英伟达的检索增强生成应用程序ChatRTX (V0.2.1)
摘要
英伟达推出的ChatRTX是一款演示应用程序,它通过RAG、TensorRT-LLM和RTX加速,将大型语言模型与用户计算机中的内容连接,创建自定义聊天机器人,快速回答上下文相关问题。它支持多种文件格式,安装需满足特定条件。ChatRTX提供两个模型,用户可本地选择并查询文档。测试表明,Mistral 7B模型在提供信息方面表现更佳。尽管作为Demo版本,ChatRTX在处理文件数量和功能上受限,但仍是一个提高工作效率和知识管理便捷性的强大工具。
正文
1. 引言
英伟达在今年年初推出一款演示应用程序ChatRTX,可以将GPT大型语言模型(LLM)与计算机中自己的内容(文档、笔记或其他数据)连接起来,利用检索增强生成(RAG)、TensorRT-LLM和RTX加速,自定义一个聊天机器人,快速获得与上下文相关的答案。ChatRTX 支持多种文件格式,包括文本、pdf、doc/docx 和 xml。
对于本地文档,理论上讲,假如ChatRTX做得足够好,而且坚持不断改进,那么我们以后就不再需要Ollama【Ollama本地运行的实践---离散断裂网络DFN】。
2. 安装ChatRTX
安装ChatRTX并不是一件容易的事情,必须满足以下4个硬性条件:
(1) Windows平台,ChatRTX不支持其他操作系统,而且必须是Windows 11;
(2) 必须使用英伟达的显卡,至少是RTX30或RTX40,而且显存至少8GB;
(3) 内存至少16GB;
(4) C:盘空间至少预留50GB。
在满足以上条件后,从英伟达网站上下载安装软件包ChatWithRTX_installer_3_5,这个文件的尺寸为36.2GB,解压后的尺寸为39.6GB,目前的版本是3月27日更新的(ChatWithRTX_installer_3_27_patch_v2),解压后的文件如下图所示。
执行setup.exe开始安装程序,这是一个非常漫长的过程,而且一次很难安装成功,因为受到两个因素的影响,一个因素是在安装的过程中需要下载大量额外的数据,另一个影响因素是国内线路的问题。如果足够幸运的话,安装成功的界面如下图所示。系统安装了两个模型,一个是Llama2 13B,另一个是Mistral 7B。(1) Llama 2由Meta Platforms公司发布,该模型基于2万亿个标记进行训练,默认支持 4096的上下文长度。Llama 2聊天模型在100多万个人类注释的基础上进行了微调,专为聊天而设计。Llama 2共有3个子模型,分别是7B,13B和70B,可能是目前的机器配置还不是最高,因此只能下载我们以前使用的13b【Ollama本地运行的实践---离散断裂网络DFN】。(2) Mistral 是一个7.3B参数模型,由Mistral AI发布,据称Mistral 7B在所有基准测试中均优于 Llama 2 13B,优于 Llama 1 34B,在代码方面接近 CodeLlama 7B 的性能,同时在英语任务方面表现出色。不过我们目前在ollama中还没有与Llama 2进行真实的比较。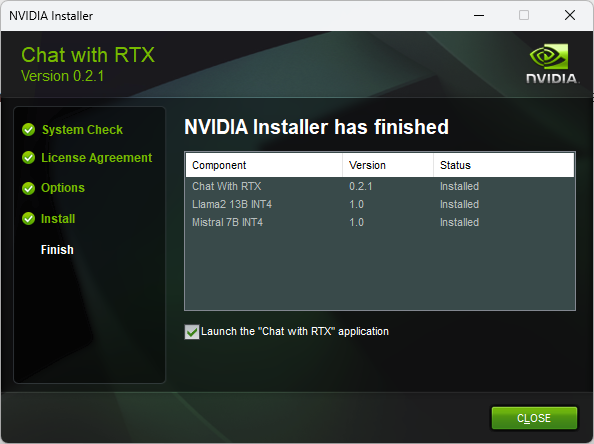
3. 启动ChatRTX
安装完成后,会在桌面上添加一个图标"NVIDIA Chat with RTX",点击这个图标便会启动ChatRTX。启动程序后,首先会运行并且显示配置文件,这个配置文件应该能够修改,不过在目前的初识阶段让其以默认方式运行即可。(1) 没有发现sentence-transformers模型UAE-Large-V1,使用 MEAN池创建一个新的;
(2) 从dataset_vector_embedding中使用持久值;(3) ./config/preferences.json 文件不存在。显而易见,ChatRTX采用了sentence-transformers预训练模型来寻找句子的相似性,这是一个我们以前大量使用的库。SentenceTransformers库更新V2.0.0
