基于preCICE的Fluent适配器开发分享

本文摘要:(由ai生成)
本文介绍了基于preCICE和FLUENT的后向台阶流耦合分析,通过开发适配器实现两者交互。利用FLUENT的UDF功能调用preCICE的API,构建特定目录结构和文件命名规则,使FLUENT能识别和加载UDF。文章详细描述了Fluent UDF的文件、构建要求和目录结构,以及构建Fluent-preCICE adapter的过程。初始化阶段包括构建SolverInterface、设置网格顶点信息等。数据交换通过Block函数实现。最终通过速度云图展示了耦合效果,证明了adapter的有效性。
1 开发目的
1 开发目的
后向台阶流是流动分离现象的经典代表,为了更有效地控制后向台阶流中的重要特征参数,如背部分离压强和湍流强度,进行了耦合分析。通过该耦合分析,能够深入研究后向台阶流的特性,并探索如何控制这些参数对流动的影响。
这项分析基于耦合软件preCICE和FLUENT,在两者之间通过adapter(适配器)的开发建立交互以实现耦合。
2 开发原理
2 开发原理
以FLUENT的UDF(user define function)功能对FLUENT进行计算方面的需求拓展,在UDF中调用preCICE中的API(Application Programming interface)实现耦合。
adapter、preCICE、求解器的交互如下图所示:
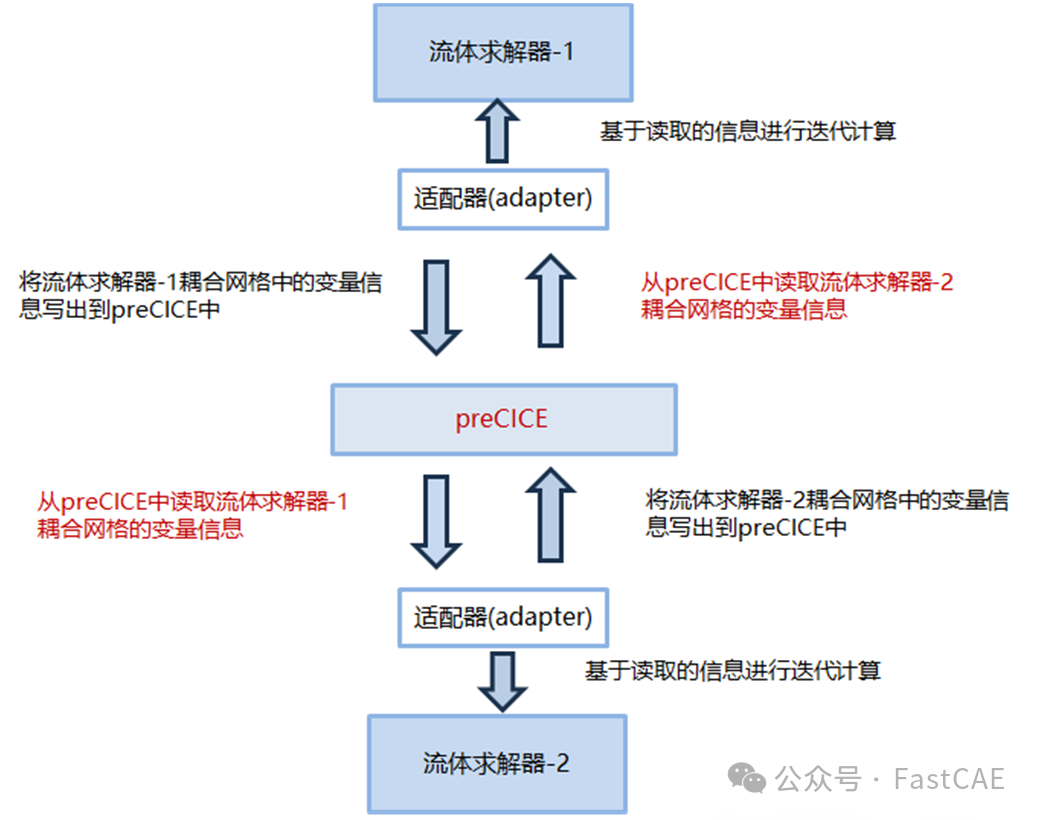
3 Fluent UDF 要求
3 Fluent UDF 要求
01
文件要求
首先关于需要执行的UDF文件,文件拓展名为.c。
其次,UDF必须使用Fluent提供的DEFINE宏进行定义(关于宏的解释在Fluent UDF用户手册)。
需要执行的UDF.c文件必须包含udf.h,即#include "udf.h"
df.h位于的目录X:\安装目录 \ANSYSInc1\v201\fluent\fluent20.1.0\src\udf
02
构建要求
通常情况下,如果编写的用户定义函数(UDF)不包含外部库,可以直接通过Fluent GUI界面进行编译,FLUENT将动态地生成所需文件——包含一个Makefile、一个"XXX.udf"文本文件和一个udf_names.c文件。
然而,由于preCICE是外部库,当需要使用preCICE库中的函数时,编译UDF时需要告知Fluent这些外部库函数的存在。而使用Fluent GUI进行编译时无法满足这个需求,因此需要通过命令行编译,同时需要遵循特定的目录结构和文件命名规则,以便让Fluent正确识别和加载UDF。
因此,在开发Fluent adaper的过程中,可以直接使用已有生成的Makefile、XXX.udf和udf_names.c文件,并通过对这些文件进行简单地修改,即可保持现有的文件结构和命名规则,让Fluent能够正确处理和加载UDF。在后文将会详细描述如何进行修改以保证正确编译UDF。
03
目录结构
fluent.cas和libudf位于同一个目录下,libudf子目录的内容如下。
若是在linux上构建,则一定有lnamd64,编译后的库(libudf.so)存在于lnamd64的子目录中,子目录的名称取决于模拟是二维/三维、单精度/双精度。
2d:二维单精度模拟
3d:三维单精度模拟
2ddp:二维双精度模拟
3ddp:三维双精度模拟
如果模拟是并行运行,则在lnamd64中存在两个子目录,一个带“_host”后缀、一个带有“_node”后缀,每个子目录都需要存在文件libudf.so的副本。
下面将通过示例说明目录结构形式及各文件的含义。
以3D并行单精度为例,对于在3D并行单精度模拟,需要存在以下目录结构:

3D单精度文件结构示例说明
由示例图可知:算例文件与编译的udf库libudf位于同级目录,在libudf中存在子文件lnamd64、src、Makefile。由于该示例为并行,因此lnamd64中存在3d_host和3d_node两个文件夹,若算例修改为串行则将仅存在3d_host。
以下是对各文件的说明:
Step5101642.cas.h5:算例文件
libudf
--lnamd64
----3d_host
------fsi_udf.c:用户编写UDF文件,包含Fluent的DEFINE宏。
------fsi_test.c:用户编写UDF文件,包含使用preCICE代码的自定义C函数。
------fsi_test.h:fsi_test.c的用户编写头文件。
------user.udf:用于定义要编译的文件名(fsi_udf.c、fsi.c和fsi.h)的文本文件,由makefile引用到fsi.c的用户编写头文件中,根据不同需求可能需要编辑此文件。
------udf_names.c:Fluent GUI自动生成的源代码文件;不需要编辑此文件。
------makefile:用于创建正确的编译命令的指令;可能需要编辑此文件以包含正确的目录。
------fsi_udf.o:fsi_udf.c编译的目标文件,即fsi_udf.c编译后得到fsi_udf.o。
------fsi.o:fsi.c编译的目标文件。
------udf_names.o:udf_names.c编译的目标文件。
