并行计算:并行编程模型、基础性能分析、基础性能优化
并行编程模型
并行与并发
并发:由一个处理器快速交替执行多个任务,只是看起来像在“同时执行多个任务”

图:并发计算流程图
并行:由多个处理器分别运行多个任务,各任务间严格同时执行。

图:并行计算流程图
进程与线程
什么是进程?
1. 程序运行的媒介,进程是动态的,程序是静态的;
2. 进程是操作系统进行资源分配和调度的一个独立单位;
3. 每个进程拥有独立的地址空间,地址空间包括代码区、数据区和堆栈区,进程之间的地址空间是隔离的,互不影响。
什么是线程?
1. 进程在运行过程中派生出的轻量级的单元,同一个进程中的多个线程共享进程的资源;
2. 可避免进程在创建、销毁与切换存在的较大时空开销问题。
计算单元的组织层次

图:计算单元的组织层次
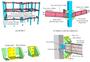
上图展示了并行计算单元的组织层次。一个CPU中有一个或多个ALU(算数逻辑单元),而在超算中,存在着多个CPU,这些CPU能够实现对大模型的并行数据处理。
并行计算可以简单的分为三类:节点间并行、核间并行和核内并行。节点间并行计算时内存是相互独立的;而核间并行计算时,内存是共享的;核内并行计算时就需要使用到向量寄存器。
浅谈MPI并行
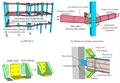
目前世界上主流的并行编程模型主要有三类:分布式共享(MPI)、共享内存式并行(OpenMP)、单指令多数据流并行(SIMD)。

图:MPI并行编程模型示意图

图:超算并行计算体系架构
分布式并行(MPI编程模型)本质上是实现进程级并行,即以进程为单位,可在不同节点之间同时计算子任务,但是进程不可见其他进程的内存数据。
MPI计算实例讲解

图:MPI并行编程模型计算实例
例如,需要计算一个反应堆的热耦合模型,MPI并行编程模型会先把模型平均切割为几个部分,每一个部分都会放到一个节点上计算,计算完成之后在对所有的数据合并,得到整个模型的数据。相比较于一个CPU内核计算一整个模型,多个核心可以一起计算数值模型,每个子模型的数据较少,这样就大幅度提高了计算效率。

图:MPI并行编程示例
浅谈OpenMP
共享内存式并行指的是线程上并行,这样的编程模型叫做openMP编程模型。指的是同一个计算节点内,不同的CPU核心同时计算,其计算的特点是以线程为单位的同时,可以在不同节点之间同时计算子任务,并且在同一个进程空间中共享数据。

图:OpenMP并行计算模型示例
浅谈SIMD

图:SIMD的向量化并行编程
单指令多数据并行编程模型,又称为SIMD,指的是同一CPU对向量寄存器中的多通道数据同时计算,这类技术充分利用了向量计算的并行化特征,实现了对大量数据的并行处理。
浅谈异构计算
对于超算平台来说,计算部件可以是多样化的,除了 CPU还有:GPU、MIC(Intel 集成众核)、主从核(神威)、Matrix2000(天河2A)等,一般统称为加速器(或加速核)CPU 和加速器在体系结构上是不一样的, CPU 协同加速器共同完成计算任务,称为异构(并行)加速器端也通常是线程级并行,有的加速器也支持跨部件进程间通讯,比如 GPU。

图:GPU加速器和Intel至强CPU
基础性能分析
程序流程分析
前面我们已经对算法和高性能程序的算法优化有了一些认识但实际中,一个程序的算法往往包含很多的步骤和计算,在优化程序前,我们往往需要先分析程序算法的流程,程序流程的分析方法主要分为静态分析和动态分析,静态分析的常用工具有understand,动态分析工具有gprof。
静态分析,即利用代码静态分析工具,对代码进行数据对象、函数接口封装和调用分析。静态分析的主要内容有:
1. 代码浏览和分析工具是基于各种编程语言语法,预处理和编译方式以及配置安装信息来有 组织有条理的显示代码源文件的工具
2. 借助代码浏览分析工具:
阅读和编辑代码;
在代码中进行检索;
了解代码的内层逻辑结构;
分析代码的语法结构等
常见的静态分析工具主要有:understand,source insight,DeepScan,VERACODE,deepsource等。

