SPH模拟的并行计算和GPU加速研究
本文摘要(由AI生成):
这篇文章介绍了在瞬态动力学模拟中使用的拉格朗日网格和光滑粒子流体力学技术,以及面临的挑战。作者提出了新的并行算法,用于有效地检测变形网格内部和网格单元与粒子之间的接触,并结合传统的并行有限元技术,实现粒子/网格瞬态动力学仿真。他们采用静态和动态分解方法来处理有限元分析和接触检测,最终在PRONTO-3D并行版本上展示了在超级计算机上的成果。
文一:

并行瞬态动力学模拟:接触检测和光滑粒子流体动力学算法
摘要:
瞬态动力学模拟通常用于模拟诸如车祸、水下爆炸以及船舶集装箱对高速撞击的反应等现象。在这样的模拟中,物理对象通常用拉格朗日网格来表示,因为网格在物体承受应力时可以随物体移动和变形。模拟中的流体(汽油、水)或类流体材料(土壤)可以用光滑粒子流体力学技术进行模拟。在大规模并行处理机计算机上实现混合网格/粒子模型带来了一些困难的挑战。一个挑战是同时并行和负载平衡计算的网格和粒子部分。第二个挑战是在模拟过程中有效地检测变形网格内部以及网格单元和颗粒之间的接触。这些接触传递力的网格元素和粒子,必须计算在每个时间步骤,以准确地捕捉物理的兴趣。本文介绍了光滑粒子流体动力学和接触检测的新的并行算法,它们具有几个共同的关键特征。此外,我们描述了如何将新算法与传统的并行有限元技术相结合,创建一个完整的粒子/网格瞬态动力学仿真。我们解决这个问题的方法不同于以前的工作,我们使用了三种不同的平行分解方法,一种是静态分解,另一种是动态分解,分别用于有限元分析和接触检测。我们已经在一个并行版本的瞬态动力学代码 PRONTO-3D 中实现了我们的想法,并展示了在桑迪亚基于奔腾的英特尔万亿次运算机上运行的代码的结果。

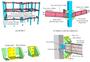
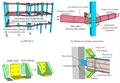
图:结合有限元和光滑粒子流体动力学模拟。

图:钢筋撞击砖墙的模拟。

图:穿透器撞击目标的FE/SPH混合模拟
文二:

用于图形显卡的通用平滑粒子流体动力学代码
摘要:
我们展示了现在开源的平滑粒子流体动力学代码miluphcuda的第二个版本。该代码设计用于在支持Nvidia CUDA的设备上运行。它处理一到三维问题,包括求解粘性和无粘性流体动力学流动方程、使用SPH的连续介质力学方程和使用Barnes–Hut树的自重的模块。覆盖材料模型包括不同的孔隙率和塑性模型。实现了几个状态方程,特别是碰撞物理方程。介绍了数值格式的基本思想,解释了代码的用法,并通过不同的应用表明了它的通用性。该代码特此公开。

图:落入多孔尘饼中的玻璃珠的弹坑深度

图:以目标为中心的帧中大小相似、差异化的实体的碰撞几何体。

图:为了可视化,使用UMAP将六维输入空间嵌入到二维分量a和分量b中。图的标题表示各自的颜色编码。请注意,只有保水性色标表示评估碰撞结果后的结果,其他色标表示初始条件。

图:原行星大小的天体之间肇事逃逸碰撞的快照。

图:颗粒柱的引力坍缩。SPH密度显示在左侧初始状态和右侧最终状态的体积渲染图像中。半径和高度之间的初始比值为a=0.55。

图:三种不同形状的投射物高速撞击锌板时产生的碎片云。
文三:

三维多相光滑粒子流体动力学的MPI并行化
摘要:
本文研究了三维多相平滑粒子流体力学(SPH)求解器的 MPI 平行化问题,重点研究了过冷大液滴(SLD)撞击问题。SPH 使用移动的粒子来表示流体流动,需要特殊的并行策略。细胞系统提供了一个空间参考,用于生成动态邻居列表,以及打包、发送和接收粒子。提出了一种适应粒子迁移的重新索引方法,并提出了一种序列粒子采集技术,降低了三维分区通信的复杂度。在1024个1.1亿粒子的处理器上进行了可扩展性测试,并研究了粒子负载对计算速度的影响。然后将求解器应用于不同冲击速度和直径下的液滴撞击,以研究由此产生的飞溅。这项工作为高度多线程的 SPH 解决方案提供了一种通用的方法,允许大量的计算来提高精度和/或参数研究的大量运行。

