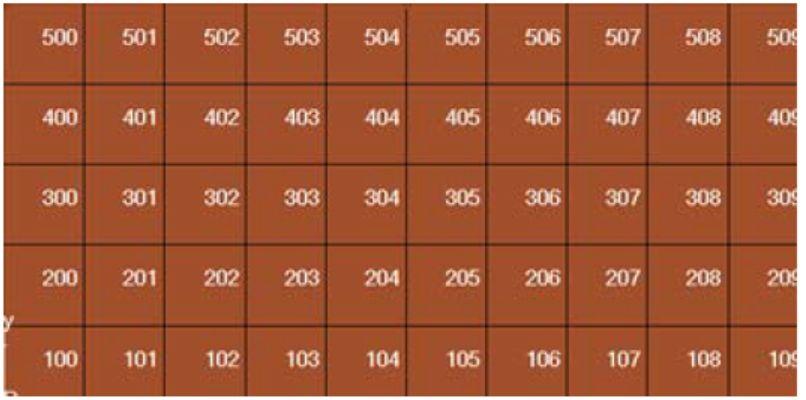
如果是回转结构,需要使用圆柱坐标系。
操作方法类似
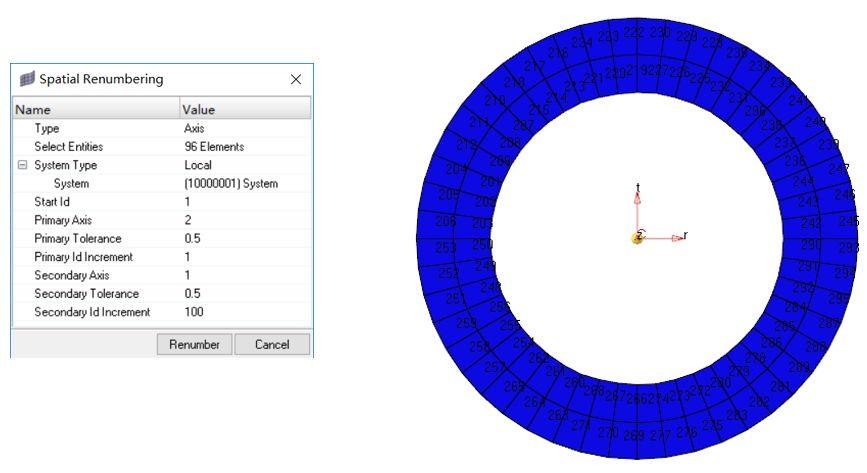
结果如下图:
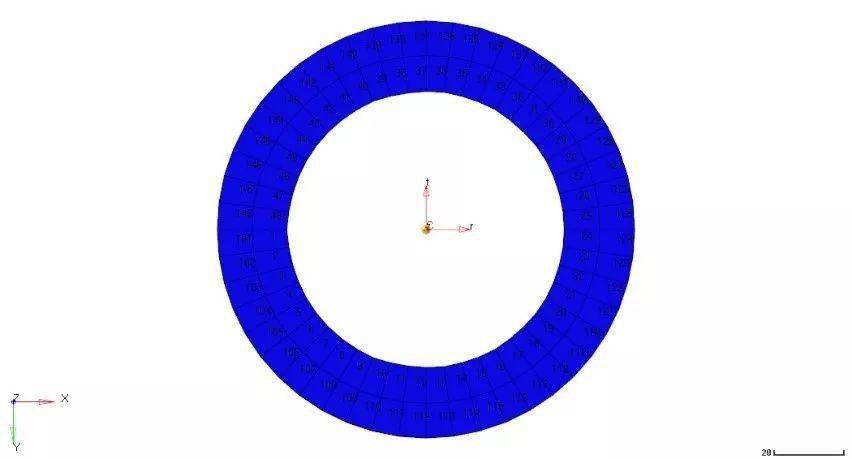
场景6:基于相邻单元的连接关系对单元和节点进行重新编号
有时单元和节点的重新编号是基于单元/节点的连接方向而不是局部坐标系方向。
这时场景5的方法就无法使用了。这时需要让HyperMesh根据单元的相邻关系来实现ID号的递增。用这种方法必须选择起始单元或节点和临近的连接单元或节点来指示第一方向和第二方向(类似于坐标系的原点/第一轴/第二轴)。
这些被重新编号的单元必须是彼此相连的,而且必须是映射模式的四边形单元。

