一文读懂Fluent并行计算,三大技术提升计算效率新境界!

作为流体仿真软件的“顶流”,Fluent被学生、工程师及科研人员广泛使用。随着技术的不断进步,Ansys工程师们致力于优化底层的并行算法,以提升其计算性能,使用户体验飞一般的计算速度。

在Ansys Fluent中,尽管工程师已经针对并行算法进行了充分优化,但在实际应用中,还有其他方法可以进一步提高计算性能。本文阐述了Fluent并行计算的基本原理,同时探讨通过AVX2指令集加速、GPU加速以及超线程等技术手段来提高计算效率。
01
什么是Fluent并行计算
Fluent的并行求解器通过协同运作多个进程来计算大型问题,这些进程既可以在同一台机器上运行,也可以在网络中的不同设备上运行。
并行求解器将计算域分为多个区域(图1),将各数据分区分配至不同的计算进程(称为计算节点,图2),每个计算节点都在其专属数据集上同步执行同一程序。主进程(或称为主机)不包含网格单元、面或节点(除非使用 DPM 共享内存模型),其主要职责是解析 Cortex(负责用户界面和图形相关功能的 Fluent 进程)发送的指令,并将这些指令(及数据)传递给某一计算进程,再由该计算进程将其分发至其他计算进程。
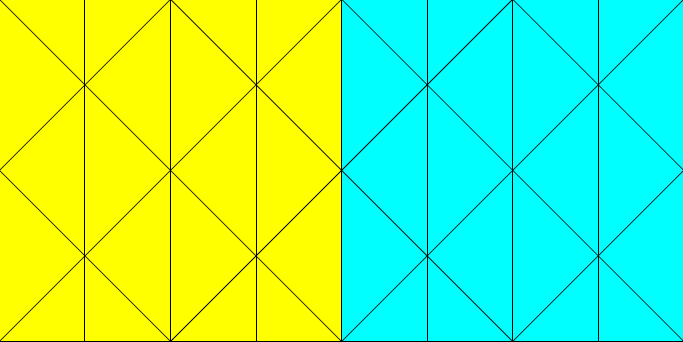
图1:计算区域分区
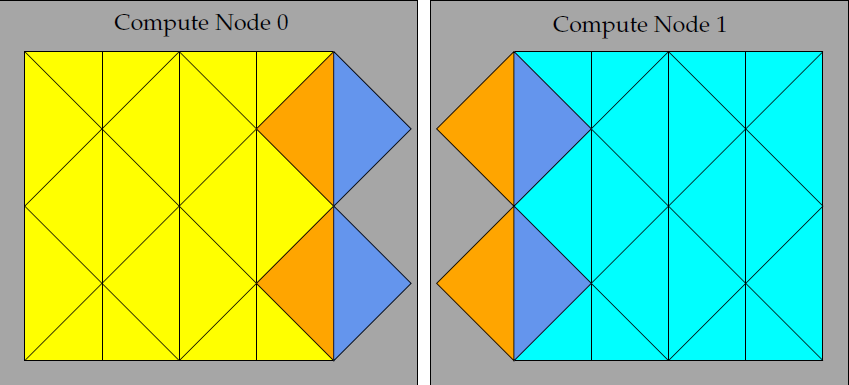
图2:分区网格边界
计算节点负责存储并执行部分网格的计算任务,而位于分区边界的单层重叠单元格层则负责跨分区边界的通信(图2)。尽管单元格和面被分割,但网格中的所有域和线程在每个计算节点上均存在镜像(图3)。线程以链接列表的形式存储,和串行求解器保持一致。计算节点可在大规模并行计算机、多CPU 工作站或具备相同或多工作站组成的网络上实现。[1]
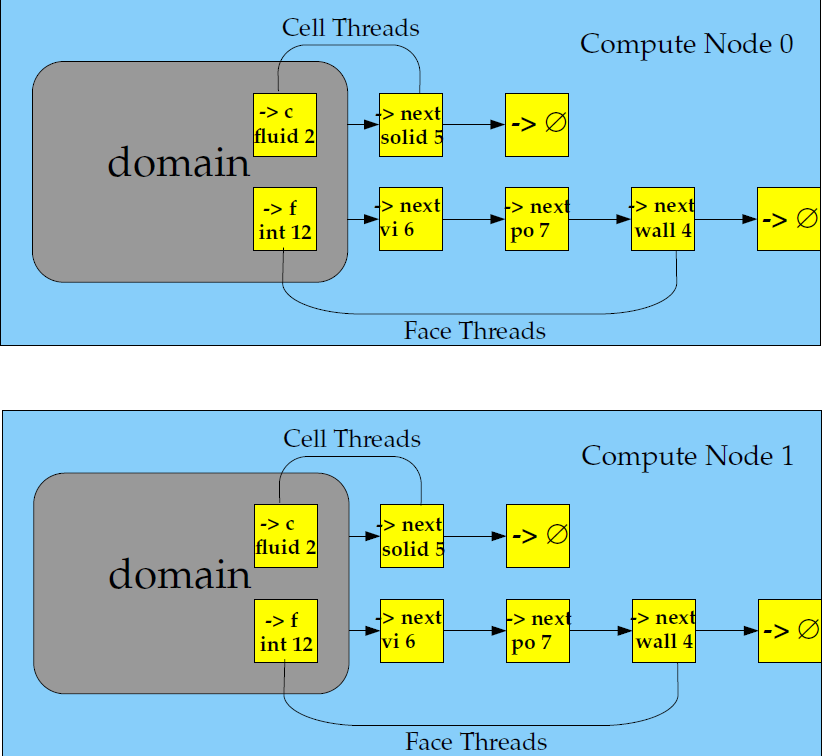
图3:分布式网格中的域和线程镜像
命令传输和通信
在Flunet并行计算会话中,进程涉及的主体包括 Cortex(主机进程)和一组 n 个计算节点进程,这些计算节点由 0 到 n-1 进行标记(图4)。主机进程接收来自 Cortex 的命令,并将命令传递至node-0,再由node-0发送给其他计算节点,所有计算节点(不包括节点0)均从node-0 接收命令。在计算节点将指令发送至主机之前(通过node-0),它们会相互进行同步。
各计算节点之间会进行“虚拟”连接,并依赖其“通信器”来实现数组的发送与接收、同步、全局约简(如全体单元的求和)以及机器连接性构建等功能。如图4 所示,Flunet 通信器可视为一个消息传递库,作为Message Passing Interface (MPI) 的标准供应商。
