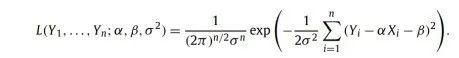JCP:深度学习与多相流研究 — 前沿进展及未来探索
本文摘要:(由ai生成)
本文综述了机器学习和深度学习在多相流模拟中的应用前景,并探讨了未来研究方向。深度学习通过多层非线性模型学习复杂数据表示,已在多个领域取得显著成功。文章讨论了机器学习在计算物理领域的应用,并强调深度学习在多相流模拟中的潜力。未来研究方向包括深度学习模型设计、结合物理约束的学习算法、大规模并行模拟的稳健性等。此外,计算技术进步和深度学习对跨学科合作的影响也值得关注。
本文综述讨论了机器学习和深度学习技术在多相流中的应用,并提出了利用深度学习来加强多相流研究和模拟的一些未来潜在的研究方向。
数据日益丰富。过去几年,人类集体产生的数字数据每两年或更短的时间就翻一番。这些数据中的一部分来自物理传感器,如通用电气火车上的传感器每分钟能生成15万个数据点。据英特尔估计,未来自动驾驶汽车中的各种摄像头和传感器每天每辆车能产生4TB的数据。数据还来自虚拟传感器,比如Facebook每天需要处理600多TB的数据,这些数据既来自自动分析收集,也来自用户提供的如信息和照片等数据。
这一趋势的主要原因是收集和处理数据的方法不断改进。例如,智能手机的普及导致了根本性的社会变革,但与此同时,它也带来了数据收集和传输方式的系统性变化。在智能手机时代,每个口袋里都装有多个高分辨率数码相机;现在,拍摄和分享照片和视频变得简单而廉价。据预测,在2017年创纪录的1.2万亿张照片中,创纪录的85%将来自手机,预计今年将存储相应的4.7万亿张照片。共同和共生的是,存储和传输数据的方式不断改进。有效处理数据的方法(软硬件结合)也大幅增加。例如,NVIDIA Tesla K20X是一款现代工作站GPU,具有3584个浮点处理内核,能够大幅提升并行数值算法的性能。在很大程度上得益于NVIDIA的通用CUDA平台,从集成GPU的移动设备到橡树岭国家实验室的Titan超级计算机,GPU在计算机中无处不在。在软件方面,谷歌的TensorFlow库能够对数据进行大规模异构计算,例如使用具有万亿字节参数的文档模型进行语言建模,针对Google的搜索结果排名,以及基于4000万生物数据点的药物发现。所有这些发展导致研究人员努力获得更多数据,这创造了一个增加数据和改进数据技术的良性循环——这是真正的数据爆炸。
尽管统计学家需要处理大量的数据。但是从历史上看,他们习惯于使用小规模数据集来预测更大的行为——但此类调查非常专注于小数据,而不是处理大数据。因此,统计学家基本上没有为数据爆炸做好准备。事实上,即使在像美国总统大选这样重要的事情上,知名新闻机构也仅使用数千个样本进行预测,而现代技术可以轻松收集数量级更多的样本。统计学家对小数据的偏爱导致其他人走到了数据科学的前沿;在某种程度上,人工智能实验室的那些人,尤其是机器学习专家。这些从业者中的许多人仍然与统计学家合作,使用概率/统计的语言,并致力于开发大量利用统计的计算工具——可能过于排他。事实上,在参数的最大似然估计(MLE)和最小二乘法之间存在众所周知的等价性:给定一组数据点(Xi,Yi),可以考虑Y1,...,Yn是遵循线性模型Yi=αXi+β+εi的随机变量,其中α和β是未知参数,εi~N(0,σ2)是独立的同分布高斯噪声。在这种情况下,要确定α和β的最大似然估计,需要最大化似然函数取α,β中的对数和丢弃项常数,显然最大化L等价于最小化