图:常见静态分析工具
程序流程分析 -- 静态分析
1. 使用understand创建代码分析项目工程
2. 使用understand浏览和在代码中跳转
3. 使用understand得到程序的整体执行流程 -- control flow
4. 使用understand得到某个函数接口的调用和主调关系 -- butter fly
5. understand项目高级配置 -- Project (Configure Project)
程序流程分析 -- 动态分析
动态分析是指在程序实际调用过程中去分析程序执行了那些函数和流程,由于代码往往包含了一个程序的多种功能,函数的定义包含重载等等,静态分析并不能完全知道我们的某一次执行实际执行的函数,而动态分析就是某一次执行的实际过程;Gprof 是一款比较易用的动态分析工具,除了函数的调用关系,同时还能给出 函数的调用时间分布,为我们的性能分析提供参考。
程序性能分析
gprof可以做程序的动态分析,作为性能分析的重要指标。gprof的结果文件主要包含两大部分内容——Flat profile(扁平化性能概括)和Call graph(调用图谱)。
Flat profile: 扁平化(性能)概况
扁平化性能概况不区分函数的调用关系,以程序中调用过的完整封装的函数体为对象,列出其执行时间、调用次数等作为性能描述。
Call graph: 调用图谱
调用图谱将程序中的独立函数体按照其实际调用过程,列出上下文调用关系,以列表的 形式给出来,通过辅助工具可以据此绘制出 程序的调用关系图。
程序性能分析 -- 结果详解

图:扁平化性能概况

图:调用图谱概况

图:生成调用结果图
程序性能分析 -- 手动测试
手动测试指的是手动的在程序中添加c/c++标准库中提供的计时函数(gettimeofday)对此程序速度进行统计。

图:手动测试函数案例图
程序性能分析 -- 小结
程序的性能除了调用时间外,是多方面的,主要有输入输出、计算性能两个方面:
• 输入输出: IO 性能 - - Input & Output
串行 IO
并行 IO
• 计算
1. 单核性能
• Cache 命中
• SIMD 水平
• 计算访存比
2. 共享存储式并行性能 - - OpenMP 并行性能
• 线程级扩展性
• 线程负载均衡
• 线程协同性(线程等待)
3. 分布式并行性能 - - MPI 并行性能
4. 混合并行性能 - - MPI OpenMP 混合并行
5. 异构并行性能
6. 分布式并行性能 - - MPI 并行性能
• 进程级扩展性
• 进程负载均衡
• 进程等待
• 通信开销占比
7. 混合并行性能 - - MPI OpenMP 混合并行
• 线程、进程搭配最优
• 负载均衡
8. 异构并行性能
• 异构数据传输开销
• 加速器端单核性能
• 加速器端并行性能
当然,除了gprof之外,还有很多的常用性能分析工具:

图:常见性能分析工具
Vtune
由Intel研发提供的程序性能分析工具,仅支持x86平台。
HPCToolkit、PAPI
一款开源的并行程序性能分析工具,支持多种平台, 高可移植性。
Paramon
Paramon软件是由北京并行科技有限公司研发完成的应用运行特征收集器,国产自主性能分析工具
Valgrid(内存泄漏)、strace、iostat、dstat、ping、gdb、top、htop、sar等等
Linux系统或内核性能分析工具
Perf
perf是Linux kernel自带的系统性能优化工具。优势在于与Linux Kernel的紧密结合,它可 以最先应用到加入Kernel的new feature,用于查看热点函数,查看cashe miss的比率,从 而帮助开发者来优化程序性能。
性能分析更好的工具
当然,还有分析性能更好的工具 — 支持内存调试、内存泄漏检测以及性能分析、检测线程错误的软件开发工具。
1. Memcheck
用来检测程序中出现的内存问题,所有对内存的读写都会被检测到,一切对malloc()/free()/new/delete的调用都会被捕获。所以,它能检测以下问题Paramon软件是由北京并行科技有限公司研发完成的应用运行
2. callgrind
和gprof类似的分析工具, 但它对程序的运行观察更是入微, 提供的信息更全面, 不需要 添加额外的编译选项。支持多线程。
3. Cachegrind
Cache分析器,它模拟CPU中的一级缓存I1, Dl和二级缓存,能够精确地指出程序中cache的丢失和命中。如果需要,它还能够为我们提供cache丢失次数,内存引用次数,以及每行代码,每个函数,每个模块,整个程序产生的指令数。这对优化程序有很大的帮助
分析实战 -- HPCG
HPCG程序背景简介
HPCG -- The High Performance Conjugate Gradients Benchmark,高性能共轭梯度 (HPCG) 基准项目旨在为 HPC 系统排名创建一个新指标,作为高性能 LINPACK (HPL)基准的补充,目前用于对TOP500 计算系统进行排名。HPL的计算和数据访问模式仍然是一些重要的可扩展应用程序的代表,但不是全部。 HPCG 旨在锻炼计算和数据访问模式,以更紧密地匹配不同且广泛的重要应用程序集,并激励计算机系统设计人员投资于对这些应用程序的集体性能产生影响的能力。
Top500 -- Benchmark