------libudf.so:Fluent使用的共享库文件。
4 如何构建Fluent-preCICE adapter
4 如何构建Fluent-preCICE adapter
给定上述的 3D、单精度、并行运行的目录结构:
修改 lnamd64/3d_host/user.udf:
将 "CSOURCES=..." 更改为包括要编译的 *.c 源文件的以空格分隔的列表;对于 FSI 情况,应该包括 fsi_udf.c 和 fsi.c。
将 "HSOURCES=..." 更改为包括要编译的 *.h 源文件的以空格分隔的列表;对于 FSI 情况,应该包括 fsi.h。
将 "FLUENT_INC= " 更改为指向 Fluent 安装目录的路径。路径应该是 ./ansys_inc/v195/fluent 这种类型的。
修改 lnamd64/3d_host/makefile:
将 USER_OBJECTS 变量(第 20 行)更改为 libprecice.so 和 Fluent 附带的 Python 库的绝对路径的以空格分隔的列表。
libprecice.so 文件可以在 preCICE 安装位置中找到;例如,install/precice/2.3.0/lib64/libprecice.so。
Python 库可以在 Fluent 安装文件中找到;例如,/opt/Software/ansys/v202/commonfiles/CPython/3_7/linx64/Release/python/lib/libpython3.so。
将 RELEASE 变量更改为 ANSYS 发行版本号;例如,RELEASE=20.2.0。
构建 libudf.so:输入 'make "FLUENT_ARCH=lnamd64"'。
使用 "make clean" 清除构建。
将 lnamd64/3d_host/ 的所有内容复 制到 lnamd64/3d_node/。
5 配置文件的编写
5 配置文件的编写
在上述步骤中完成了构建FLUENT-adapter中关于FLUENT编译要求的文件结构准备,从该步骤开始准备PreCICE的配置文件(.xml)及PreCICE的API调用。
配置文件是求解器与PreCICE交互从而进行耦合的基础,以下为基于PreCIECE使用两个FLUENT进行耦合的配置文件示例:
<precice-configuration><log><sinkfilter="%Severity% > debug and %Rank% = 0"format="---[precice] %ColorizedSeverity% %Message%"enabled="true" /></log><solver-interface dimensions="3"><data:vector name="velocity" /><data:scalar name="static_pressure" /><mesh name="FluidOne-Mesh"><use-data name="velocity" /><use-data name="static_pressure" /></mesh><mesh name="FluidTwo-Mesh"><use-data name="velocity" /><use-data name="static_pressure" /></mesh><participant name="FluidOne"><use-mesh name="FluidOne-Mesh" provide="yes" /><use-mesh name="FluidTwo-Mesh" from="FluidTwo" /><write-data name="velocity" mesh="FluidOne-Mesh" /><read-data name="static_pressure" mesh="FluidOne-Mesh" /><mapping:nearest-neighbordirection="write"from="FluidOne-Mesh"to="FluidTwo-Mesh"constraint="consistent" /><mapping:nearest-neighbordirection="read"from="FluidTwo-Mesh"to="FluidOne-Mesh"constraint="consistent" /></participant><participant name="FluidTwo"><use-mesh name="FluidTwo-Mesh" provide="yes" /><read-data name="velocity" mesh="FluidTwo-Mesh" /><write-data name="static_pressure" mesh="FluidTwo-Mesh" /></participant><m2n:sockets from="FluidOne" to="FluidTwo" exchange-directory=".." /><coupling-scheme:serial-implicit><time-window-size value="0.01" valid-digits="6" /><max-time value="1000" /><max-iterations