中科院一区Top开源代码推荐|基于单侧对齐策略下的类别缺失鲁棒域自适应故障诊断
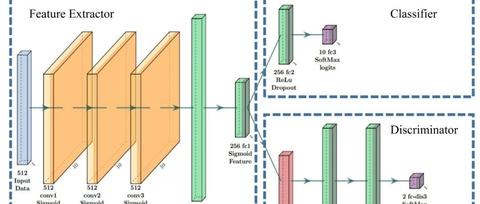
迁移学习是当前故障诊断领域的研究热点,然而针对其开源代码较少,小编整理搜集了一些开源代码与大家进行分享。本期分享的是基于单侧对齐策略下的类别缺失鲁棒域自适应故障诊断,该论文发表于中科院一区Top期刊IEEE Transactions on Industrial Electronics,并提供有该作者原创的开源代码,因此这篇开源代码适合参考借鉴并在上面进行改进学习,适合具备一定的深度迁移学习基础知识的学习者。该方法很贴合实际工程应用场景,非常值得阅读!1 论文基本信息论文题目:Missing-Class-Robust Domain Adaptation by Unilateral Alignment for Fault Diagnosis论文期刊:IEEE Transactions on Industrial ElectronicsDoi:https://ieeexplore.ieee.org/abstract/document/8949730论文时间:2020年作者:Qin Wang, Gabriel Michau, Olga Fink机构:Department Information Technology and Electrical Engineering, ETH Zürich, Zürich, Switzerland2 摘要领域自适应的目的是将源域中学习到的知识迁移到目标领域来提高模型性能。目前,领域对抗方法在减小源域和目标域之间的分布偏移方面取得了很好的成果。然而,这些方法均假设两个域之间的标签空间相同。这种假设对真实的应用造成了明显的限制,因为目标训练集可能不包含完整的类别。在本文中,我们证明了领域对抗方法的性能在训练过程中容易受到不完整目标标签空间的影响。为了克服这个问题,我们提出了一个两阶段的单侧对齐方法。所提出的方法利用源域的类间关系单独将目标域与源域对齐。所提出的方法在目标训练集缺失类别的故障诊断任务中进行了评估,证明了所提出的方法的有效性。关键词:故障诊断,领域自适应,特征对齐3 目录1 论文基本信息2 摘要3 目录4 引言5 相关工作5.1 领域自适应中的类别缺失5.2 领域自适应在故障诊断中的应用6 所提出的方法6.1 阶段一:只基于源域学习到类间关系的提取6.2 阶段二:单侧对抗域自适应6.3 总结7 实验7.1 数据集7.2 数据预处理7.3 模型实现7.4 实验结果8 总结注:本文只选中原论文部分进行分享,若想拜读,请下载原论文进行细读。小编能力有限,如有翻译不恰之处,请多多指正~4 引言近年来,深度学习方法在各种任务中均已经取得了显著的成果。然而,这些方法不仅需要大量的训练集,还需要标签来学习数据特征。特别是对标签的要求,这很昂贵甚至有时候是不可能获得的。因此,由于深度学习方法的这种数据密集型性质,限制了它们在实际应用中的效果。此外,如果训练集和测试集之间存在分布偏移,会导致模型很难泛化。无监督领域自适应技术提供了一种有前景的解决方案来缓解缺失标签和域偏移这两个挑战。领域自适应的目的是利用未标记的目标数据来提高模型在目标领域的泛化能力。它允许知识从源域迁移到不同但相关的目标域。最近,对抗域自适应方法以对抗方式对齐源域和目标域数据,并在潜在空间中加强领域不变特征,显着提高了领域自适应性能。这些无监督领域自适应方法通过跨域迁移已知知识来减小对目标域上的标签的需求。然而,它们通常假设源域数据和目标数据的标签空间是相同的。这种假设对实际应用过程中产生了限制,因为训练集可能不包含完整的类别集 合。在目标域中缺失类别的情况下,直接使用对抗域对齐可能会导致模型性能有很大不确定性。具有完整标签的源域和仅包含标签子集类别的目标训练集之间执行域对齐,会对目标训练集中缺失类别的模型性能产生负面影响。