这是线性代数入门课程中介绍的标准最小二乘问题。鉴于这种等价性,在机器学习中不使用整个数值线性代数领域似乎是相当天真的;然而,机器学习实践者似乎过于专注于统计描述。传统的机器学习技术大致分为两类:无监督学习和有监督学习。在无监督学习中,没有为数据指定训练标签。因此,无监督学习通常用于包括聚类和异常检测的任务,其中人们希望在没有数据的标签和/或类别的先验知识的情况下识别数据中的相似性和差异。一种经典的无监督学习技术是主成分分析,它学习给定训练数据的线性不相关特征的基础并将数据投影到该空间。从这个意义上说,无监督学习有助于降低复杂数据集的维度,并有助于深入了解数据背后的潜在变量。 相比之下,监督学习利用带标签的训练集。常见的监督学习任务包括分类和回归。支持向量机、随机森林和逻辑回归都是监督学习算法的例子。监督学习本质上意味着为样本点(x,y)的集 合创建一个函数y=f(x)。有了这个函数,我们就可以对训练集中位于样本之间或附近的点进行预测。监督和非监督学习任务之间并不总是有明确的区别;例如,不是解决为向量x∈Rn的概率分布p(x)建模的无监督学习问题,而是可以应用链规则,而是应用监督学习技术来学习  。
。传统机器学习的成功实际上非常有限。尽管机器学习专家在概率和统计中使用了相当复杂的技术,但他们很少使用更复杂的应用数学和计算数学。例如,他们只使用最基本的线性代数,并强制他们的所有公式都是线性和/或凸的,以便他们可以使用凸优化。避免了非凸优化或任何种类的非线性。例如,支持向量机,监督学习的主力,解决凸优化问题,以找到输入数据之间的线性分离。在无监督学习中,流行的k-means聚类算法是一个最小二乘问题,也是一个可以写成线性系统的凸优化问题。
虽然传统机器学习中的这些线性方法对线性、凸数据和模型有效,但它们甚至无法学习最基本的非线性函数。在这个意义上,XOR是一个很好的例子,它是由相应的输出Y={0,1,1,0}定义在二进制输入对X={(0,0)T,(0,1)T,(1,0)T}上的。旨在确定模型y=f(x;θ)来优化数据的模型,传统的机器学习方法是最小化均方误差损失函数 ,其中Y(x)是真正的XOR函数。使用正规方程或另一种方法求解线性模型f(x;θ)≡f(x;w,b)=xTw+b,可以让该最小二乘问题产生w=0,b=0.5的解。换句话说,对于所有输入,XOR函数的最佳线性拟合输出0.5,即总是产生不正确的结果。这是意料之中的,因为数据不是线性可分的。
,其中Y(x)是真正的XOR函数。使用正规方程或另一种方法求解线性模型f(x;θ)≡f(x;w,b)=xTw+b,可以让该最小二乘问题产生w=0,b=0.5的解。换句话说,对于所有输入,XOR函数的最佳线性拟合输出0.5,即总是产生不正确的结果。这是意料之中的,因为数据不是线性可分的。
从历史上看,传统机器学习算法的局限性是由早期作品观察到的,这些观察导致了美国机器学习研究资金的缺乏。这些资金有限的时期通常被称为“人工智能寒冬”,包括20世纪70年代和80年代的大部分时间。由于美国的资金环境,许多顶级机器学习研究人员聚集在其他研究中心。在一个最重要的例子中,著名的从业者Geoffrey Hinton(他发明了多层神经网络的反向传播)、Yoshua Bengio(深度学习和神经网络方面被引用最多的作者之一)和Yann LeCun(卷积神经网络的先驱,领先的深度学习技术之一)都通过加拿大高级研究所进行合作,并在多伦多大学、麦吉尔大学和蒙特利尔大学担任研究员或教授,推动了加拿大东部机器学习和深度学习创新的强劲趋势。事实上,为了超越传统机器学习强加的线性和凸性的人为障碍,专家们开发了深度学习,结束了人工智能的寒冬。