value="100" /><relative-convergence-measure limit="1e-3" data="velocity" mesh="FluidOne-Mesh"/><participants first="FluidOne" second="FluidTwo" /><exchange data="velocity" mesh="FluidTwo-Mesh" from="FluidOne" to="FluidTwo" /><exchange data="static_pressure" mesh="FluidTwo-Mesh" from="FluidTwo" to="FluidOne" /><acceleration:constant><relaxation value="0.5"/></acceleration: constant></coupling-scheme:serial-implicit></solver-interface></precice-configuration>
以下为配置文件中相关标签的解释:
log:定义日志输出的相关信息。
solver-interface:耦合的交界面。
data:vector(scalar) name:耦合交界面上参与耦合的变量名称。
mesh name:参与耦合的网格名称。
use-data name:该网格进行耦合的变量。
participant name:参与耦合的求解器名称。
use-mesh name:该求解器中参与耦合的网格名称。
write-data name:该求解器写出到preCICE中的耦合变量。
read-data name:该求解器从preCICE中读取的耦合变量。
mapping:nearest-neighbor:该求解器写出数据到preCICE或从preCICE中读取数据的映射方法,上述配置文件中选择nearest-neighbor,可根据需要选择其他的映射方法。
m2n:sockets:耦合参与者间的通信模式,上述配置文件中选择sockets,可根据需要选择其他的通信方法。exchange-directory 指定用于在参与者之间交换数据的目录路径。在上述配置文件中,exchange-directory=".." 表示使用当前工作目录的上级目录作为交换目录。
coupling-scheme:定义耦合方案,上述中定义为串行-隐式,并定义了时间窗口大小、耦合仿真的最大时间、每个时间步的最大迭代步数。
relative-convergence-measure:定义相对收敛准则,比较当前残差与时间窗口第一次残差 之间的差异。在上述中,阈值设置为 1e-3,表示残差的相对变化小于或等于 0.001 时被认为是收敛的。
Acceleration:加速方法的定义,上述选择的加速方法为constant,可根据需要选择其他的加速方法。
relaxation value:加速方法constant的松弛因子大小,松弛因子是在迭代求解过程中用于调整解的更新速度的参数。它控制了每次迭代中新解与旧解之间的比例关系。通过引入松弛因子,可以平衡求解过程的稳定性和收敛速度。
6 初始化阶段
6 初始化阶段
初始化的目的主要有:
1. 完全初始化 preCICE 并进行耦合数据设置。
2. 建立与耦合模拟的其他参与者的连接。
3. 对定义的网格进行预处理,并在并行环境中处理分区。
4. 确定可计算的第一个时间步长的最大允许大小。
初始化阶段调用两个PreCICE相关的API:
第一个为precice_createSolverInterface,作用是为耦合参与者构建一个SolverInterce,以便与preCICE建立耦合连接。

参数含义:
participantName:参与者的名称,这应该与配置文件中的参与者名称相匹配。
configFileName:配置文件的名称,该文件包含了PreCICE的所有配置信息。
solverProcessIndex:求解器进程的索引,通常在并行计算中使用。
solverProcessSize:求解器进程的总数,通常在并行计算中使用。
第二个为precice_setMeshVertices,作用是在preCICE中构建求解器中关于耦合网格的顶点信息。

参数含义:
meshID:网格的ID。
size:要创建的顶点的数量。
positions:一个数组,包含了所有顶点的坐标。数组的长度应该是size乘以空间维度(例如,在3D空间中,长度应该是3*size)。
ids:一个数组,用于存储由PreCICE生成的顶点ID。当你调用setMeshVertices函数时,PreCICE会为每个新的顶点生成一个唯一的ID,并将这些ID存储在ids数组中。这样,你就可以在后续的函数调用中引用这些顶点。

adapter初始化阶段的函数调用如下:
void coupling_init():对基于PreCICE耦合的求解器进行耦合的初始化。