除此之外,直接领域对齐也会对类间关系产生负面影响。当领域自适应技术应用于不相同的标签空间时,在训练期间存在于目标域中的类别和缺失类别之间的对齐效果是不同的。这意味着对齐域的类间关系可能以不可预测的方式从源域中的原始类间关系扭曲。可以预期的是,当目标域中有更多的缺失类时,这种错位效应更大。为了减轻这种对齐的负面影响,更好地将学习到的类间关系从源域转移到目标域,我们建议将目标域单方面对齐源域,而不是将两者对齐到未知的中间空间。所提出的方法的最终目标是使对抗域自适应对目标域中的缺失类别具有鲁棒性。该方法更好地利用从源域中学习到的判别信息。由于我们无法了解目标域中某些类别的样本,因此只能通过使用从源域中了解到的类间关系来推断它们。我们认为,这种方法将提供一个更强大的表示为目标域。所提出的方法是主要包括两步:(1) 首先,只基于源域数据训练一个锚模型,并提取预训练的源特征。(2) 然后,通过最小化源域特征和预训练特征之间的距离,同时执行源域和目标域特征对齐,目标域分布被单向变换以匹配源域分布。综上所述,我们提出了一种解决目标域训练数据中缺失类的领域自适应问题的解决方案,同时仍然在目标域中的所有类上评估模型的性能。与以前的方法类似,我们以一种对抗性的方式对齐特征。然而,与以往的方法不同的是,我们将它们对齐源域侧。为了证明所提出的方法在实际应用中的适用性,我们评估了我们的方法在轴承数据集上的故障诊断任务的两个不同的操作条件之间迁移学习到的知识的任务。通过应用所提出的单侧对齐方法,我们能够提高轴承数据集的诊断性能。5 相关工作5.1 领域自适应中的类别缺失在领域自适应类别缺失的案例中,目标域类别是源域类别的子集。[24]建议使用重要性加权对抗网络来关注共同类别。[25]通过降低离群源域类别数据的权重来消除负迁移。[26]提出了跨域学习领域不变表示和渐进加权方案。但上述实验中,在测试过程没有评估缺失的目标类。这是与本文的关键区别。5.2 领域自适应在故障诊断中的应用在故障诊断问题中,当对工况进行调整时,漏类问题尤为严重。在不考虑缺失类别的背景下,领域自适应方法才刚刚被引入到故障诊断问题中。研究者已经提出了几种方法[34],[35]来处理故障诊断中的缺失类。然而,他们假设目标训练数据集只包含一个类(健康状况)。与我们的论文的主要区别在于,我们提出的方法能够处理不同数量的缺失类,这意味着我们提出的方法更通用,因为我们不假设目标训练数据都来自健康状况。6 所提出的方法目标域训练集中的缺失类别使得标准域自适应方法的直接应用变得困难。大多数方法背后的统一思想是将源域和目标域转换到共同的特征空间。这种一致性需要来自源域和目标域以及所有类别的充分支持。目标域信息的缺失可能导致比对的意外。潜在的问题之一是,对齐直观地改变了目标域中给定类别的分布,而对于目标域中缺失的类别没有给出指导。当前已知类别和缺失类别之间的这种不平衡的对齐行为可能会扭曲良好学习的源域类间关系,从而使对齐效果不佳甚至恶化模型性能。为了充分利用目标域中有限的健康数据,提高模型在所有类别上的性能,我们提出了一个两阶段的框架。我们首先学习源域中的分类模型,并提取源域数据的相关特征。然后,我们应用对抗域自适应技术,并对齐源域数据和目标域数据。我们通过确保单侧对齐来加强对齐,也就是说,迫使对齐的特征尽可能接近第一步中学习到的特征。我们在图2中可视化所提出的方法。图2 提出的两阶段单边对准方法注: (阶段1)我们使用单独的网络提取源域特征; (阶段2)我们通过添加一致性损失来单侧对齐分布。使用当前计算的源域特征及其对应的预训练特征来计算损失。 6.1 阶段一:只基于源域学习到类间关系的提取由于目标域中存在缺失的类别,因此只能从源域数据中学习类间关系。我们建议预先训练一个单独的神经网络来提取这种关系。我们假设我们拥有与第二阶段中使用的主网络相同的骨干架构:由 参数化的特征提取器 ,以及由 参数化的分类器 。