中科院一区Top开源代码推荐|用于跨机器工况下故障诊断的深度判别迁移学习网络

迁移学习是当前故障诊断领域的研究热点,然而针对其开源代码较少,小编整理搜集了一些开源代码与大家进行分享。本期分享的是用于跨机器工况条件下故障诊断的深度判别迁移学习网络,该论文是重庆大学钱泉博士于2023年发表在中科院一区Top期刊Mechanical Systems and Signal Processing上的,并提供有该作者原创的开源代码和北交何超博士复现的pytorch框架代码,因此这篇开源代码适合参考借鉴并在上面进行改进学习,适合具备一定的深度迁移学习基础知识的学习者。
该方法是用多个轴承数据进行跨设备的智能诊断,很贴合实际工程应用场景,非常值得阅读!
1 论文基本信息
论文题目:Deep discriminative transfer learning network for cross-machine fault diagnosis
论文期刊:Mechanical Systems and Signal Processing
Doi:https://doi.org/10.1016/j.ymssp.2022.109884
论文时间:2023年
作者:Quan Qian, Yi Qin, Jun Luo, Yi Wang and Fei Wu
机构:
State Key Laboratory of Mechanical Transmission, Chongqing University, Chongqing 400044, People’s Republic of China; College of Mechanical and Vehicle Engineering, Chongqing University, Chongqing 400044, People’s Republic of China
第一作者简介:钱泉,重庆大学机械工程专业博士研究生,中共党员,重庆大学在校生最高荣誉——学生年度人物获得者,长期从事于机械装备故障诊断与预测性维护,共发表国际知名SCI论文15篇,其中以一作发表中科院一区9篇、中科院二区1篇、IF>10高水平论文3篇,谷歌学术累计被引380余次,累计影响因子110+;已经申请发明专利14项,其中以学生一作授权中国专利4项、公开中国专利5项和英国专利1项。
2 摘要
目前,研究者已经提出了很多用于解决目标域和源域之间的分布对齐和知识迁移问题的领域自适应方法。然而,大多数研究方法只关注到边缘分布对齐,忽略了目标域和源域之间判别性特征的学习。因此,在某些案例中,这些方法仍然不能很好地满足故障诊断要求。为了提高分布一致性,并且对齐两个域的边缘分布和条件分布,我们提出了一种改进联合分布自适应(Improved Joint Distribution Adaptation, IJDA)机制。在该方法中,我们将最大均值差异和相关对齐(Correlation Alignment, CORAL)方法相结合,作为一个新的分布差异度量方法用于提高分布的一致性。在此基础上,提出了一种改进的条件分布对齐机制。另外,我们提出了一种新的I-SoftMax损失,该损失相比原始SoftMax损失具有更强的分类能力,可以帮助网络学习到更多可分离的特征。我们利用IJDA机制和I-SoftMax损失,构建了深度判别迁移学习网络(Deep Discriminative Transfer Learning Network, DDTLN)来实现迁移故障诊断。基于没有标签的目标域样本,我们对六个跨机器诊断任务进行实验,证明该方法与其他典型的域自适应相比,具有更高的迁移故障诊断性能。
3 目录
4 引言
由于工业大数据和测量技术的快速发展,前沿的故障诊断和预测算法引起了许多研究人员的关注。由于深度学习方法不依赖人为经验,因此基于深度学习的故障诊断方法成为近五年来的研究热点。然而,在实际工程领域中,获取足够的标签是极其困难的,这意味着深度学习模型的鲁棒性和泛化能力无法得到有效的保证。另外,深度学习的诊断模型要求训练数据集和测试集满足相同概率分布。然而,旋转机械由于工作载荷、传递路径、噪声干扰、故障程度甚至复杂的机械结构等因素的影响,必然会产生显著的分布差异。