可能的原因是这个库需要从HuggingFace上下载,而HuggingFace现在对模型下载提出了极高的要求,记得3年前使用HuggingFace上的模型可以随意下载。消除这个警告信息的一个方法是从国内的镜像网站上下载这个模型,然后放到警告信息中指定的文件夹内,不过目前还没有这样做,似乎不影响程序运行,背后的原理不甚清楚。接下来便会呈现出本地服务器页面:http://127.0.0.1:xxxxx/,界面非常简洁,左侧选择安装的模型Mistral或Llama,如下图所示。
右侧指定文件的路径,如下图所示。在文本输入框内输入要查询的句子,按"Send"按钮即可。

4. 测试ChatRTX
下面以F:/search下的文本来测试ChatRTX。这个目录下共有570个txt文件,既有岩石力学方面的,也有土力学方面的,总的文件尺寸为15.4M,系统分7次生成嵌入,花费了大约3分半时间。输入的问题是"list some open pit mines",我们试图从这些文档中查出一些露天矿的名称。首先使用默认的LLama 2 13B模型进行查询,给出的结果是:(a) 美国内华达州的Betze-Post金矿 - 北美最大的露天金矿之一,年产黄金超过100万盎司。
(b) 西澳大利亚的Boddington金矿 - 澳大利亚最大的金矿,年产黄金超过70万盎司。
(c) 澳大利亚Kalgoorlie的Fimiston Open Pit "Super Pit" - 澳大利亚最大的露天金矿之一,开采深度超过 600 米。
(d) 加纳的Ahafo金矿 - 位于非洲多产金矿地区的露天金矿,年产黄金超过 50万盎司。
参考文件为"露天开采的金矿.txt"
(2) Mistral 7B模型
其次,使用Mistral 7B模型进行同样的提问"list some open pit mines",结果如下:
(a) Betze-Post mine in Nevada, USA
(e) Carlin Trend mines (Nevada, USA)(f) Yanacocha mine (Peru)(g) Veladero mine (Argentina)【维拉德罗金矿(Veladero Gold Mine)露天开采 (山东黄金)】(h) Rosia Montana mine (Romania)(i) Olimpiada mine (Russia)(k) Martabe mine (Indonesia)值得注意的是,墨西哥总统最近提议禁止在墨西哥进行露天开采,因为露天开采会破坏环境和过度用水【墨西哥禁止露天采矿 | 对赣锋国际的影响】。
参考文件为"露天开采的金矿.txt"
如前所述,Mistral 7B模型确实比Llama 2 13B模型提供了更多的信息【最新统计53个 | 世界上开采最深的露天矿(开采深度大于400m)】。
5. 结束语
ChatRTX目前的最新版本是3月27日的V0.2.1,鉴于这是个Demo版本,因此无论文件夹下有多少个文件,它一次只能处理一个文件,即首先找出与提示词语义上最相近的那个文档,然后再根据这个文档进行处理,例如:[1] Bench stability analysis using DFN in open-pit mines -> stability analysis of Delabole Slate Quarry.txt[2] summarize the application of DFN in open-pit mimes -> DFN.txt[3] settlement calculation of the foundation -> random limit equilibrium models equivalent shear strength heterogenous weak rock masses.txt