void coupling_init() {double solve_dt = 0;printf("(%d)entering initialization\n", myid);int solver_process_id = -1;int solver_process_size = 0;int face_size = 0;double timestep_limit = 0.0;solver_process_size = 1;solver_process_id = 0;solver_process_size = compute_node_count;solver_process_id = myid;printf("(%d)creating solver interface-------\n", myid);if (RP_Variable_Exists_P("udf/config-location")) {const char* config_loc = RP_Get_String("udf/config-location");printf("(%d)before createSolverinterface,reading udf/config-location\n", myid);precicec_createSolverInterface(ParName_PreCICE[0], config_loc, solver_process_id,solver_process_size);}else {Error("Error reading 'udf/config-location' Scheme variable");}printf(" (%d) Solver interface created\n", myid);printf(" (%d) entering count_couplingMesh_FaceSize\n", myid);face_size = count_couplingMesh_FaceSize();printf(" (%d) Coupling Mesh have %d face \n", myid,face_size);set_mesh_position();printf("(% d) initializing coupled simulation\n", myid);timestep_limit = precicec_initialize();solve_dt = fmin(timestep_limit, CURRENT_TIMESTEP);printf("(% d)CURRENT TIMESTEP=%f\n", myid,solve_dt);printf("(%d)initialization done\n", myid);node_to_host_double_1(solve_dt);/*Fluent自带的宏,能够传递数据*/if (RP_Variable_Exists_P("solve/dt")) {RP_Set_Real("solve/dt", solve_dt);}else {Error("Error reading 'solve/dt' Scheme variable");}if (precicec_isActionRequired(precicec_actionWriteIterationCheckpoint())) {printf(" (%d) Implicit coupling\n", myid);udf_convergence = 0;udf_iterate = 1;precicec_markActionFulfilled(precicec_actionWriteIterationCheckpoint());}else {printf(" (%d) Explicit coupling\n", myid);}printf(" (%d) Synchronizing Fluent processes\n", myid);PRF_GSYNC();printf("(%d) Leaving INIT\n", myid);node_to_host_int_2(udf_convergence, udf_iterate);RP_Set_Integer("udf/convergence", udf_convergence);RP_Set_Integer("udf/iterate", udf_iterate);}
Int count_couplingMesh_FaceSize():计算参与耦合的网格上主要面的数量,并赋值给全局变量wet_face_size。
int count_couplingMesh_FaceSize() {Domain* domain=NULL;Thread* face_thread=NULL;face_t face;domain = Get_Domain(1);int face_size = 0;thread_loop_f(face_thread, domain) {if (Lookup_Thread(domain, CouplingID) == face_thread) {begin_f_loop(face, face_thread) {if (PRINCIPAL_FACE(face, face_thread)) {face_size++;}}end_f_loop(face,face_thread)}}wet_face_size = face_size;return wet_face_size;}
void set_mesh_position();将耦合面上每个网格的质心坐标存入PreCICE中。
