多尺度(multiscale)理论与计算方法前沿研究分享

编织复合材料的非线性力学行为的并发三尺度方案Fe-SCA2
摘要:
对具有复杂微观结构的编织复合材料的力学行为进行有效和准确的多尺度建模是复合材料力学中的一个突出挑战。在这项工作中,提出了一个并发的三尺度方案FE-SCA2,用于预测与微观塑性和成分损伤相关的编织复合材料的宏观非线性行为,其中FE和SCA分别是有限元方法和自洽聚类分析的缩写。在该并行方案中,编织复合材料的宏观行为由有限元分析处理,成分的微观和中尺度行为由SCA处理,同时进行数据驱动的聚类离散化。为了证明所提出方案的 准确性和有效性,我们首先预测了编织复合材料的不对称各向异性屈服面和失效面,然后分析了编织复合板在弯曲下的非线性行为。将计算结果与有限元方法的结果和文献中的实验数据进行了比较,在这些数据可用的情况下,计算结果具有良好的一致性。结果表明,使用所提出的FE-SCA2可以同时捕捉编织复合材料的微观、中尺度和宏观非线性行为,这将难以用实验方法进行表征。所提出的多尺度方法可用于具有各种微观结构和成分特性的复合材料结构,以加快设计和结构优化。

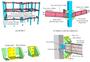
图:编织复合材料的自然多尺度特性。

图:编织复合材料并发三尺度模拟的计算挑战。

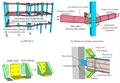
图:微型纱线RVE的聚类结果。

图:中尺度编织 RVE 的聚类结果。

图:编织复合材料的同时三尺度FE-SCA2方案示意图。

图:高纤维体积分数UD-RVE的随机算法。

图:三维编织复合材料的中尺度RVE。

图:正应力空间中的预测屈服面和破坏面。

图:三维编织复合材料弯曲试样的几何形状。

图:编织复合材料在弯曲条件下的并发三尺度模拟。
文二:

高速冲击载荷下脆性和韧性断裂的统一弹粘塑性近场动力学模型
摘要:
近场动力学(PD)作为经典连续介质力学的一种替代形式,是预测裂纹自发萌生和扩展的一种强大方法。本文提出了一个统一的弹粘塑性近场动力学模型,称为基于Bodner-Partom理论的近场动力学(BPPD)模型,用于描述脆性和韧性材料在冲击载荷下的整个变形损伤断裂过程。它通过将Bodner-Partom(B-P)本构理论纳入基于常态的PD框架来定义键向弹粘塑性变形。在BPPD模型中,结合改进的B-P理论,将键劣化作为本征变量引入,并通过临界键拉伸模型实现键断裂。所提出的BPPD模型允许塑性变形和材料退化的自然发展,这与PD理论有着相同的观点。本研究配备了弹性短程力接触模型,进一步研究了BPPD模型在各种冲击载荷下的建模能力。对脆性落球试验、泰勒冲击试验和弹道侵彻试验的模拟结果与实验数据吻合较好。所提出的BPPD模型能够准确地捕捉各种冲击断裂的整个变形过程,从而为PD理论的发展提供了新的多样性,为理解材料断裂机理提供了新视角。

图:(a) PD短程相互作用(b)PD离散化PD离散化和接触模型的说明。

图:BPPD模型的数值实现流程图。

图:应变率效应试验的试样几何形状。

图:玻璃板的断裂程度。

图:冲击杆在不同时间步长的塑性变形。

图:弹道穿透过程中的损伤模式示意图。
文三:

基于 NTFA 的面向目标的自适应时空有限元求解微观非均匀弹塑性问题
摘要:
在这项工作中,我们建立了一类耗散非均质材料的目标定向时空有限元方法。这些材料在微观和宏观尺度上建模,体积平均型的尺度转换满足Hill–Mandel条件。为了简化模型,对微观非弹性应变场进行了非均匀变换场分析。简化变量是从这些非弹性应变场的时空分解中推导出来的。由于一些耗散因素,导出了闭合形式的本构关系,从而导致了一个降阶均匀化问题。由此产生的模型误差对于所考虑的材料类别来说足够小,因此将有限元方法的离散化误差作为主要误差源。为了便于误差估计,我们将降阶问题改写为多域公式。基于对偶技术,从拉格朗日方法导出了一个时间上向后的对偶问题,给出了用户定义的感兴趣量的误差表示。结合补丁恢复技术,开发了一种可计算误差估计器来量化空间和时间离散化误差。通过定位技术,使用局部误差估计器在空间和时间上驱动贪婪自适应细化算法。通过几个关于原型模型的数值算例验证了算法的有效性。