图:不同排行指标的Top500系列
基本概念
并行计算:Parallel Computing,是指同时使用多台计算机协同合作解决 计算问题的过程,其主要目的是快速解决大型且复杂的计算 问题(规模和速度);
理论浮点峰值:CPU主频× CPU每个时钟周期执行浮点运算的次数 × 系统中CPU数;
万亿次:1000GFlops,即1Tflops,更高的有Pflops等
HPL Linpack:国际上最流行的用于测试高性能计算机系统浮点性能的Benchmark测试方法;
TOP500:世界最快的500套系统排名,每年2次(6月、11月),在高性能业界两大大盛会ISC和SC大会公布
HPC China TOP100:中国最快的100套系统排名,每年1次(10月下旬),在中国高性能计算年会(HPC China)公布。
基础性能优化
从体系架构的角度

图:执行一次加法操作的计算耗时
针对以上的计算实例,常见的加快计算速度的有四种途径:
提高主频
高速缓冲存储器
流水线技术
并行技术
下面我们分别对四种加快计算速度的方法进行解读:
(1)提高主频

(2)高速缓存

如上图所示,高速缓冲存储器的存储结构是层次式的:
寄存器
• 逻辑运算内存单元
• 内存单位bit
L1 cache
• 速度最快,造价高
• 几十KB(64KB)
L2 cache
• 速度次之,造价次之
• 256K~2M
L3 cache
• 速度次之,造价相对便宜
• 几十MB(32M)
(3)流水线

(4)并行技术(超标量)

但是,我们同时也需要考虑所采用的技术措施是否是有效的,例如:
运算速度与主频是否成比例增长?
高速缓存的命中与否?
流水线操作能否维持不断?
并行操作是否等待别的输出?
如果想要充分利用流水和并行技术的优点,则需要满足——指令间没有相关,即相互独立:
结构相关:两条指令要用同一个不见
数据相关:一条指令要用令一条指令的结果
控制相关:条件转移指令影响其他指令
此外,存储器的供数率能否跟上也是一个值得思考的问题:
如果CPU消耗数据的速率远大于存储器供数率,会使得:时钟频率增长的速度大于访存时间缩短的速度,这就要求进一步提高同时执行多条指令的供数率,并且多线程或芯片内多处理器还要求访问多组数据。以上问题都会导致计算效率和算力的消耗。
已知的一个解决方案是:考虑存储器的层次结构。如片内cache的供数率能否满足指令级并行的要求?片内cache的命中率是否足够高?是否需要为多个线程或处理器提供各自的cache?如何通过程序或算法的改进增强访存局部性?
串行应用的改进 -- 体系结构考虑
尽量采用快速算法,如KRYLOV等;
仔细地研究编译器的优化功能和选项;
充分利用已经优化过的库函数:
1. 如BLAS等;
2. 如果可能,找或者编译适合自己需要的高效率库
基于cache和指令级并行做一些源程序级的优化
1. 最典型的一种优化:循环展开
2. 块方法、数组加边,为编译器优化程序提供更多的机会。
常见循环优化技术
局部性——locality
优秀的码农写出的程序通常都具有较好的locality。
局部性可以分为时间局部性和空间局部性。
时间局部性:指的是同一份数据在短时间内往往会被多次重复 使用。比如说如果我们读取了一个数据a,那么接 下来一段时间我们很有可能会不断访问这个数据a。
空间局部性:指的是如果我们访问了某个数据,那么我们往往也需要访 问它附近的数据。比如说如果我们访问了一个数组里元素 a[1],那么接下来很有可能会访问a[0]或者a[2]。
cache结构
cache主要是由一个一个的cacheline堆叠而成,catch满了之后就需要整行替换cacheline。这样的间隔访问很容易导致cache miss。即访问1,随后访问9,9肯定不在cache里。