深度学习使用分层模型发现数据的表示或特征集。深度学习的基本见解是使用多层较简单的表示来构建复杂的表示。这些图层通常链接在一起,因此可见图层(表示输入数据中可直接观察到的要素的图层)将其输出发送到一系列隐藏图层中,这些图层表示的是数据无法直接提供的更抽象的概念。在分层模型顶部的输出层向最终用户提供学习的表示。深度学习通过使用潜在多层的“深度”模型来学习传统方法无法适当捕捉的复杂、抽象和非线性表示,从而与传统机器学习区分开来。
回顾学习XOR函数的早期示例,代替传统的机器学习方法,可以改为采用深度学习方法并定义具有非线性激活和单个隐藏层的简单前馈网络,该网络可以成功学习XOR。激活函数指定了如何将网络层的输入映射到输出。关键的见解是对隐藏层使用非线性激活函数,如其中x∈X和max按分量方式起作用。验证g(X)=Y是微不足道的,即该网络精确地恢复了XOR函数。上述函数的非线性分量h(z)=max(0,z)被称为整流线性单元(ReLU),是当前深度学习模型中激活函数的典型建议。像XOR函数这样的例子导致了使用多层深度学习来学习非线性表示的想法,这是超越传统机器学习的一个重大进步。深度学习的这种数学力量结束了人工智能的寒冬,并产生了许多非常成功的基于学习的系统。将深度学习引入机器学习导致了发展的爆炸。例如,应用于许多视觉任务的深度学习方法在ISLVRC(ImageNet)图像分类挑战和COCO对象识别数据集上击败了最先进的结果。深度学习在其他领域也获得了成功应用,如机器人、医学成像、自动驾驶汽车、3D形状分析等。
在传统的机器学习中,甚至在深度学习中,算法通常被描述为寻找受某些约束的目标函数的最小值(随机梯度下降是一个无处不在的例子);然而,由于大多数实际问题中固有的非线性和复杂的能量状况,人们不可能找到真正的最小值。然而,机器学习专家通常不会以任何方式求解最小值;极小值不仅不重要,而且通常是不受欢迎的。基本思想是给定一组样本(x,y),找到一个能够很好地插值它们的函数不一定是目标。我们已经从基本多项式插值和ENO、WENO等方案中了解到。将函数与数据拟合远不如函数在数据之外和数据之间的行为重要。在深度学习中,专家将数据的拟合程度称为训练误差,将函数远离数据的效果称为泛化误差。因此,最小化训练误差可能会导致可怕的泛化误差,包括过冲、欠冲等。因此,在深度学习中使用优化算法的真正见解是,人们只是在某个参数空间中移动,由某种优化启发式方法松散地引导,以便有希望找到一组给出良好泛化误差的参数。
最近在深度学习领域,特别是在无处不在的非线性和监督学习的整个目标是函数插值这一事实的推动下,连续数学和应用数学出现了复兴。仅在几年前,一些顶级计算机科学家还声称微积分应该在高中阶段被离散数学所取代。10然而,这种情况已经发生了根本变化,因为最近的一些发展是围绕着计算函数梯度的反向传播进行的。不足为奇的是,当概率和机器学习书籍和课程谈论连续/离散概率之间的差异以及连续情况下在一个区间上积分的必要性时,通常最多只有一个衡量理论的脚注。11然而,我们相信全面拥抱连续数学即将到来、需要并将产生巨大影响。因此,我们认为应用数学应该在这一领域处于领先地位。 有趣的是,计算流体动力学和计算固体动力学研究人员已经真正掌握了函数插值这种艺术形式。