因此,我们应用标准的有监督训练模型来学习这种关系。形式上,我们通过使用以下损失函数来训练这个单独的网络: 其中, 是softmax交叉熵损失函数,广泛用于有监督分类问题。网络仅使用源域数据 训练模型。在该阶段的训练之后,该阶段1网络被冻结。在阶段1的网络上成功训练之后,我们可以为每个源域训练样本 提取预训练的源域特征 。这些特征包含有意义的类间关系,因为简单的分类器能够对源域数据进行强有力的预测。然后,这些特征被用作阶段2的参考。6.2 阶段二:单侧对抗域自适应6.2.1 现有的对抗域对齐图5 所有的故障诊断实验中使用的主干网络 由于DANN在计算机视觉中的成功应用,以及其后来在工业应用中应用的启发。我们建议应用这种现成的领域自适应技术于缺失类别的迁移任务。如图5所示,我们的主要架构有三个组件:特征提取器 ,分类器 和鉴别器 。对齐是通过引入区分来自源域的健康特征和来自目标域的健康特征来实现的。同时,我们鼓励特征提取器 欺骗神经网络,使得特征不偏向它们开始的状态。这等价于下面的mini-max问题: 其中, 是源域数据, 是目标域数据, 是softmax交叉熵损失函数, 是域分类子任务的交叉熵损失。目标函数类似于生成对抗网络(Generative Adversarial Networks, GAN)。它包括两个部分:监督学习的分类损失和对齐的领域对抗损失。我们最小化分类损失,也就是特征提取器和分类器的参数。除了这种监督损失之外,我们还最大化了包括特征提取器参数的对抗性对齐损失,以便实现领域不变特征。我们进一步最小化对抗对齐损失。因此,训练神经网络以提供对原始特征的精确预测。通过在将特征提取器的梯度传递到域分类器之前反转它们,我们可以重新制定问题并减轻源域和目标域分布之间的H-发散。我们采用了这种优化技术来解决域自适应问题与缺失类别。上述使用来自DANN的梯度反转层(GRL)损失函数可以写为: 因此,它可以作为一个端到端的学习问题进行训练。6.2.2 使用单侧对齐作为附加损失DANN方法直接将完整的源域数据与具有缺失类别的目标域数据对齐。因此,预计会出现严重的不对齐。为了避免上述对齐的潜在负面影响,并在应用领域自适应技术的同时保留类间关系,我们建议将目标分布单侧对齐到源域分布的相应部分,而不是将两者对齐到共享的新空间。我们认为预训练的源域特征是所有类别的良好表示,因为可以实现类可分性。为了传递这种良好的表示,在阶段2中,使用额外的约束从而让对齐的源域特征尽可能接近预先训练的特征。如果对齐成功,则目标域特征也应该与预先训练的源域特征对齐。为了在使用部分领域对抗对齐时保持类间关系,我们使用预训练的源域特征 ,并迫使对齐的源域特征接近预训练的源域特征: 其中K是特征空间中的特征数量。我们将这个附加约束添加到上一段中描述的损失函数中。因此,总损失函数变为: 这种附加损失受到[42]中引入的一致性损失的启发,其中使用相似性距离来提高对象检测任务的边界框预测器的跨领域鲁棒性。然而,它在这里用于不同的目的,因为我们试图鼓励在一个方向上对齐并保持类间关系。我们使用 和 损失测试额外损失,发现它们之间没有显著差异。6.3 总结总而言之,除了通过DANN对齐源域和目标域分布之外,我们还提出了一个附加的约束条件,以使对齐朝着预训练的源域特征单向进行。单侧对齐的主要目标是保存从源域数据中学习到的类间关系,其中所有类别的知识都是可用的。7 实验在下面的部分中,我们将展示所提出的方法在不同的故障诊断任务上的优势。故障诊断是一个分类任务,我们的方法可以直接应用于这里。通常的标签由健康状态和故障状态组成。在本节中,我们故障诊断问题可以被理解为是目标训练集中80%的类别缺失时的无监督领域自适应。7.1 数据集我们在故障诊断数据集上进行实验:凯斯西储大学(Case Western Reserve University, CWRU)。