void set_mesh_position() {printf(" (%d) entering set_mesh_postion() \n", myid);Domain* domain = NULL;Thread* face_thread = NULL;face_t face;double pos[ND_ND];int dim = 0;int face_index = 0;int faceMeshID = precicec_getMeshID(meshName_preCICE[0]); /*通过PreCICE给网格名绑定一个ID*/printf("in set_mesh_position(),faceMeshID is ......%d\n", faceMeshID);domain = Get_Domain(1);if (domain = =NULL) {printf("Error: domain==NULL\n");exit(1);}/*face_coords用来存储每个网格的三维质心坐标*/face_coords = (double*)malloc(wet_face_size * ND_ND * sizeof(double);thread_loop_f(face_thread, domain){if (Lookup_Thread(domain, CouplingID) == face_thread) {begin_f_loop(face, face_thread){if (PRINCIPAL_FACE_P(face_thread, thread)) {F_CENTROID(pos, face, face_thread);for (dim = 0, dim < ND_ND, dim++) {face_coords[face_index * ND_ND + dim] = pos[dim];}face_index++;}}end_f_loop(face,face_thread)}}face_indices = (int*)malloc(werface_size * sizeof(int));precicec_setMeshVertices(faceMeshID, wet_face_size,face_coords, face_indices);printf("(%d)leaving set_mesh_position\n", myid);}
7 数据交换
7 数据交换
在数据交换部分,求解器与PreCICE交互的关键函数为Block的相关函数,若求解器需要写出到preCICE的变量为矢量,则使用writeBlockVectorData。若为标量,则使用WriteBlockScalarVector,若求解器需要读取preCICE中的变量,则使用函数readBlockVectorData或函数readBlockScalarData。
以下为writeBlockVectorData函数的具体说明,其余三个Block的相关函数参数与该函数一致,因此不作赘述。
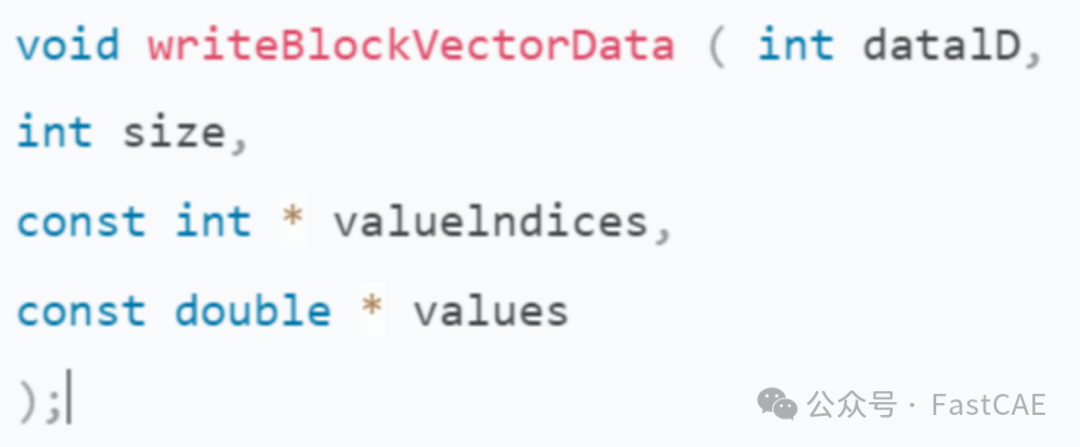
Parameters:
int dataID, 要读取或者写出数据的ID,preCICE中每个数据集都有一个唯一的dataID,通过dataID可以引用或操作特定的数据集。
int size, 顶点的数量,若为面心网格,则可以理解为面心的质量。
const int* valueindices, 顶点的索引。
const double* values,保存数据实际值的指针。
假设有两个求解器,求解A和求解B,若求解器A使用WriteBlockVectorData写出了数据,并且在该API中给定了dataID,那么求解B可以通过相同的使用ReadBlockVectorData来读取该数据。
以上为adapter开发中数据交换的基本原理,在实际开发的Fluent adapter中,数据交换阶段的函数调用顺序如下:

通过DEFINE_PROFILE将从PreCICE读取到的变量数值通过映射的方式赋值给耦合网格,通过DEFINE_ON_DEMAND每次写出变量数值到PreCICE中后进行下一个时间步的推进。
下方为求解器1将变量velocity写出到PreCICE中的代码示例:
void Advance_Coupling() {#if !RP_HOSTif (!is_coupling_going) {return;}if (precicec_isCouplingOngoing() == 0) {is_coupling_going = preicec_isCouplingOngoing();precicec_finalize();return;}int subCycling = !precicec_isWriteDataRequired(CURRENT_TIMESTEP);if (subCycling) {printf("(%d)In advance_Coupling(),In subscyling,skipping writing.\n", myid);}printf("(% d)writing veloity.....\n", myid);int MeshID = precicec_getMeshID(meshName_PreCICE[0]);int dataID_preCICE = precicec_getDataID(dataType_PreCICE[0], MeshID);int data_size = wet_face_size;Write_velocity(dataID_preCICE, data_size);printf("(% d)writing veloity done.....