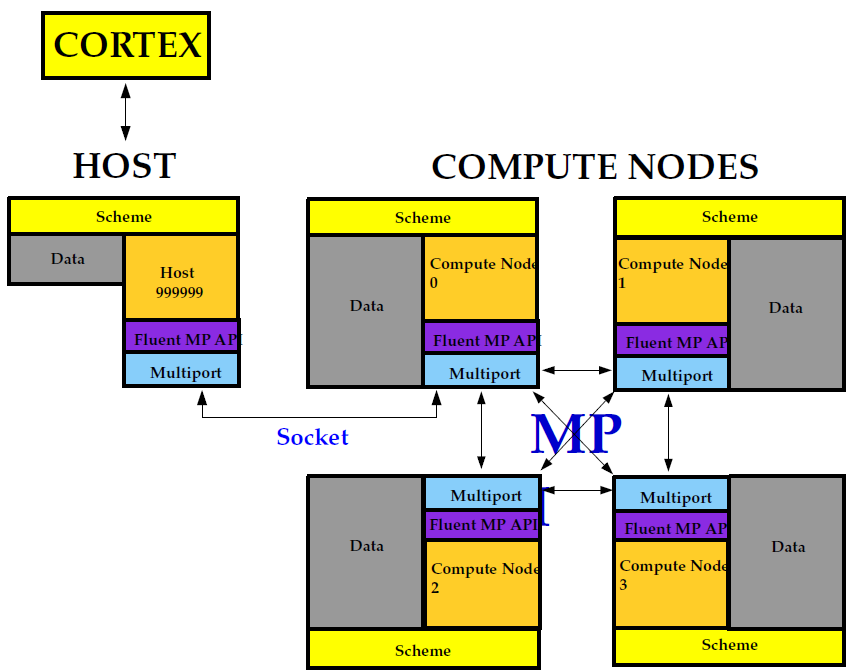
图4:Fluent并行架构
在并行Flunet进程中,每一个进程(以及串行进程)均拥有独一无二的ID标识。其中,主进程被分配为 ID node_host(=999999)。主机负责从 node-0 获取消息,并对所有数据执行相应操作(如打印、显示信息以及写入文件等),这与串行求解器的操作方式保持一致(图5)。
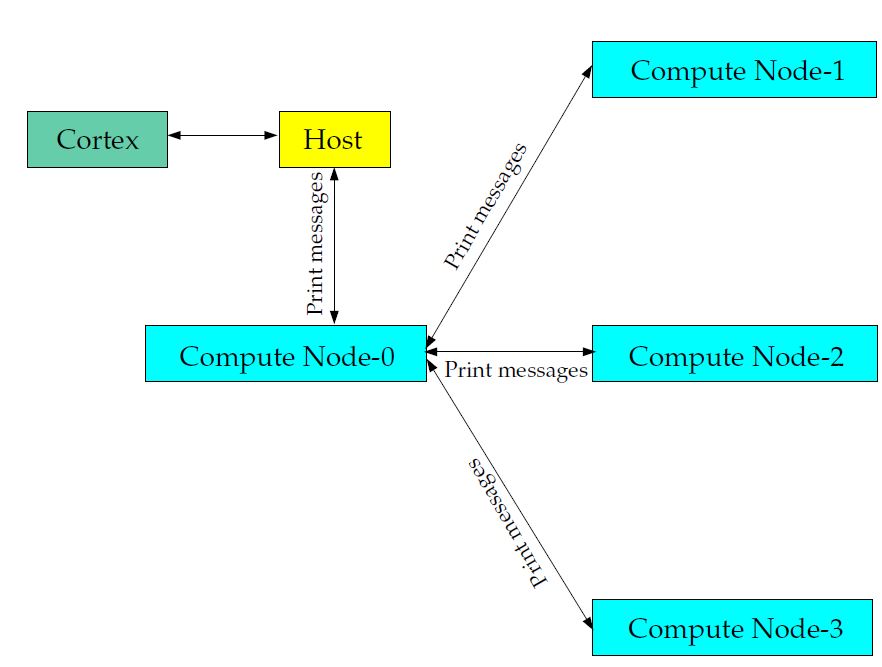
图5:Fluent并行流程
当然,由于商软黑箱,我们做不了太底层的事儿,但是在能力范围内,也能为提高计算效率添砖加瓦。
02
通过AVX2指令集加速
AVX2(Advanced Vector Extensions 2)是英特尔推出的一种SIMD(Single Instruction, Multiple Data)扩展指令集,旨在提高处理器的并行计算能力。作为AVX指令集的升级版,AVX2具有更多的指令和功能。
AVX2指令集引入了256位宽的矢量寄存器YMM和一系列新型指令,能够同时对8个32位或16个16位整数进行并行计算。相比于之前的SSE指令集,AVX2在处理器上的计算任务执行数量更多,数据吞吐量更高。在科学计算、图像处理、物理模拟等领域,AVX2具有广泛的应用价值。借助AVX2指令集,程序可以充分发挥处理器的并行计算能力,加速执行更加复杂的计算任务。需要注意的是,为了充分发挥AVX2的优势,硬件环境须支持该指令集,因此,我们务必确保所选择的处理器和计算节点可支持AVX2指令集,才可享受AVX2带来的性能提升。
在Fluent环境中实现AVX2加速的方法相当简单,只需在启动指令中添加一个参数即可:
-platform=intel## use AVX2 optimized binary. This option is for processors that can support AVX2 instruction set
在Linux操作系统下,针对MPI并行模式的脚本可参照以下,具体根据实际环境调整相关变量:
#!/bin/bashexport HOST_FILE=$(/opt/hpc/slurm/21.08.6/bin/generate_pbs_nodefile)cat ${HOST_FILE} > .nodelistNODELIST=""for host in `cat $HOST_FILE | uniq`doif [ -z ${NODELIST} ]; thenNODELIST="['$host',$SLURM_NTASKS_PER_NODE]"elseNODELIST="$NODELIST,['$host',$SLURM_NTASKS_PER_NODE]"fidone#cat > fluent.env << !mp_host_list=[$NODELIST]!$INSTALL_DIR/bin/fluent -g $PRECISION -t $cpus -mpi=intel -platform=intel -ssh -cnf=${HOST_FILE} -i ./$jouFile
我们搭载AMD EPYC 7H12处理器,在神工坊高性能仿真平台上对算例进行了系列测试,以下为测试结果:
根据上述结果可以明显看出,AVX2指令集具备加速性能,尤其在较小规模下,加速效果更为显著。然而,随着并行规模的扩大,加速比例逐渐降低,这可能是由于并行计算存在固有的开销,从而降低了加速比例。当然,其他因素也可能影响结果。首先,硬件适配问题不容忽视,本次测试采用AMD设备,而AVX2指令由Intel开发,因此可能会存在适配问题。在Intel设备上进行重新测试,或许能获得更佳的结果。其次,软件版本也可能影响性能。使用最新版本的软件能够享受到更多的优化和改进,从而提高性能。此外,本次测试的算例亦可能存在问题,本次测试采用simple分离求解法的900w网格旋转机械算例,使用其他算例或许能得到不同的结果。
03
GPU加速
Fluent GPU求解器是由NVIDIA开发的并行计算平台和应用程序编程接口(API) CUDA(计算统一设备架构)驱动,因此,GPU求解器只支持NVIDIA的GPU,包括大多数NVIDIA Tesla和NVIDIA Quadro系列的GPU,以及Ansys网站罗列的可支持的部分GPU。
事实上,尽管使用GPU加速的用户相对较少,但在Fluent早期版本就已具备该功能。启用GPU加速十分简单,仅需在启动界面进行选择。对于耦合求解器,Fluent默认使用GPU加速来进行耦合求解,并采用基于克罗内克子空间迭代法的FGMRES算法(弹性广义最小残差求解器)。然而,对于分离式求解器,默认情况下并未使用GPU加速(即使在启动界面开启也没有效果),需要通过命令进行单独设置,具体操作步骤如下:
1.首先,在启动界面选择调用GPU的数量(根据电脑的实际配置进行选择)
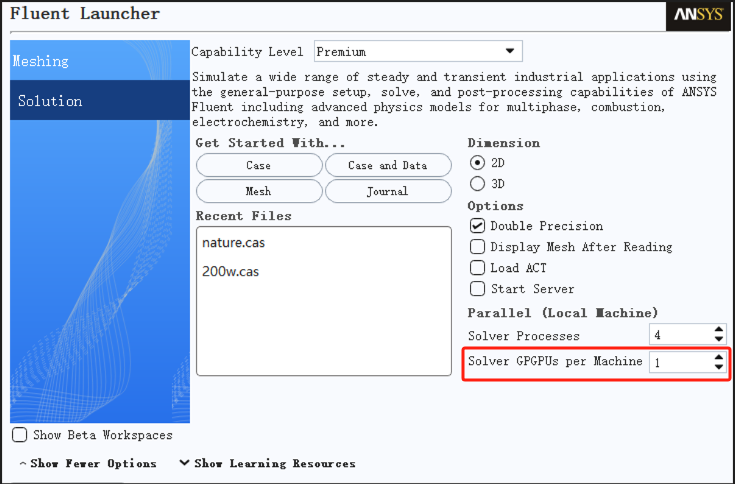
图6:Fluent启动界面