为了解决上述问题,迁移学习(Transfer Learning, TL)被提出,首先它减少目标域和源域之间的分布差异,然后将从有标签的源域中学习到的知识共享到有少量标签或没标签的目标域。域自适应(Domain adaptation, DA)减小了目标域和源域分布的差距,并学习域不变特征。主流的深度DA机制可以分为基于对抗的机制和基于统计度量的机制。例如,研究者提出了深度域混淆(Deep Domain Confusion, DDC) [6]和深度自适应网络(Deep Adaptation Network, DAN)[7]来执行具有最大平均差异(Maximum Mean Discrepancy, MMD)距离度量的跨域图像分类任务。深度相关对齐(Deep correlation alignment, DCORAL) [8]也获得了比典型协方差方法更好的结果。受生成对抗网络(Generative Adversarial Network, GAN)的启发,Ganin等人[4]提出了一个域识别器来区分源域和目标域。然后,通过特征提取器和域混淆器之间的对抗学习来实现域混淆。在故障迁移诊断领域,Long等人[9]采用三层稀疏自动编码器网络和MMD度量对西储大学(Case Western Reserve University, CWRU)轴承数据集进行故障诊断。为了进一步增强域混淆能力,作者[11]通过结合对抗机制和距离度量来提高不同负载下的迁移诊断准确率。针对各种类型的迁移任务,基于DA的方法可以分为部分域自适应[12]、闭集域自适应[13]、开集域自适应[14]、通用域自适应[15]、源域和目标域中的多对一域自适应[16]以及源域和目标域中的一对多域自适应[17]。例如,为了执行轴承和齿轮的部分迁移诊断,Li等人[12]提出了一种新的权重选择对抗网络。他们构造了一个辅助神经网络来获得源域样本和目标域样本的实例权重的网络。Zhang等人[15]建立了一种深度混合加权DA机制来诊断轴承故障,其中源域标签空间和目标域标签空间之间的先验关系是未知的。Chai等人[16]提出了一种多域精化迁移学习网络,通过权值选择机制从多个域中获取目标域对应的共享类,打破了每个源域的标签空间与目标域相等的假设。
尽管上述基于DA的方法在多个领域和迁移任务中取得了很好的结果,但是他们忽视了两个重要因素。首先,他们仅仅关注目标域和源域边缘分布对齐(Marginal Distribution Alignment, MDA),而忽略了两域中对应类别的条件概率分布(Conditional Distribution Alignment, CDA)。Long等人[18]提出了包括MDA和CDA的联合分布,用来提高DA能力。然而,将类别条件概率分布近似替换条件概率分布一定程度影响了域混淆的能力。其次,分类迁移任务的目标是获得判别性且域不变特征。然而,几乎所有的DA模型主要考虑域不变的特征学习,同时忽略了判别特征学习。由于噪声干扰等因素的影响,故障传递函数比较杂乱,不利于故障的迁移诊断。因此,在DA中,我们更需要可区分的特征学习机制(判别性特征学习),也就是要求较小的类内距离和较大的类间距离。
在可区分特征学习中,相关工作可以被分为两个方面:损失函数的设计和网络架构。例如,Liu等人提出L-SoftMax和A-SoftMax通过将原始欧式距离特征空间映射到角空间来调整所需的边缘。然而,由于余弦函数的非单调性,优化是极其困难的。Wu等人设计了一种包括两个分类器的新网络架构,以通过最大分类器差异(Maximum Classifier Discrepancy, MCD)对抗机制获得更好的识别性能。
考虑到现有CDA机制的近似性,我们提出了一种新的CDA机制,以更好地对齐两个域的真实的概率分布。改进后的CDA机制与 MDA机制相结合构成了IJDA机制。 为了从均值和协方差两个方面更好地度量分布距离,设计了一种结合MMD和CORAL的改进度量,进一步减小了分布差异。 为了学习更多可分离的故障特征,提出了一种新的具有灵活裕度的I-Softmax损失,使迁移框架在跨机器迁移诊断任务中具有更好的诊断能力。
5 所提方法
5.1 DDTLN框架
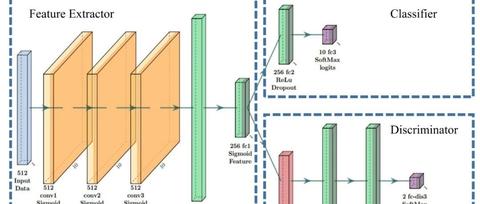
所提出的DDTLN的结构绘制在图1中。该框架包括五个一维卷积模块、一个全局平均池化(Global Average Pooling, GAP)层和两个全连接(Fully Connected, FC)层。每个“Cov1D”块由卷积层、批归一化(Batch Normalization, BN)层和最大池化层组成。GAP和BN可以加速网络收敛,减轻过拟合现象。