图:cache和cacheline示意图
常见循环优化技术
以下列举了常见的循环优化技术:
• 循环合并
• 循环展开
• 循环交换
• 循环分布
• 循环不变量外提
• 循环分块
• 循环分裂
下面分别对常见的循环优化技术进行讲解:
循环合并(loop fusion)
将具有相同迭代次序的两个循环合并成一个。

图:循环合并示意图
优点:
减少循环迭代的开销
增强数据重用,寄存器重用
减小并行化的启动开销
循环展开(loop unrolling)
是一种牺牲程序长度来加快程序执行速度的方法。可以由程序员完成,也可以由编译器自动完成。

图:循环展开示意图
优点:
减少循环指令分支的次数
获得更多的指令级并行
增加了寄存器的重用
循环交换(loop interchange)
当一个循环体中包含一个以上的循环,且循环语句之间不包含其它语句,则称这个循环为紧嵌套循环,交换紧嵌套中两个循环的嵌套顺序是提高程序性能最有效的变换之一。实际上,循环交换是一个重排序变换,仅改变了参数化迭代的执行顺序,但是并没有删除任何语句或产生任何新的语句,所以循环交换的合法性需要通过循环的依赖关系进行判定。

图:循环交换
优点:
增强数据局部性
增强向量化和并行化的识别
循环分布(loop distribute)
循环分布是指将一个循环分解为多个循环,且每个循环都有与原循环相同的迭代空间,但只包含原循环的语句子集,常用于分解出可向量化或者可并行化的循环,进而将可向量化部分的代码转为向量执行。

图:循环分布
优点:
将串行循环转变为多个并行循环
实现循环的部分并行化
增加循环的优化范围
缺点:
减小了并行粒度,增加了额外的通信和同步开销
循环不变量外提
循环不变量是指在迭代过程中不发生变化的量。由于不发生变化,可以将循环不变量提到循环外面,避免重复计算。

图:循环不变量外提
优点:
减小循环内的计算量
循环分块
循环分块是指通过增加循环嵌套的维度来提升数据局部性的循环变换技术,是对多重循环的迭代空间进行重新划分的过程。在计 算机存取数据,需要从主存将数据取到寄存器中,这一过程为了 是数据存取更有效率,在主存和寄存器中会存在一个高速缓存Cache,缓存常用的数据,但存储量很少,通常当某个数据现在被用过以后,后面还会被用,但是按循环默认的执行方式,可能到 下次再被用到的时候就已经从高速缓存行Cache中被消除了,于是 重排循环,减少内层循环的迭代量,使得一个cache line在被消除 之前会被再次使用。

图:循环分块示意图
特点:
A[i] 在每一轮j循环中被重用
B[j] 当M数值比较大时,无法全部缓存在cache里。所以当i进入到下一层循环时, B[0]已经被清出cache,无法重用。
假设cache line大小为b。理想情况下,则可计算出A的cache miss次数是N/b ,B的cache miss次数是N*M/b
分块j层循环,将B的访问模式变成如下,令块大小为T,T一般是b的倍数,也足够小,可以认为N,M >> b,T,T的取值应该使得当B(T)被访问时B(1)也依然还在缓存中
分块j层循环的时候,分块后以后j层循环就跑到了外层,这样又会影响A的缓存命中率。我们可以计算此时A的cache miss次数是(M/T)*(N/b),B的cache miss次数是T/b * M/T = M/b(每一轮J层循环miss一次),所以总共的cache miss是 MN/(bT) + M/b,tile之前是N/b+N*M/b。所以在M和N的大小也相当的情况下做j分块大约能将cache miss缩小T倍。
循环分裂
循环分裂是将循环的迭代次数拆成两段或者多段,拆分后的循环不存在主体循环之说,也就是拆分成迭代次数都比较多的两个或者多个循环。

图:循环分裂示意图
优点:
增加向量化可能