2.进入软件工作台界面后,在右侧命令端输入“/parallel/gpgpu/show”,即可显示当前使用的GPU型号,若GPU后方显示“*”,则表示GPU已被选用;若无“*”标识,可输入“select”,根据序号选择所需计算的GPU。
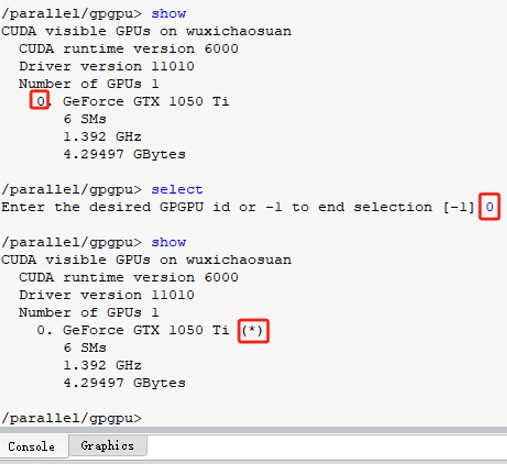
图7:命令终端选择GPU
3.成功选择GPU后,在终端键入“q”直至返回最外级选项。接下来选择需要GPU求解加速的量,输入“/solve/set/amg-options/amg-gpgpu-options”将会弹出当前算例所需求解的量。
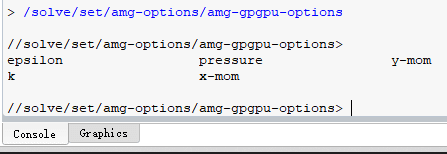
图8:命令终端选择加速量
4.若需加速x方向动量,则键入“x-mom”,随后弹出选项选择“y”,其余参数保持默认即可,其他加速项操作同理。

图9:命令终端选择加速x方向动量
我们在 Intel Core i7-13700F 上搭载 NAVIDIA GeForce RTX 3060 对couple耦合求解算例进行测试,结果如下:
测试过程如图10所示,可以看到满状态下,CPU和GPU负载均较高,这表明加速效果显著。然而,如果算例配置需求过高,可能导致显存不足,进而引发软件崩溃,如图11所示。

图10:GPU计算过程
图11:内存不足奔溃
根据ANSYS官方资料,Fluent在GPU上的运行速度最高可提升至3.7倍(即提升270%),实际测试数据也证实了这一可能性。而且,在开启GPU加速的情况下,2线程的耗时仅为16线程不使用GPU时的40%,当然这种情况与CPU和GPU型号搭配有很大关系,搭配不佳可能导致性能受限。我们发现,8线程下的计算耗时优于16线程,这可能是因为16线程CPU多核心之间通信时间增加导致整体效率下降。综合以上来看,最佳计算线程数应在12左右。CPU线程数并非越多越好,它存在最优线程数,相关文献已对此进行研究[2]。在16线程情况下,由于远程控制操作计算,进程任务包括计算任务、远程控制任务及系统本身任务,这将会降低计算效率,因此,在大多数情况下,留出1、2个进程给系统等任务可能会带来更好的性能。
04
超线程加速
超线程(Hyper-Threading)是Intel研发的一项技术,它通过在单个物理处理器核心中模拟出多个逻辑处理器,使其并发执行多个线程。超线程技术的核心优势在于提升处理器的并行度和资源利用率。
通过模拟多个逻辑处理器,超线程能够在同一时间周期内执行多个线程,进而有益于多线程应用程序和并行计算任务,提高系统响应速度与整体性能。此外,超线程技术还有助于减少资源闲置时间。当一个线程需要等待某些资源时,另一线程可以继续使用其他可用资源,从而降低等待时间与资源浪费。
