UNAT加速库:突破异构计算瓶颈,实现跨平台高效仿真

本文摘要:(由ai生成)
UNAT性能可移植统一加速库旨在解决异构计算领域的挑战,实现了非结构网格的加速开发和高效计算。它支持多种拓扑形式和平台,通过统一硬件架构抽象和自适应数据结构提升开发效率。测试结果显示,UNAT在算子性能测试和稀疏矩阵向量乘运算中取得显著加速比。应用案例表明,UNAT能显著提升风资源分析和软件性能。未来,UNAT将继续拓展支持平台,为跨平台应用程序性能优化提供更多选择。
随着高性能计算机性能的不断跃升,传统的基于CPU的摩尔定律逐渐失效,因此,采用众核处理器来构建异构计算机已成为行业主流趋势。然而,异构众核处理器的迅猛发展也为异构计算领域带来了一系列挑战。
目前,异构众核处理器的架构呈现出多样化的特点,涵盖了CPU+GPU架构、CPU+FPGA架构、CPU+ASIC架构、多核CPU架构以及国产申威架构等多种形式。与此同时,并行编程模型同样呈现多样化的趋势,包括用于GPU加速的CUDA、跨硬件的OpenCL、加速CPU和GPU的OpenACC、共享内存的OpenMP以及跨节点并行的MPI等编程语言。在工业仿真领域,多种数据结构并存,如结构网格和非结构网格等,都对异构计算提出了更高的要求。
目前较为流行的性能可移植加速库为Kokkos,其C++库巧妙地统一了细粒度数据并行和内存访问模式的抽象,使得应用程序和函数库能在不同的众核架构上实现性能的可移植。Kokkos解决了异构节点上编程模型不统一的问题,并通过运用C++特性定义接口,极大简化了编程接口。GraphBLAS则是统一不同数据结构和算法领域的代表者,它采用了类BLAS库的矩阵、向量算子接口,不同之处在于允许用户自定义类型及类型相关的算子,相对传统数学库大大扩展了可用性。GraphBLAS屏蔽了底层数据结构的接口,为上层应用开发者减轻了负担,同时也为数据结构、算法与硬件架构的协同优化提供了更多空间。
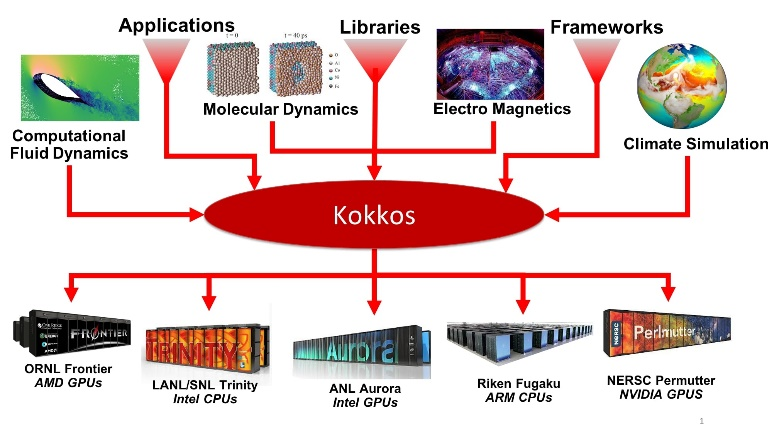
Kokkos应用场景

GraphBLAS中矩阵的图抽象
鉴于上述因素,针对非结构网格开展屏蔽硬件架构差异、封装数据结构和算法实现细节的统一加速库开发工作显得尤为重要。为此,我们提出了一个名为UNAT(UNstructured Acceleration Toolkit)的性能可移植统一加速库。UNAT充分吸收了KOKKOS统一硬件抽象和GraphBLAS接口统一等方面的优势,并借鉴了非结构加速套件的成功实践经验。目前,UNAT已经实现了在神威、x86平台上的数值模拟应用低代码加速开发和高效计算。
一
过往取得的丰硕成果
过往取得的丰硕成果
在工业仿真领域,主要包括两种数据结构——结构化网格和非结构网格。
非结构网格相较于结构网格具有更强的适应性和灵活性,在处理复杂几何形状和边界条件时表现出色,因此在工业仿真领域得到广泛应用。例如,知名商业CFD软件Fluent以及开源CFD软件OpenFOAM均采用基于非结构网格的有限体积法,而大多数结构分析软件如Abaqus、Nastran等则采用基于非结构网格的有限元法。尽管非结构网格具有显著优势,但其数据结构特性使得算法计算访存比较低、访存更离散,这导致超算的内存带宽成为瓶颈,尤其是在太湖之光等先进超级计算机上,对非结构网格算法的优化加速构成一大挑战。
神工坊在非结构网格FVM、FEM程序移植加速方面积累了丰富经验。为提升性能,我们提出拓扑、数据、算子三元分解概念,并运用迭代器实现三者间的联系与遍历执行过程。在迭代器中,我们进行了数据结构的预处理、多线程加速算法实现以及算子的施加。