我们尽可能地遵循[35]所使用的设定。因此,驱动端加速度计数据用作我们的输入。本文所涉及的标签列表如表2所示,即考虑了三种不同的故障类型以及一种健康状态。IF代表内圈故障,BF代表滚动体故障,OF代表外圈故障。每种故障类型包含三个子类型,故障直径为7,14,21mil。采样率为12kHz。当数据在12kHz时不可用时,我们会对其进行下采样,以确保所有实验中的采样率一致。表2 CWRU数据集的分类定义 CWRU数据集中有四个不同的负载{0,1,2,3}。在这四个不同的负载下进行跨域自适应。例如,任务0 → 1意味着工作负载0是带有标签训练样本的源域,工作负载1是我们想要提高模型性能的目标域。7.2 数据预处理图4 预处理步骤取自[29],[35] 对于CWRU数据集,我们遵循与[29],[35]相同的预处理步骤。如图4所示,首先,我们对每个原始记录进行下采样和截断。其次,我们将每个序列分为200个序列,每个序列包含1024个点。最后,使用快速傅立叶变换[46],每个序列被转换为512个傅立叶系数的向量。 7.3 模型实现图5 所有的故障诊断实验中使用的主干网络我们在图5中可视化了主干模型和我们的框架的细节。我们使用相同的架构[29],[35]来进行公平的比较。主干网络[35]由特征提取器和分类器组成。每个卷积层的卷积核长度为3,隐藏层大小为10。之后相应地添加丢弃层,丢弃率为0.5。然后,信号被平坦化并通过全连接层转换为大小为256的特征。分类器是一个大小为256的单隐藏层网络,使用交叉熵损失函数。我们只使用源域负载数据来训练这个主干网络作为我们的基线模型。为了实现我们的模型,还需要一个包含两个完全连接的隐藏层以及softmax交叉熵损失的隐藏层。主干网络和附加鉴别器的体系结构如图5所示。CWRU模型使用Sigmoid激活函数训练2000个Epoch。我们统计了5次运行的平均准确度和标准偏差。7.4 实验结果7.4.1 基于80%缺失类别的CWRU数据集的无监督领域自适应实验在这个实验中,目标训练数据集由所有类别的子集组成。需要再次强调,在该实验中,没有一个目标类别标签用于训练。我们考虑以下来自目标机器的未标记训练数据集: 进行缺失类别的实验。我们考虑k = 2进行演示。表3 基于80%缺失类别的CWRU数据集的无监督领域自适应实验结果 在这种新设置下的结果如表3所示,包含基准模型、DANN和具有我们的附加单侧约束的DANN。与基准模型相比,原始DANN并没有提供显著的改善。这可能是由于试图将所有类别的源域特征与仅包含20%类的目标域特征对齐的负面影响所造成的。这可能导致类内关系的扭曲。所提出的单侧对齐方法,解决了这种负面影响,并加强了对准效率。通过增加额外的一致性损失,相比原始的DANN,它提升了1.33%的准确率。7.4.2 讨论在案例研究中进行的故障诊断实验表明,当目标训练集中存在缺失类时,单侧对齐能够提高领域自适应问题的模型性能。我们观察到单侧对齐几乎不会出现损害性能的情况。在这种情况下,结果表明实际上不需要校准:基准模型已经提供了非常高的精度。我们的研究结果表明,在这种情况下,准确度的下降是非常小的,甚至微不足道,而在许多其他情况下,准确度的增益是显着的。总体而言,所提出方法的效果显着提升了。8 总结在本文中,我们证明了当目标训练数据集中存在缺失类别时,直接应用对抗域自适应技术会导致性能下降。为了克服这个问题,我们利用源域的类间关系提出了单侧对齐,这是一种简单而有效的训练策略。我们在故障诊断任务上的实验展示了所提出的领域自适应方法在工业应用中的潜力,其中缺失类别的问题对所应用的方法施加了显着的限制。发展所提出的模型在样本缺失情况下的性能是未来的发展方向之一。编辑:曹希铭校核:李正平、张泽明、张勇、王畅、陈凯歌、赵栓栓、董浩杰该文资料搜集自网络,仅用作学术分享,不做商业用途,若侵权,后台联系小编进行删除来源:故障诊断与python学习
有附件