图:一个两尺度问题的例证。

图:NTFA的数值实现。

图:纤维增强复合材料RVE的有限元离散化(1672个单元)。

图:由纤维增强复合材料制成的穿孔片材。

图:示例1: 初始网格的双重解决方案及其增强版本。

图:示例1: 用于参考解决方案的离散化。

图:示例2:初始网格上的双重解决方案。
文四:

基于位错本构模型的典型BCC金属在冲击载荷下动态屈服应力温度相关性的数值研究
摘要:
解释冲击载荷金属动态屈服应力的温度依赖性最近成为冲击波物理学中的一个关键问题。然而,由于缺乏对BCC金属在高应变速率和高温下的本构行为的准确描述,很少研究BCC金属动态屈服应力的温度相关性。为了揭示BCC金属在这种极端条件下动态屈服应力的潜在机制,我们建立了一个基于位错的本构模型,其中从耗散能的角度提出了位错生成方程。当应用于冲击加载的BCC金属时,该模型定量再现了在预热板冲击实验中观察到的弹塑性波特征,即使在>1000K的温度下也是如此。研究发现,热激活均匀成核(TA-HN)引起的森林硬化是钒在高温下热硬化行为的主要因素,而Peierls应力是其他BCC金属热软化行为的主要影响因素。这项工作的新颖性在于,森林硬化机制作为一种塑性硬化机制,通常被认为对BCC金属的温度不敏感,由于TA-HN在高应变速率和高温下对位错运动有显著影响,因此已被证明对温度敏感。基于这一机制,我们还预测,在超过现有实验极限的温度范围内,其他BCC金属,如钼和钨,也会发生热硬化行为。

图:平板冲击实验和多晶体模型示意图。

图:钒的实验与模拟比较。

图:计算的动态屈服应力的温度相关性和实验结果的比较。

图:RSS和CRSS在不同温度下的计算时间历程:(a)钽;(b) 钒。实线表示CRSS的时间历史,而虚线表示RSS的时间历史。不同颜色的线条表示不同的温度。
文五:

建立一个统一的非局部近场动力学框架,用于带裂缝的分子动力学数据的粗粒化
摘要:
分子动力学(MD)已成为设计材料的有力工具,减少了对实验室测试的依赖。然而,直接使用MD在中尺度上处理材料的变形和失效在很大程度上仍然遥不可及。在这项工作中,我们提出了一个学习框架,从MD模拟的材料断裂数据集中提取近场动力学模型作为中尺度连续体的替代品。首先,我们开发了一种新的粗颗粒化方法,以自动处理MD位移数据集中的材料断裂及其相应的不连续性。受加权本质上无振荡(WENO)方案的启发,关键思想在于一种自适应程序,自动选择局部最光滑的模板,然后将粗粒材料位移场重建为包含不连续性的分段光滑解。然后,基于粗粒度MD数据,提出了一种基于两阶段优化的学习方法来推断具有损伤准则的最优近场动力学模型。在第一阶段,我们从没有材料损伤的数据集中识别最优非局部核函数,以获取材料的刚度特性。然后,在第二阶段,从具有裂缝的数据中学习材料损伤准则作为平滑的阶跃函数。结果,得到了一个近场动力学代理模型。作为一个连续体模型,我们的近场动力学代理模型可以用于进一步的预测任务,与训练的网格分辨率不同,因此与MD相比,可以大幅降低计算成本。我们通过对单层石墨烯中动态裂纹扩展问题的几次数值测试来说明所提出方法的有效性。我们的测试表明,所提出的数据驱动模型是稳健和可推广的,因为它能够在不同于训练期间使用的离散化和加载设置下对裂缝的初始化和生长进行建模。

图:粗粒化方法的一个例子。

图:四个数据集在零温度下的典型MD模拟中的示例U1位移轮廓。

图:在时间步骤20、30和40处,根据断裂训练数据集的MD数据集的预测和地面实况测量的比较,其中石墨烯片受到零体力。

图:在具有精细网格的骨折训练数据集上,在时间步骤20、30和40处对来自MD数据集的预测和地面实况测量进行比较,其中石墨烯片受到零体力。