操作过程如下:
1. 将类型(Type)选为Adjacent。
2. 为Select Entities指定单元或节点,输入Start Id即开始编号的数字。
3. 选择第一方向的单元或节点、指定ID编号增量。此时选择的单元或节点需要与起始的具有连接关系。
4. 选择第二方向的单元或节点、指定ID编号增量。此时选择的单元或节点也需要与起始的具有连接关系。

点击Renumber按钮实现单元(或节点)重新编号

说明:容差的设置对重新编号的影响
容差是用来将节点或单元组合起来,以得到正确有序的重新编号的一种方法。例如,你有一个简单的结构化网格,该网格在局部X方向上,节点间距为5mm,在局部Y方向上,节点间距为2mm。你想以101为起始编号,重新对节点进行编号。并且在局部X方向上,编号增量为1(例如101,101+1,101+2等等),在局部Y方向上,编号增量为10(例如101,101+10,101+20等等)。
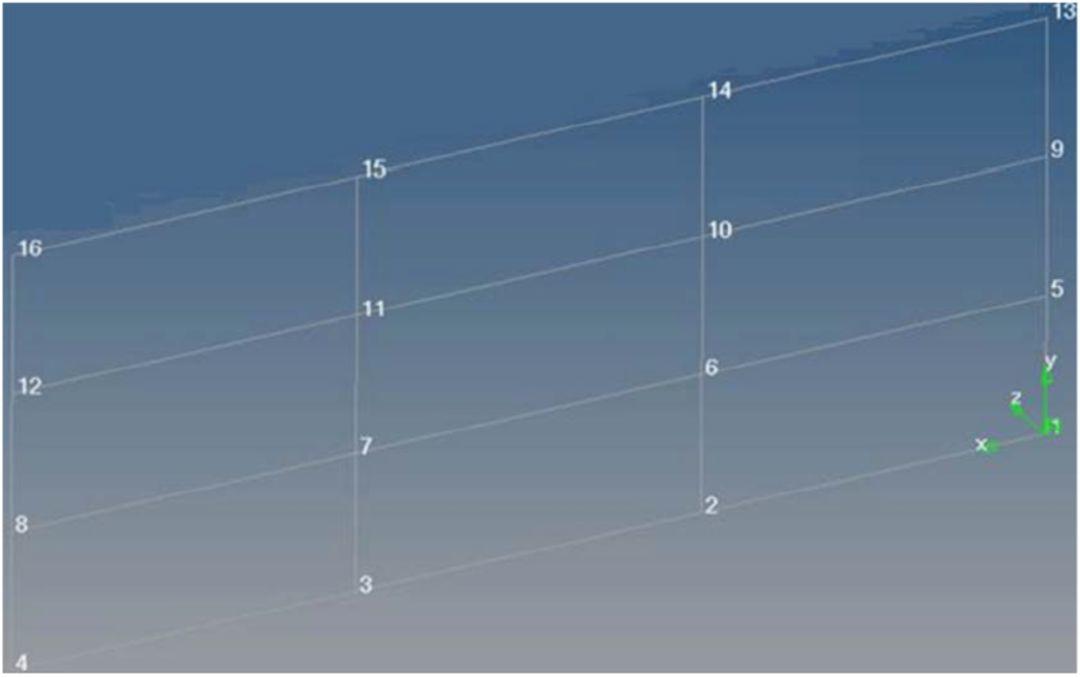
如果你用的容差为1mm(该值<5mm并且<2mm的节点间隙),重新编号结果如下:
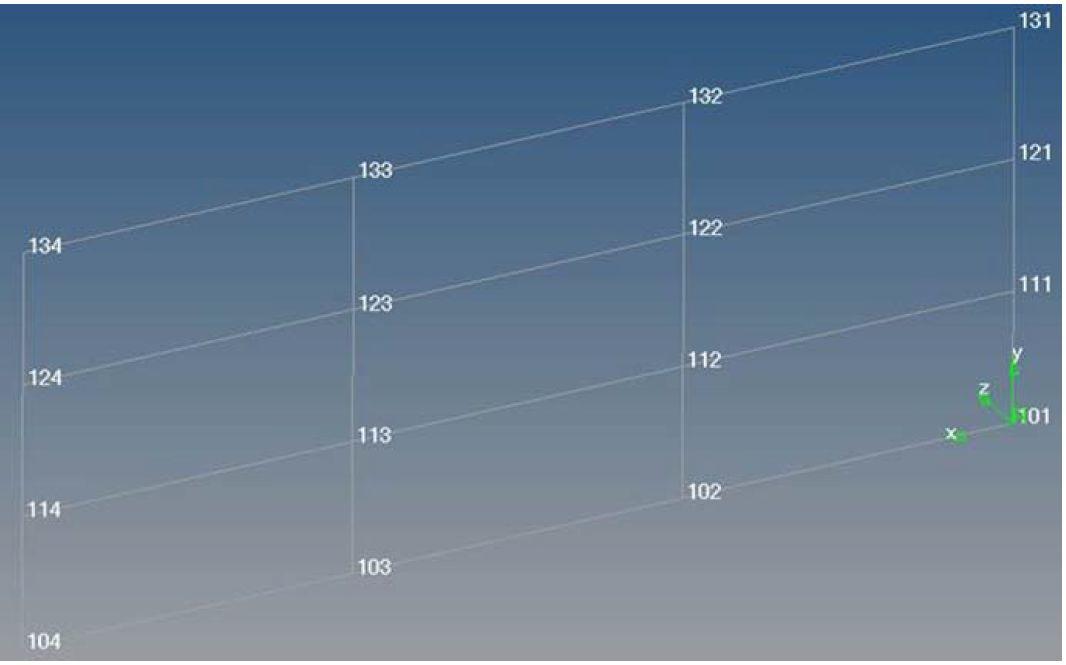
在实际场景中,很少能得到上述例子中那样的网格,因为通常节点间的间隙是变化的,会如下图所示。现在你想得到一样的重新编号,用了同样的容差(1mm)
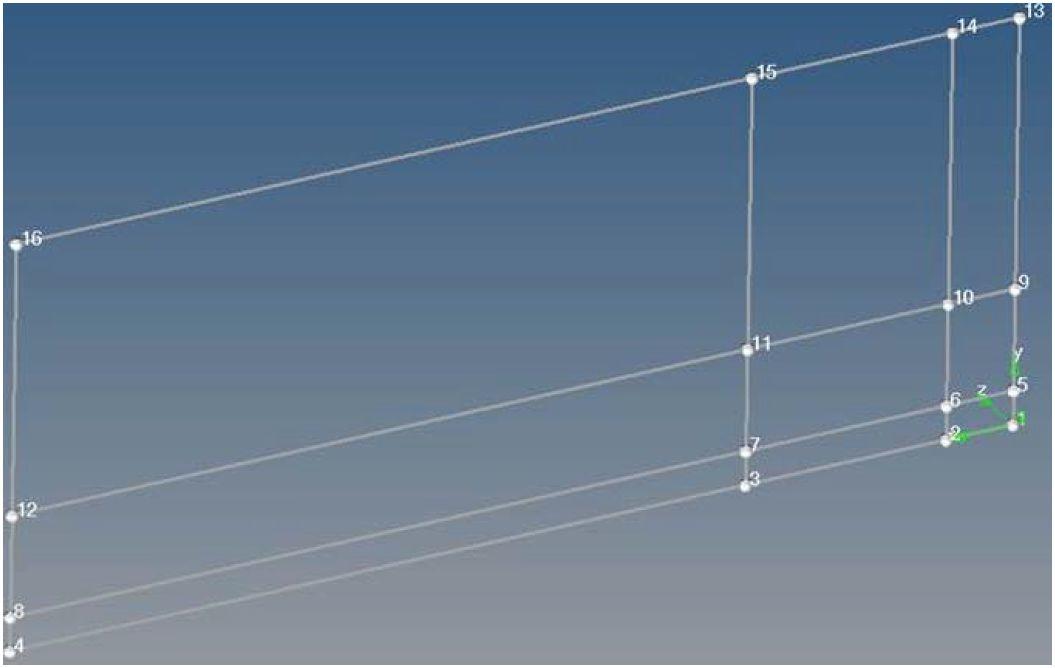
得到的结果会是这样的:

正如你在上图所看到的,重新编号的效果不符合预期。这是因为节点间的最小间隙是0.5mm,小于了1mm的容差。如果你将容差减小到0.1mm,就会得到正确的重新编号。
我们要介绍的最后一种ID管理工具ID manager,它可以规定每一个include文件的范围,锁定id,保留id给未来使用等,ID manager的界面如下:
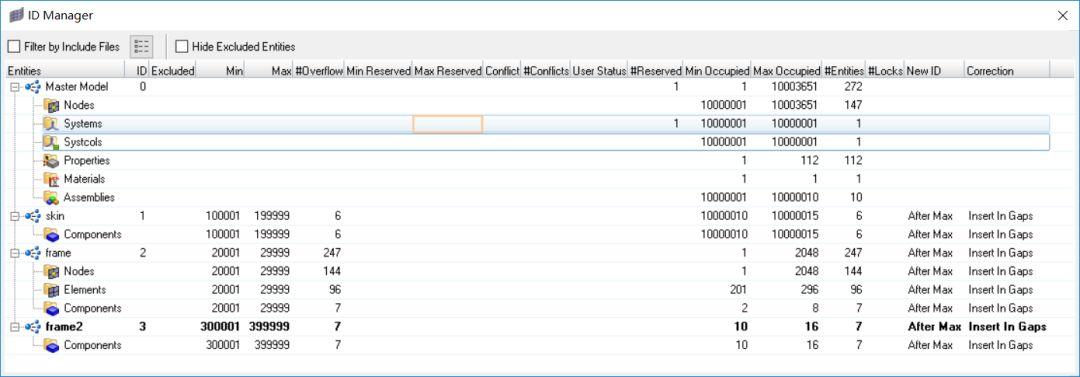
场景7:载荷工况是标准化的include文件,要求网格文件中的加载点有固定的ID号。
原始模型如下(只看最下面的4个加载点)

Step 1
先用renumber面版将4个加载点分别renumber到1000000,2000000,3000000,4000000

结果如下:

Step 2
打开ID Maganer,在node那一行右击选择
lock>Discrete IDs
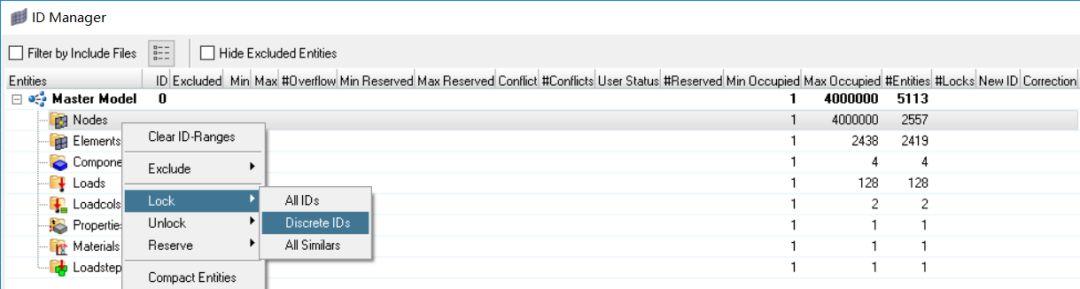
选择4个节点后,后面#Locks一列多了一个数字

这样这4个节点就不会受renumber操作的影响了,除非在相同的界面右击进行unlock。这样就可以放心大胆地把载荷工况做成固定ID号的include文件了。
场景8:为各个include文件指定不重叠的id范围。
目的是避免在导入的时候发生ID号冲突及自动renumber(HyperMesh会进行重新编号,把冲突的ID号放在当前最大ID号的后面)。
因为id管理经常和include文件一起出现,所以先介绍一下include文件的概念和基本操作。
include文件是为了方便对大模型的各个子系统分别进行创建和管理。比如汽车的底盘、车身、车门等子系统分别保存在各自的include中,载荷工况数据也可以保存在单独的include文件中,材料数据也可以是单独的include文件。

整车分析的时候只需要把各个子系统的include文件包含进来并进行连接(在整车模型中通常是在两个RBE2的独立节点之间创建cbush单元),然后再加上整车的工况include文件就可以进行整车级的分析了。
include文件格式和普通的求解器文件完全一致。顺便提一句,有限元中的include文件和c语言中的#include头文件是一样的。
例如python的c语言接口头文件是开头几行是这样的 ⬇⬇

