HyperStudy和Optimus中使用样本数据快速创建代理模型(2/3)

背景
已有一组或一系列样本数据,如下图所示,目的是基于该组数据直接创建代理模型,以便于后续快速预测结果以及寻优。
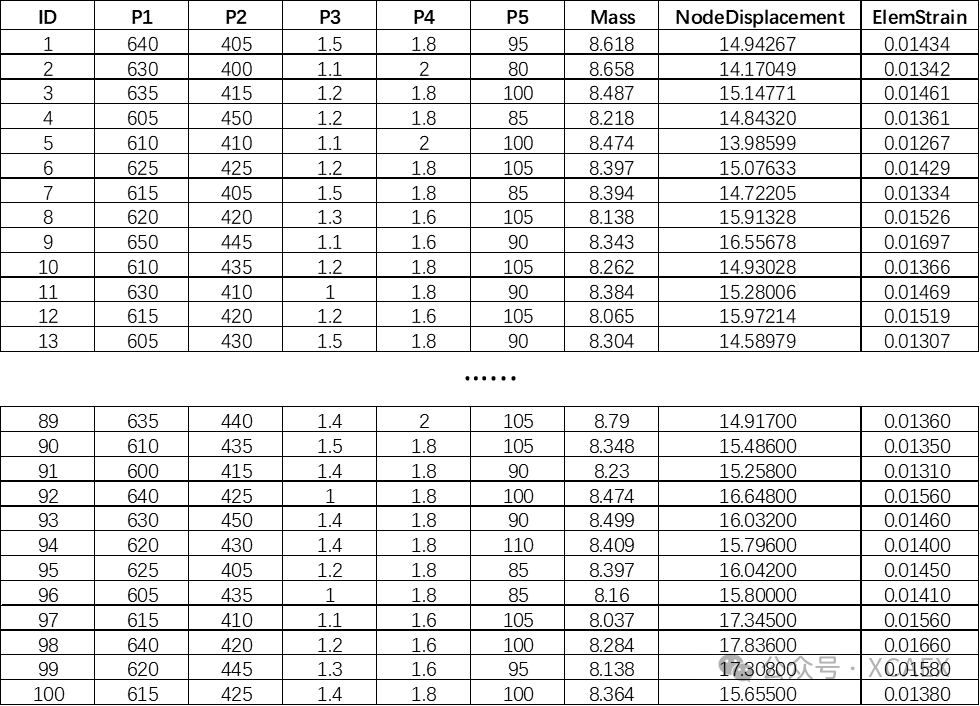
*上图数据中,第一列是ID,P1~P5为自变量(如模型中的料厚、尺寸等),Mass、NodeDisplacement、ElemStrain为因变量(也称响应,如模型的重量、计算结果的节点位移、单元应变等指标数据)
工具
本次将分别使用Altair HyperStudy和Noesis Optimus两款软件来基于数据快速创建代理模型。
模型训练-HyperStudy
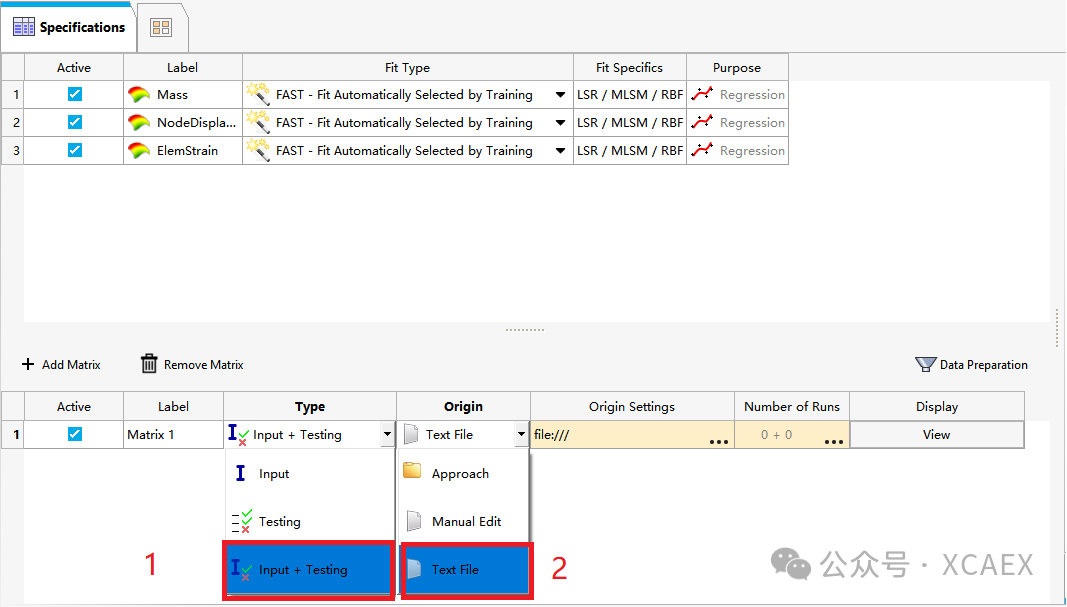
11、代理模型算法定义:进入“Specification”界面(1),为每个响应选择要创建代理模型的算法种类(2)以及配置算法参数(3、4),如下图所示,本例选择软件默认的第一个算法“FAST - Fit Automatically Selected by Training”,点击下图中3所指的表格,会在下图右侧4所示区域出现该算法的参数设置,用户可按需配置:

下图所示为HyperStudy软件中自带的代理模型算法:
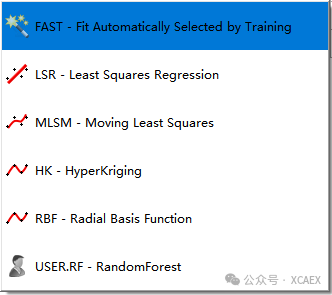
也可以通过“Edit”→“Register”→“External Fit”,添加自定义算法:

12、设置训练数据:在下方Matrix定义行中,
1)、Type选择“Input + Testing”,表示数据中包含训练用的数据和测试用的数据;
2)、Origin选择“Text File”,表示用文本导入数据:
3)、点击Matrix定义行中“Origin Setting”列中的“...”(1),打开数据导入对话框,选择前期准备好的数据文件(2),对话框中会显示所选文件的内容预览,根据实际情况选择数据的分隔符号,此外,由于我们数据中第一行是名称,因此要在“Columns have headers”行勾选,设置完成后,点击对话框右下角的“Next”按钮,进入下一步:

4)、在此界面中,完成列的定义,如果导入的数据与前面定义模型数据的一致,则软件自动完成列的匹配,如不一致或有特殊情况,需要重新分配列的关系,最后,点击界面右下角的“Finish”按钮,完成数据的导入和定义:

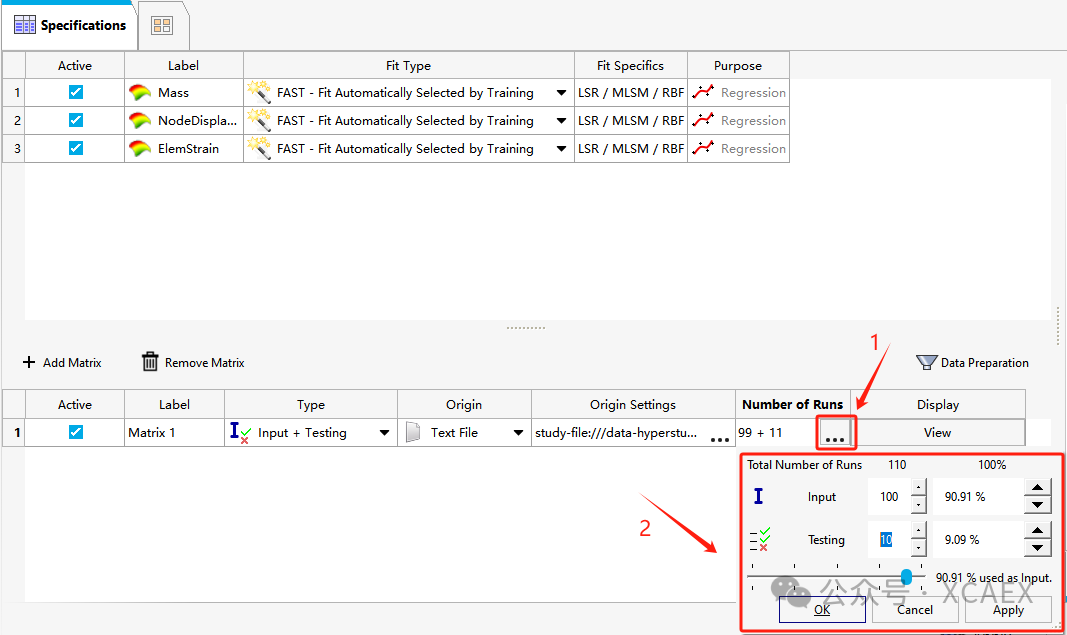
5)、回到主界面后,在Matrix定义行的“Number of Runs”列,点击“...”按钮,可以通过比例或数字设置用于训练的数据和用于测试的数据的比例或组数,如下图所示,我所准备的数据中有110组数据,将其中100组分配用于模型训练,10组用于验证测试,设置完成后点击“OK”关闭设置界面:
13、点击主界面下方的“Apply”按钮,应用本页所有设置,此时,右下角的‘Next’按钮生效,可进入下一步:

14、点击页面下方“Evaluate Tasks”,将根据前面所设置的算法和数据创建代理模型:

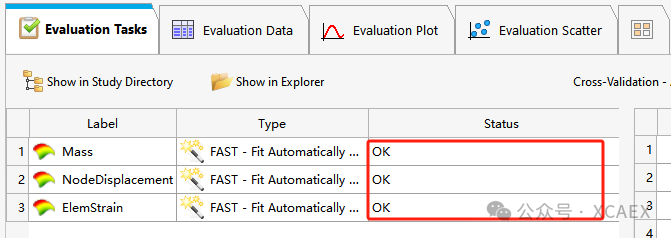
如下图所示,运行完成后,“Status”列显示状态“OK”:
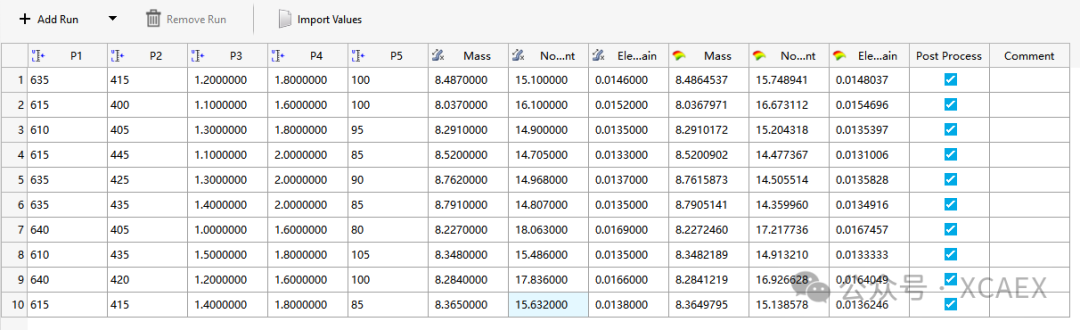
15、至此,便完成了代理模型的创建,可切换到“Evaluation Data”,查看运行结果,如下图所示,红色列为训练模型所提供的数据,绿色列为基于创建的代理模型计算的结果数据:

但是,此处仅有用于训练的100组数据的结果,要想查看用于测试的10组的数据结果,可返回到上一步“Specifications”,点击界面右上角“Edit Matrix”→“Full Testing Matrix”查看:

也可查看其他数据:


16、最后,进入下一步“Post-Processing”,在这里可以做更多的数据分析:
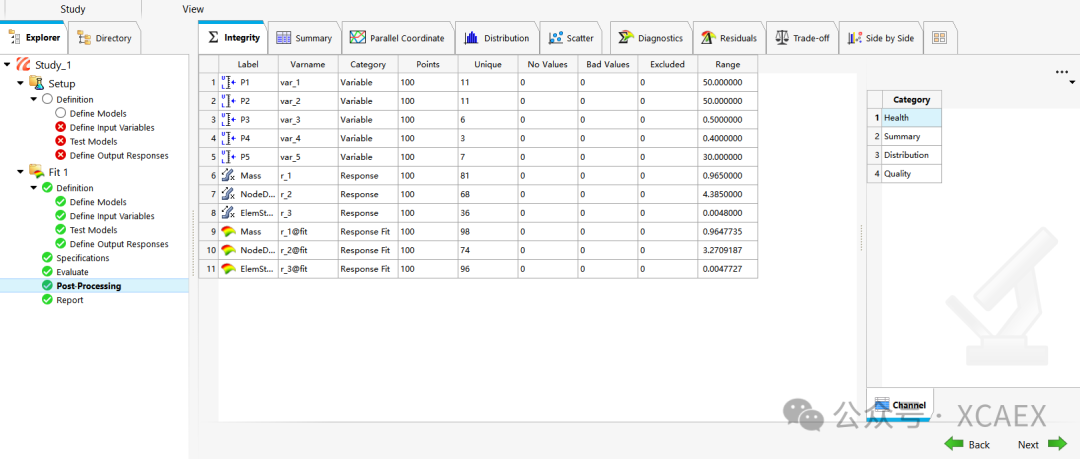
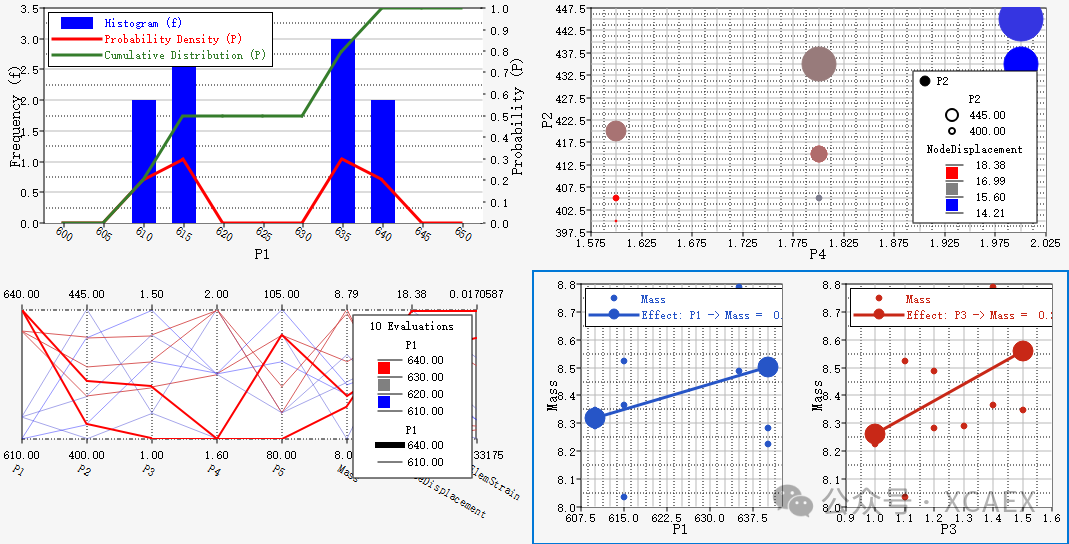
计算总表:

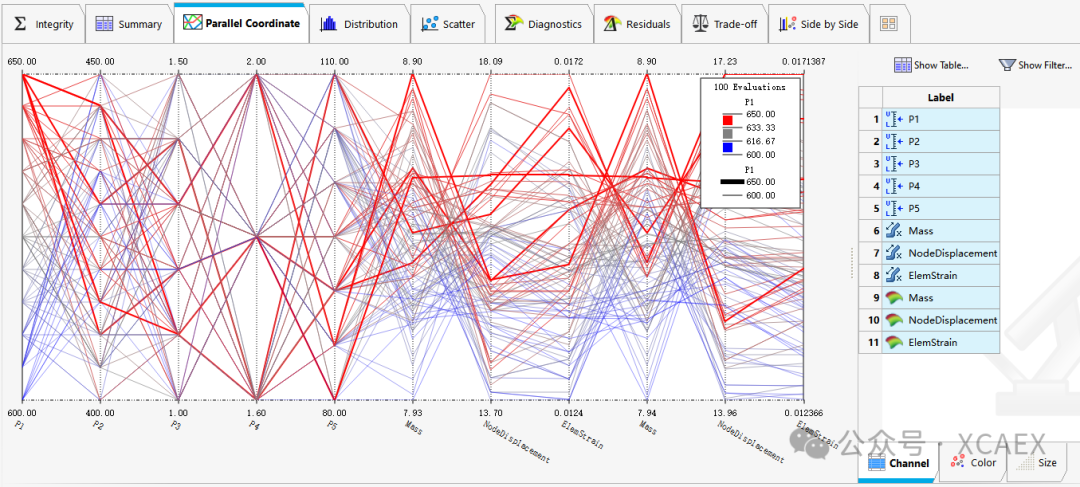
平行坐标图:
数据分布柱状图:



至此,便完成了HyperStudy软件中的代理模型创建、数据验证、数据后处理等介绍。