他们使用各种网格——结构化和非结构化、精细和非精细、分层和重叠网格、无网格方法(如SPH法)、材料点方法、混合方法(如PIC和FLIP)、人们可以想象到的各种有限基础、基于CAD的等几何模型等。然后,使用这些有限有序对,他们执行包括插值、微分和求积在内的任务。这些公式中的每一个都在有限数量的离散点处提供有序配对(x,y),或者更一般地说,在谱方法中为紧凑甚至全局函数提供有限数量的系数。这个社区与机器学习社区之间的唯一区别是,机器学习社区通常专注于更高维度的(x,y)。但是机器学习领域的顶级研究人员遇到了一个非常重要的概念,与顶级研究人员在固体和流体力学领域的发现相同:这是一门艺术,而不是科学。这确实需要良好的数学直觉、精湛的技能等。,但也需要数学家所说的独创性或创造力。我们已经训练了一批善于创造低泛化误差、只受训练误差松散指导的人,从事计算流体和固体研究,我们可以将这支军队释放到机器学习社区中。此外,应用数学家和计算流体和固体研究人员处于利用机器学习(特别是深度学习)的模型和算法的理想位置,以便构建更好地纳入数据的物理模拟系统。 《Journal of Computational Physics》上最近的一些论文讨论了机器学习和深度学习,展示了计算物理中各种主题的应用。例如,在[1]中,作者将PCA应用于高分辨率不可压缩流模拟的数据库;新的模拟使用传统的高分辨率模拟在域的一小部分中运行,而从降阶模型推断的数据用于模拟域的其余部分。[2]使用高斯过程回归和贝叶斯优化来学习可变阶分数平流扩散方程中的阶参数。学习技术也应用于[3],其中贝叶斯线性回归用于预测量子力学系统的密度泛函理论模拟的交换相关泛函。在凝聚态物理领域,[4]使用各种监督学习算法(包括决策树、随机森林、k-最近邻和神经网络)从使用PCA映射的大型配置数据库中预测伊辛模型配置的能量和磁化强度。在另一个应用领域中,[5]设计神经网络来模拟托卡马克聚变反应堆中的超导磁体,并反过来使用这些模型来有效地优化系统设计选择。这些工作表明学习技术在整个计算物理学中的广泛适用性。 整合学习和物理的一个特别活跃的应用领域是湍流的建模和模拟。湍流建模是一个适合学习方法的主题,因为湍流模型通常是经验性的,目标是狭窄的流型;因此,当试图对复杂的湍流进行建模和模拟时,很难手动选择模型和模型参数。不是手动选择参数,而是通过在每次迭代中求解加权最小二乘回归问题来学习雷诺平均纳维尔–斯托克斯(RANS)k–ω湍流模型的最佳闭合系数,从而最小化模拟量和实验数据之间的加权距离。[6]使用基因表达式编程(一种进化学习算法)根据高保真模拟数据数据库,学习RANS模拟中雷诺应力张量的代数模型。[7]展示了使用随机森林和神经网络从RANS模拟训练数据中学习雷诺应力各向异性的第二不变量。[8]中的作者使用非线性拉普拉斯谱分析简化了模拟数据,并使用回归分析在模拟二维湍流瑞利–贝纳德对流的背景下研究了简化基础。[9]提出了一个基于迭代卡尔曼方法的贝叶斯框架,用于将实验数据和物理约束纳入RANS模拟的预测和不确定性量化。[10]提出了一种通用技术,其中高斯过程与逆问题解估计集一起使用,以学习线性和非线性问题的模型参数,例如RANS闭合建模。学习技术引起相当大兴趣的另一个主题是材料的建模和模拟,尤其是在多尺度框架中。例如,[11]使用Isomap(一种非线性流形学习技术)构建了一个降阶模型,用于有限应变环境下非线性超弹性材料的多尺度分析。[12]研究了复杂的地下地质模型,提出了一种核主成分分析的变体,以建立与数据更一致的降阶模型。