意思是把后缀为.h的三个文件的内容粘贴到这里。编程文件的头文件可以进行任意级嵌套,有限元的include文件也是如此,只不过除非是超级复杂的装配模型,很少有人真的会去创建很多级的嵌套。
以下是一个简单的include文件例子。
有如下两个OptiStruct求解文件,其中input.fem是主文件(也就是提交求解的时候被选择的文件),sub2.inc是include文件,提交求解的时候只需要放在相应的目录即可。
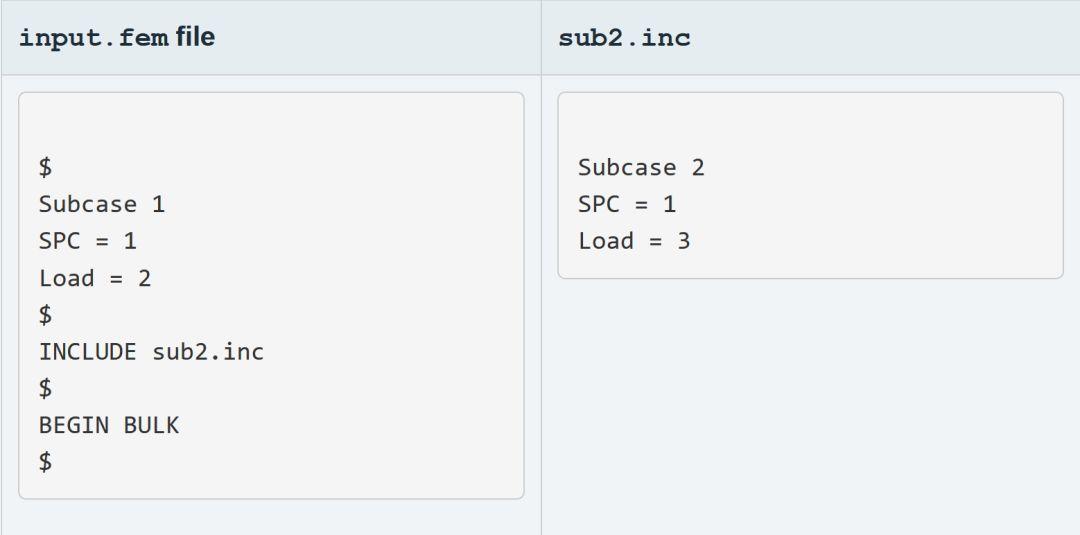
求解器实际读取到的内容相当于用sub2.inc的文件内容替代INCLUDE那一行

创建include文件在HyperMesh中只需要在model browser中右击并选择Create >Include File

将视图类型调整到include view

就可以编辑include文件的存放路径以及include文件的类型是模型/工况/IO了。
然后把要放入某一个include文件的对象用鼠标拖拽到include文件的名字上就可以了。