图:共享区域是沿着通信接口的单元层。

图:用于8个处理器上的立方域的1D、2D和3D划分策略。

图:重新索引技术以适应迁移的粒子(a)初始粒子位置(b)移动后的粒子位置(c)共享粒子(d)通过循环所有细胞重新索引粒子。

图:0.5毫米液滴撞击0.012毫米水膜的快照。

图:计算每个截面中粒子数量的径向装仓方法示意图。

图:液滴撞击不同直径的薄水膜的示意图。
文四:

用于大规模模拟的多GPU环境中的显式不可压缩平滑粒子流体动力学
摘要:
我们提出了一个具有稳定压力分布的显式不可压缩光滑粒子流体动力学公式,并在多个图形处理单元环境中实现。通过压力不变和无发散条件来稳定压力泊松方程,并使用Jacobi迭代求解器的第一步导出其显式公式。此外,我们还展示了如何将边界条件下的固定壁重影粒子应用到我们的显式方法中。该方法的验证和验证包括静水压和溃坝数值试验。与我们的单GPU实现相比,多GPU环境中的计算性能显著较高,具有合理的加速值。特别是,我们的代码允许模拟每个GPU卡上多达2亿的大量粒子。最后,为了说明我们的公式在模拟自然灾害方面的潜力,我们对2011年日本东日本大地震海啸淹没的著名福岛第一发电厂进行了模拟。

图:FWGP和虚拟标记定义。

图:单元格网格和粒子排序顺序的示意图。

图:将内存划分为多个GPU设备的示意图。

图:EISPH代码流程图。

图:a流体静力问题的几何参数,以及b由此产生的模拟粒子视图。

图:使用EISPH模拟有障碍物溃坝的粒子视图。

图:a P1、b P2、c P3和d P4有障碍物的模拟溃坝图形结果

图:溃坝模拟计算时间的图形表示。

图:福岛第一核电站初始条件下的三维粒子模型。

图:福岛海啸模拟压力分布。
文五:

加速多GPU集群上自由表面流的平滑粒子流体动力学模拟
摘要:
从平滑粒子流体动力学(SPH)代码DualSPHysics的单图形处理单元(GPU)版本开始,为自由表面流开发了一个多GPU SPH程序。该方法基于空间分解技术,将所研究物理系统的不同部分(子域)分配给不同的GPU。设备之间的通信是通过使用消息传递接口(MPI)应用程序编程接口(API)例程来实现的。详细描述了排序算法基数排序在GPU粒子间迁移和子域“halo”构建(实现不同子域的SPH粒子之间的相互作用)中的使用。一方面,利用由此产生的方案,可以进行也可以在单个GPU上执行的模拟,但现在可以比单独在这些设备中的一个上更快地执行模拟。另一方面,在当前架构上,可以使用多达3200万个粒子进行加速模拟,由于内存限制,这超出了单个GPU的限制。对弱和强缩放行为、加速和生成程序的效率进行了研究,包括阐明计算瓶颈的研究。最后,讨论了在我们的方案的未来版本中减少开销对计算效率影响的可能性。

图:使用三个GPU的多GPU SPH模拟快照,用于具有三个障碍物的溃坝。不同子域中的流体部分以不同的颜色显示,子域边界附近的白线对应于光晕。

图:具有两个节点的多GPU系统的图示,每个节点承载两个GPU。更一般地,多GPU系统由一个或多个计算节点组成,除了一个或更多个CPU之外,每个计算节点还托管一个或更多个GPU。不同的节点通过计算机网络技术连接,并通过MPI进行信息传输。

图:(a) 具有N个GPU的计算系统的一维域分解方案。总物理体积被划分为N个子域,每个子域被分配给不同的GPU。当从一个子域流到另一个子域时,以及当光环需要更新时,数据需要在GPU之间传输。(b) 处理相互作用范围内粒子动力学所需的数据(在我们的情况下,距离是平滑长度的两倍,2h)存储在子域的光晕中。

图:每个MPI进程用于使用不同数量的GPU进行模拟的CPU间通信的时间百分比。横轴对应MPI过程的标签。较小的时间对应于分配给模拟框端点的过程,如文中更详细的解释。

图:(a) 每个GPU固定数量的粒子nsub和增加数量的GPU的域分解方案,对应于弱缩放。(b) 对于给定数量的GPU(本例中为三个),可以显示光晕nhalo中粒子与nsub的比例降低,从而获得更好的缩放效果,如图所示。