图1 DDTLN的网络结构;右箭头和左箭头分别表示前向传播和反向传播
表1 DDTLN的详细参数

为了克服方程中CDA近似的负面影响,我们提出了一种改进的CDA机制来对齐两个域中的条件概率分布。使用贝叶斯定理,条件概率分布可以转换为类条件概率分布的形式,其表示为:
5.4 优化目标
5.4.1 IJDA损失
在所提出的IJDA损失中,我们提供了改进的联合域自适应机制。此外,根据信号的正态分布特性,将MMD和CORAL相结合,实现了域混淆。IJDA损失方程中,目标域样本的标签信息由伪标签近似获得。通过IJDA损失对DDTLN进行优化后,得到的特征具有域不变性。另外,DDTLN可以直接通过梯度反向传播和链式法则进行优化。最后,对应于网络参数
通常,分类交叉熵损失被应用于有标签的源域以用于学习区分性特征。为了在TL任务中学习更多可分离的特征,通过伪标签将I-Softmax损失应用于目标域样本。因此,全部分类损失界定为:
6 实验
在本章节使用三个数据集的完成跨机器诊断任务来验证所提出DDTLN模型的有效性。我们将在下面对三个数据集的具体细节进行介绍:
(1)CWRU:CWRU数据集由Case Western Reserve University收集,在轴承诊断案例中被广泛认为是基准数据集。它的实验平台包括驱动电机,加载电机,一个扭矩传感器,一个功率计和几个测试轴承。总共模拟四种负载:0 hp,1 hp,2 hp和3 hp。在轴承测试过程中,采集了包括正常状态(NC)、内圈故障(IF)、滚珠故障(BF)和外圈故障(OF)四种故障类型的原始振动信号。加速度传感器的采样频率设定为12000 Hz。
(2)RTS:RTS数据集是根据RTS转子动力学试验台建立的,RTS转子动力学试验台是定制的实验平台。RTS数据集的故障类型类似地由NC、IF、BF和OF组成。该试验台的结构由伺服电机、联轴器、轴承、两个转子和传感器组成。原始振动信号由放置在右轴承座上的CMS无线传感器收集。模拟包括0 kN、1 kN、2 kN和3 kN载荷以收集足够的原始振动信号,采样频率设定为8 000 Hz。轴承的输入转速为1000 r/ min、2000 r/min和3000 r/min。
(3)SWJTU:SWJTU轴承数据集由西南交通大学收集。SWJTU数据集的测试台由三相电机、两个轴承、加速度计和加载系统组成。故障类型也与CWRU和RTS轴承数据集相同。试验台还可以采集不同负载下的原始信号。加速度计的采样频率为10000 Hz。输入转速设定为896 r/min。
在本章节使用三个数据集的完成跨机器诊断任务来验证所提出DDTLN模型的有效性。我们将在下面对三个数据集的具体细节进行介绍:
表2 三个数据集的详细信息

源域和目标域中每个类别的样本数为1000,因此源域和目标域分别有4000个样本。训练数据集包括源域样本和目标域样本,而测试数据集仅包括目标域样本。考虑到实际中故障样本较少,采用滑动采样技术对原始数据进行分割,以增加故障样本,相邻样本之间存在重叠点。另外,每个样本有3072个数据点,以获得足够的故障信息。为了减少额外的计算量和专家意见的影响,本文直接使用原始振动样本作为故障诊断模型的输入。
通过使用上述三个方位数据集,构建了六个跨机器迁移任务来验证DDTLN的有效性:A → B,B → A,A → C,C → A,B → C和C → B。需要说明的是,这六项跨机器迁移任务全面包含了负荷和速度迁移。以A → B为例,“A”和“B”分别表示有标签的源域和没有标签的目标域。这些数据集的所有参数对于健康状况是相互不同的。这表明,当使用DDTLN精确诊断故障时,六个迁移任务是一个挑战。
考虑到伪标签不等于真实标签,在等式3中将参数γ设置为γ = λ =0.1。该设置能够减少DDTLN训练期间IJDA损失和目标域I-SoftMax损失的影响。在实验过程中,学习率被设置为0.001。epoch设置为300,batch_size设置为256。此外,DDTLN在Tensorflow平台上使用NVIDIA 1050Ti的GPU进行训练。
6.3 I-Softmax损失的有效性分析