下例中已经把模型中的各个零件按照include文件进行了整理。
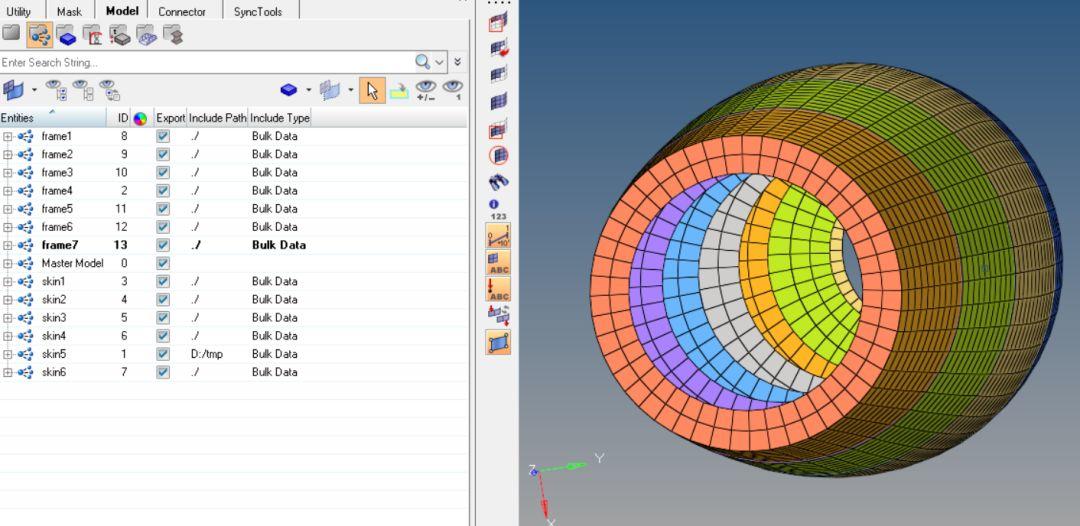
接下来为各个include文件指定不同的ID号范围(不允许有重叠)
Step 1
打开ID manager
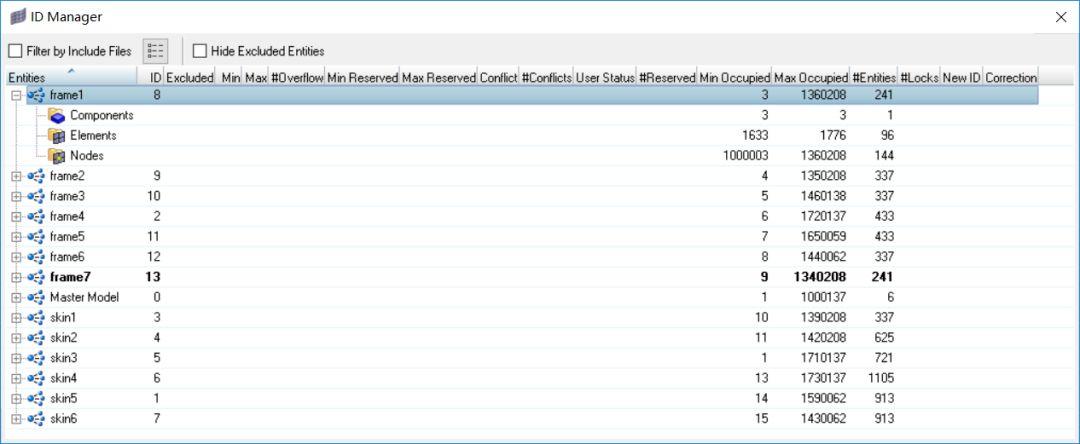
Step 2
依次右击每一个include文件,选择edit,在对话框中输入要求的id范围。如果现有的对象id有不在该范围的会出现在#Overflow列中。
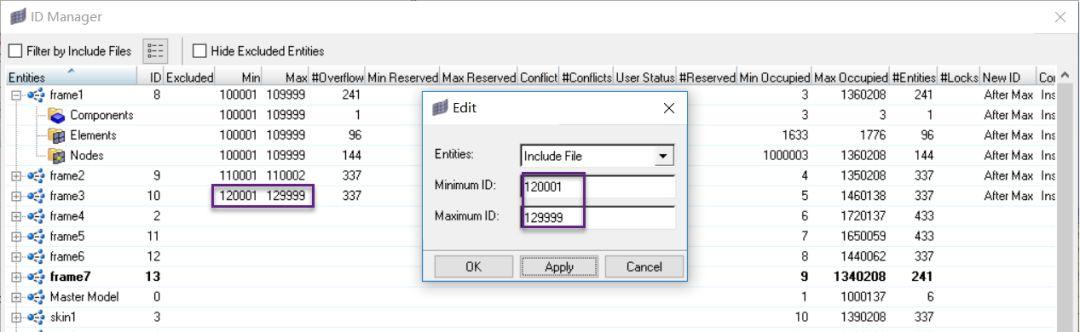
编辑后的结果如下:

Step 3
消除overflow
右击Correct overflow即可完成
完成后的id情况如下 ⬇

为了避免重复劳动,可以在空白处右键单击将所有id管理的信息导出到csv文件进行保存。下次直接导入csv文件即可完成ID号的设定。
更详细的ID Manager使用方法请参考帮助文件。
场景9:希望把各个component的单元ID号放在规定的ID号范围内,但是没有include文件。
如果可以使用空间某个局部坐标系将各个component区分开,可以使用前面场景5的方法,否则需要使用renumber面板进行多次renumber。
Step 1
将所有对象renumber到很大的ID号。目的是把后面步骤要用的ID段空出来。

Step 2
对每个component分别进行renumber(略)
如果,模型很小,这样的手工操作是可以的,如果零件数量很多,可以考虑写一个脚本

本文介绍的名字和ID都是很不起眼的工具,你可以完全忽略这些知识(你舍得么?),但是技多不压身,先收藏着也无妨,万一哪天发现需要了可以再翻出来看看呢是不?(真skr小机灵鬼~)
提醒


脚本有风险,使用前请先备份好原始模型。