然而,超线程技术也存在一定局限性,因其并未实质性地增加处理器核心的数量,只是通过逻辑模拟来实现多个线程的同时执行。因此,在某些情况下,多线程可能会竞争相同的物理资源,导致性能下降。此外,超线程技术的实际效果与应用程序特性和线程调度密切相关。对于某些特定类型的应用程序,超线程技术可能无法带来显著的性能提升。对于高度并行化的任务,超线程可能会带来更大的性能提升。
我们在Intel Xeon Platinum 8358机器上使用神工坊高性能仿真平台对某一算例进行了扩展性测试,仍选择物理核心的方式进行对比,以下为测试结果:
我们可以发现,开启超线程能带来一定程度的性能提升,但提升比例相对较低,因此,在实际计算中,是否启用超线程需根据实际情况来权衡。如果您的工作负载高度并行,且能够充分利用每个物理核心,那么开启超线程技术可能会带来显著的性能提升。然而,如果您的应用程序比较依赖单个线程的执行速度,则开启超线程可能会导致性能下降,原因在于超线程会使每个物理核心上的线程数增加,从而增加了上下文切换的开销。另外,还要考虑芯片功耗与散热问题,开启超线程会增加处理器的热量和功耗,如果散热性能不佳或处理器功耗已接近极限,开启超线程可能会导致处理器过热并降低系统稳定性。
总体而言,超线程技术在适当情况下可提升处理器的性能和资源利用率,但实际效果取决于应用程序的特点和线程调度策略。开启超线程需要综合考虑多个因素,如应用程序类型、并行程度、功耗和散热等。在选择处理器时,需要综合考虑应用场景和性能需求,评估超线程技术对系统性能的实质影响。
05
总结
通过以上内容,我们可知:
1. AVX2指令集加速有显著效果,计算性能最高可提升8.63%,建议搭配Intel的机器。
2. GPU加速效果显著,但其与CPU和GPU的协同作用密切相关。
3. 超线程技术在Fluent计算中具有一定的提速效果,但需兼顾芯片功耗和散热问题。
4. 系统任务对速度提升会产生影响,建议在计算过程中空出1、2个进程。
“神工坊”高性能仿真平台基于超算HPC集群的硬件支撑,对仿真软件进行了CPU平台的高性能适配与优化,同时根据用户需求进行兼容性适配,力保每一核都能发挥出它的最大价值,欢迎广大仿真从业者注册试用!
参考资料
[1]《Fluent UDF手册》
[2] Ju T, Wu W, Chen H, et al. Thread count prediction model: Dynamically adjusting threads for heterogeneous many-core systems. IEEE, 2015: 456-464.