[13]在经过训练的主成分特征基础上应用多元线性回归,以了解多相材料环境下的最佳屈服强度和应变划分模型参数。在[14]中,贝叶斯线性回归模型和团簇扩展光谱分解方法用于预测金属合金的热力学性质,具有不确定性。[15]概述了非均质介质的预测多尺度建模;值得注意的是作者对数据驱动的模型生成和降维与模拟学习技术的调查。最近的几项工作提出了在应用中更广泛或更基础的学习技术。例如,[16,17]描述了一个框架,该框架使用包括信息融合、多级高斯过程回归和扩散图在内的学习技术来执行流体动力学模拟,该模拟可以在并行环境中更好地扩展,可以对大型集群中的故障硬件具有弹性,并且可以使用提供的数据来改进模拟结果。[18]将稀疏网格技术与主要流形学习算法相结合,以提供更有效的生成式降维技术,并在汽车碰撞试验的有限元模拟中展示了其方法。在[19]中,描述了使用高斯过程从稀疏的、可能有噪声的训练数据中学习一般线性微分算子的参数的方法,例如在热方程和反应扩散方程中发现的那些。 我们强调[20]的工作,它将深度学习直接连接到多相流模拟。作者运行了大量双流体泡状流的直接数值模拟(DNS)实验以用作训练数据。该模拟数据用于训练一个三层神经网络,该网络学习系统闭合项的模型,即气体流量和流动应力。随后,改变初始条件,如空隙率,并使用神经网络的结果进行新的模拟;作者发现学习驱动的结果与相同场景的DNS结果惊人地一致。[20]还引用了与深度学习和多相流相关的几项较老的工作,例如[21]使用神经网络识别气体-液体流中的不同流型,以及[22]使用神经网络重建湍流通道流中的近壁流。多相流是支持学习的建模和模拟范例的一个有希望的目标,我们将在下一节中讨论这些领域交汇处的潜在研究方向。 JCP也并不是唯一发表相关数值模拟工作的期刊。除了JCP,这些基本数值方法也在许多其他地方发表,如计算固体的CMAME或IJNME,或者SIAM J. Numer. Anal.、JFM、Phys. Fluids等。事实上,即使是最近的SIGGRAPH和SCA会议也有大量将机器学习和深度学习与面向数值模拟工作相结合的论文。根据以上对多相流、机器学习和深度学习的回顾,我们提出了几种使用深度学习来增强多相流研究和模拟的未来研究途径。1.深度学习模型包括前馈神经网络、强化学习、卷积神经网络等。在这些类别中,还有进一步的设计选择,例如为神经网络中的隐藏层选择激活函数。正在研究的问题类型(例如气液泡状流与多孔介质渗透)如何影响应该使用的学习模型类型以及该模型中涉及的特定设计选择?2.统计方法通常会忽略潜在的物理原理,例如流体的不可压缩性。如何设计学习算法才能最好地结合物理约束,同时避免过度适应强加的物理条件?3.学习技术有助于创建稳健的大规模并行多相流模拟吗? 4.什么样的粗化和升级策略最适合学习技巧?更广泛地说,如何最好地利用数据(可能在多个尺度上获得)来提高多尺度多相流模拟的保真度和效率?5.哪些通用的降阶建模和降维技术适用于学习和多相流之间的相互作用?降维技术能否帮助识别数据中隐藏的低维特征和流形,或者降低需要收集的数据和需要预测的模型的复杂性?6.计算技术的持续进步将如何影响多相流,尤其是在支持学习的技术中?深度学习模型的深度或复杂性是多少,训练数据的数量是多少,足以产生最先进的预测模型?7.深度学习和数据驱动模拟的出现如何影响实验学家、计算科学家和理论家之间的现实世界合作?例如,这些社区如何合作为多相流模拟生成有用的大规模训练数据集?