\n", myid);if (precicec_isActionRequired(precicec_actionWriteIterationCheckpoint())) {precicec_markActionFulfilled(precicec_actionWriteIterationCheckpoint());}if (precicec_isActionRequired(precicec_actionReadIterationCheckpoint())) {precicec_markActionFulfilled(precicec_actionReadIterationCheckpoint());}preciec_advance(CURRENT_TIMESTEP);printf("(%d)Advance_Coupling is done\n", myid);#endif}
下方为DEFINE_PROFILE宏从PreCICE中读取变量static_pressure并将其赋值于耦合网格的代码示例:
DEFINE_PROFILE(mesh0, thread, index) {if (last_time_mesh0 == CURRENT_TIME) {return;}last_time_mesh0 = CURRENT_TIME;face_t face;int data_index = 0;int mesh0ID_PreCICE = precicec_getMeshID(meshName_PreCICE[0]);int face_index = 0;int data_size = wet_face_size;double* data_buffer = NULL;int mesh0_DataID_PreCICE = preicec_getDataID(dataType_PreCICE[1], mesh0ID_PreCICE);if (strcmp(dataType_Fluent[1], "static_pressure") == 0) {printf("begin read static_pressure");data_buffer = Read_static_pressure(mesh0_DataID_PreCICE, data_size);if (data_buffer == NULL) {return;}begin_f_loop(face, thread) {F_PROFILE(face, thread, index) = data_buffer[face_index];if (face_index % 20 == 0) {printf("read static_pressure:%f\n", data_buffer[face_index]);}face_index++;}end_f_loop(face, thread);free(data_buffer);}}
8 adapter耦合效果展示
8 adapter耦合效果展示
下面将以速度的传输为例,展示adapter开发的耦合效果。下图为FLUENT-ONE算例求解后的速度云图:

下图为FLUENT-TWO算例求解后的速度云图:

FLUENT-ONE算例的右侧与FLUENT-TWO算例的左侧为耦合面。
通过分析FLUENT-ONE的求解云图,可知由于FLUENT-ONE算例中台阶处的速度梯度存在差异,导致其右侧耦合面也呈现不同的速度梯度。通过开发的adapter能够将这种速度梯度映射到FLUENT-TWO算例中,通过分析FLUENT-TWO的求解云图,可知其左侧耦合面的速度梯度与FUENT-ONE求解云图的右侧呈现良好的连续性,证明了基于preCICE框架开发的adapter有着良好的应用效果。
以上分析表明adapter能够有效地实现FLUENT-ONE和FLUENT-TWO之间的流动耦合,并保持速度梯度的连续性。这对于进一步研究和控制后向台阶流中的流动特性有所帮助。
9 参考资料
9 参考资料
构建FLUENT adapter参考来源:
https://github.com/precice/fluent-adapter/blob/develop/README.md
配置文件的编写参考来源:
1) http://precice.org/configuration-xml-reference.html
2) preCICE官方撰写的adapter配置文件:
https://github.com/precice/fluent/adapter/blob/develop/examples/Cavity2D/precice-config.xml
代码逻辑及开发思路参考:
1) https://github.com/precice/fluent-adapter/tree/develop
2) PreCICE官网 关于API的说明文档:
http://precice.org/doxygen/main/namespaceprecice.html#a8e2b95bfed472a520e74b8d70e3e9684
(完)