图3 投影到单位球体上的学习特征的可视化
表3 实验结果

六个跨机器迁移任务的实施,以证明诊断的准确性和鲁棒性的DDTLN。为了确保DDTLN的可靠性,每个方法在每个迁移任务中执行10次。十种方法的平均诊断准确度和相应的标准偏差。如下图所示,提出的IJDA机制的平均准确率比原IDA机制高6.37%,反映了IJDA机制的有效性。此外,为了证明所提出的DDM和I-Softmax的有效性,我们进行了消融实验。在不使用I-SoftMax的情况下,分别基于MMD、CORAL和DDM的IJDA(MMD)、IJDA(CORAL)和IJDA(DDM)被应用于故障迁移诊断。从表3中我们可以清楚地知道,所提出的度量DDM在IJDA机制中具有更好的性能。特别地,所提出的DDTLN的平均准确度超过90%,与其他方法相比,它是30.83%。应该注意,DDTLN在每个迁移任务中是最高的。总之,建议的DDTLN方法具有更好的诊断能力比典型的DA方法。
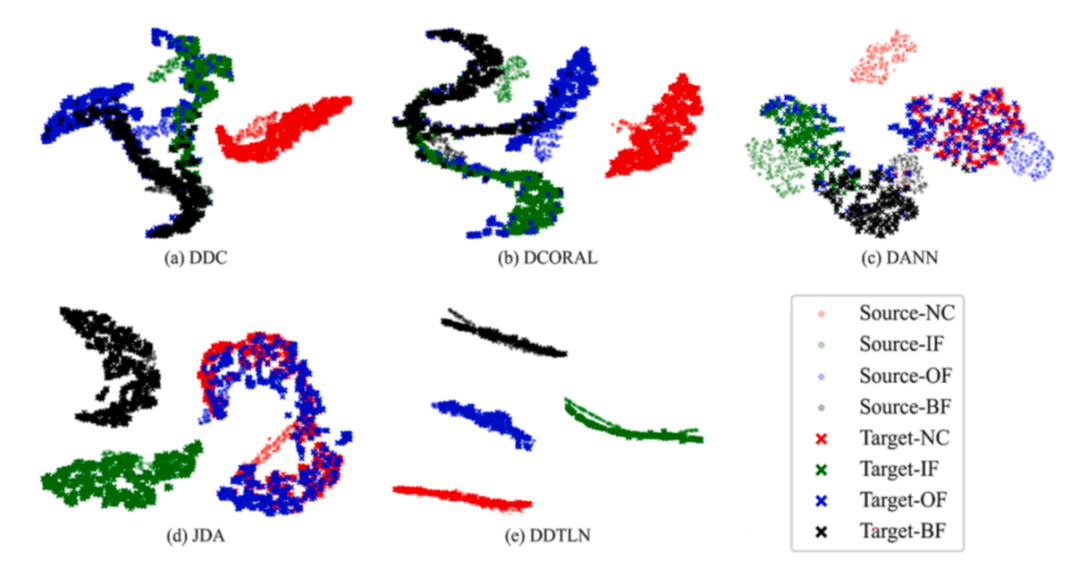
图4 通过五种DA模型获得的学习特征的t-SNE映射
6.5 进一步实验研究
表4 IMS的实验结果

7 总结
本文提出了一种新的迁移学习网络DDTLN来实现跨机器故障诊断。DDTLN主要由IJDA机制和I-Softmax损失组成。在IJDA中,构造了一个新的由MMD和CORAL组成的分布差异度量来增强域混淆。此外,提出了一种改进的CDA机制,以提高源域和目标域之间的分布匹配程度。与原有的Softmax算法相比,I-Softmax损失算法在学习更多可分离特征方面具有更强的能力。此外,它可以灵活地控制决策边界,可以方便地优化。通过IJDA机制和I-Softmax损失,DDTLN获得了更多可分离但域不变的特征。DDTLN在六个跨机器迁移任务中平均准确率超过90%。最后,实验结果也验证了DDTLN比已知的DA方法具有更强的诊断能力。
本研究存在DDTLN的可解释性和源域与目标域之间可移植性评估的局限性。在未来的工作中,我们将结合一些信号处理算法结合到迁移学习神经网络,以提高其可解释性,并探讨如何评估两个域之间的可移植性。
[1] 故障诊断开源代码推荐 | MCNN-LSTM,免费获取!
[2] 故障诊断开源代码推荐 | 轴承故障诊断迁移学习综述,免费获取!
[3] 信号处理基础之噪声与降噪(四) | 进击的EMD族降噪及python代码实现
[4] 信号处理基础之噪声与降噪(三) | EMD降噪与VMD降噪及python代码实现
[6] 风力发电机行星齿轮箱数据集 | 写论文再也不用担心没数据集啦!
[7] 航空发动机轴承数据集 | 写论文再也不用担心没数据集啦!
编辑:曹希铭
校核:钱泉、李正平、张泽明、张勇、王畅、陈凯歌、赵栓栓、董浩杰
该文资料(DDTLN)搜集自网络,仅用作学术分享,不做商业用途,若侵权,后台联系小编进行删除