[1] M. Bergmann, A. Ferrero, A. Iollo, E. Lombardi, A. Scardigli, H. Telib, A zonal Galerkin-free POD model for incompressible flows, J. Comput. Phys. 352(2018) 301–325.[2] G. Pang, P. Perdikaris, W. Cai, G.E. Karniadakis, Discovering variable fractional orders of advection-dispersion equations from field data using multi-fidelity Bayesian optimization, J. Comput. Phys. 348 (2017) 694–714.[3] M. Aldegunde, J.R. Kermode, N. Zabaras, Development of an exchange-correlation functional with uncertainty quantification capabilities for density functional theory, J. Comput. Phys. 311 (2016) 173–195.[4] N. Portman, I. Tamblyn, Sampling algorithms for validation of supervised learning models for Ising-like systems, J. Comput. Phys. 350 (2017) 871–890.[5] A. Froio, R. Bonifetto, S. Carli, A. Quartararo, L. Savoldi, R. Zanino, Design and optimization of artificial neural networks for the modelling of superconducting magnets operation in tokamak fusion reactors, J. Comput. Phys. 321 (2016) 476–491.[6] J. Weatheritt, R. Sandberg, A novel evolutionary algorithm applied to algebraic modifications of the RANS stress–strain relationship, J. Comput. Phys.325 (2016) 22–37.[7] [69] J. Ling, R. Jones, J. Templeton, Machine learning strategies for systems with invariance properties, J. Comput. Phys. 318 (2016) 22–35.[8] N. Brenowitz, D. Giannakis, A. Majda, Nonlinear Laplacian spectral analysis of Rayleigh–Bénard convection, J. Comput. Phys. 315 (2016) 536–553.[9] [141] H. Xiao, J.-L. Wu, J.-X. Wang, R. Sun, C. Roy, Quantifying and reducing model-form uncertainties in Reynolds-averaged Navier–Stokes simulations: a data-driven, physics-informed Bayesian approach, J. Comput. Phys. 324 (2016) 115–136[10] E.J. Parish, K. Duraisamy, A paradigm for data-driven predictive modeling using field inversion and machine learning, J. Comput. Phys. 305 (2016) 758–774.[11] S. Bhattacharjee, K. Matouš, A nonlinear manifold-based reduced order model for multiscale analysis of heterogeneous hyperelastic materials, J. Comput. Phys. 313 (2016) 635–653.[12] H.X. Vo, L.J. Durlofsky, Regularized kernel PCA for the efficient parameterization of complex geological models, J. Comput. Phys. 322 (2016) 859–881.[13] M.I. Latypov, S.R. Kalidindi, Data-driven reduced order models for effective yield strength and partitioning of strain in multiphase materials, J. Comput. Phys. 346 (2017) 242–261.[14] M. Aldegunde, N. Zabaras, J. Kristensen, Quantifying uncertainties in first-principles alloy thermodynamics using cluster expansions, J. Comput. Phys.323 (2016) 17–44.[15] K. Matouš, M. Geers, V. Kouznetsova, A. Gillman, A review of predictive nonlinear theories for multiscale modeling of heterogeneous materials, J. Comput. Phys. 330 (2017) 192–220.[16] S. Lee, I.G. Kevrekidis, G.E. Karniadakis, A resilient and efficient CFD framework: statistical learning tools for multi-fidelity and heterogeneous information fusion, J. Comput. Phys. 344 (2017) 516–533.[17] S. Lee, I.G. Kevrekidis, G.E. Karniadakis, A general CFD framework for fault-resistant simulations based on multi-resolution information fusion, J. Comput. Phys. 347 (2017) 290–304.[18] B. Bohn, J. Garcke, M. Griebel, A sparse grid based method for generative dimensionality reduction of high-dimensional data, J. Comput. Phys. 309 (2016) 1–17.[19] [107] M. Raissi, P. Perdikaris, G.E. Karniadakis, Inferring solutions of differential equations using noisy multi-fidelity data, J. Comput. Phys. 335 (2017) 736–746.[20] M. Ma, J. Lu, G. Tryggvason, Using statistical learning to close two-fluid multiphase flow equations for a simple bubbly system, Phys. Fluids 27 (2015) 092101.[21] Y. Mi, M. Ishii, L.H. Tsoukalas, Flow regime identification methodology with neural networks and two-phase flow models, Nucl. Eng. Des. 204 (2001) 87–100.[22] M. Milano, P. Koumoutsakos, Neural network modeling for near wall turbulent flow, J. Comput. Phys. 182 (2002) 1–26翻译转载自《Journal of Computational Physics》 “Sharp interface approaches and deep learning techniques for multiphase flow