按照拓扑、数据和操作三元分解的加速库接口设计,计算热点加速开发代码从1000行降至10+行
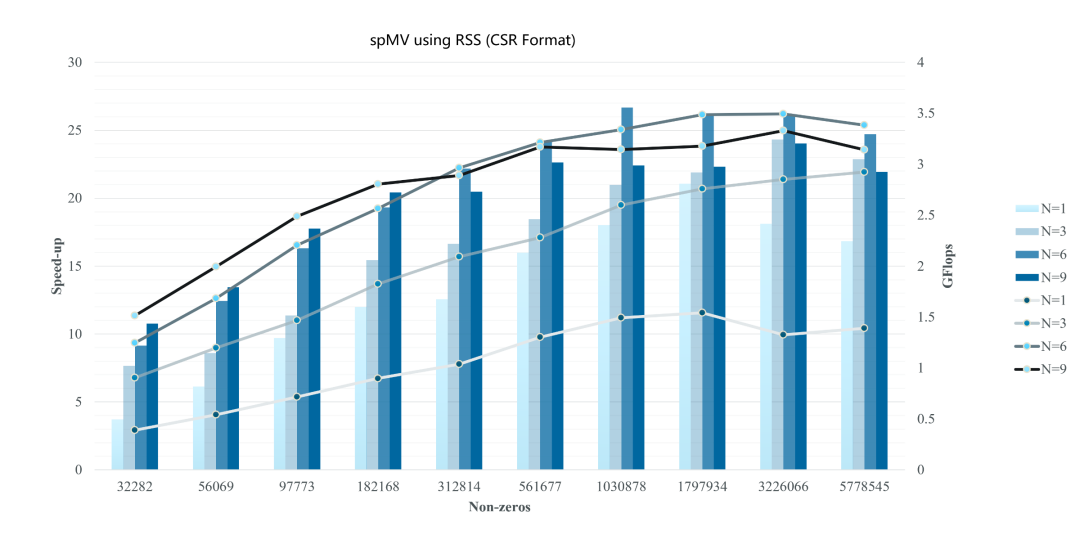
Goodwin矩阵spMV性能BenchMark测试,在神威·太湖之光上最高加速25+倍,超理论极限的70%
二
UNAT重点开发任务
UNAT重点开发任务
为了顺应国际加速库的发展趋势,并结合非结构化数据的特点,我们致力于开发一个跨平台、性能可移植的加速库。该库可实现统一的矩阵、向量形式迭代接口,以满足非结构、结构化、粒子等多种拓扑形式的加速需求。在工业仿真领域,向量、图、多维向量这三种拓扑尤为重要,其中向量运算对应物理场的操作,图-向量对应非结构网格的遍历,多维向量对应结构网格的遍历。
因此,我们的开发任务涵盖了向量、图、多维向量这三种拓扑,同时,我们将支持太湖之光、神威E级、NVIDIA GPU、x86共四类平台,后续我们将扩展国产神威新一代超算等平台,共计12大核心模块,并加以排序等辅助功能,以确保加速库的性能和易用性。
三
实现的路径及方法
实现的路径及方法
01
统一硬件架构抽象
经过精心设计和优化,我们根据GPU、申威、x86架构的不同之处,统一对硬件做内存RAM、多层级缓存Cache(Multi-Level Cache, MLC)抽象以简化架构,极大地缩减了软件开发过程,提升了开发效率,并降低了开发复杂度,使得软件开发者可以更方便地使用和管理硬件资源。此外,我们还统一设置了缓存数据访问Load和写回Store操作,对于无法手动控制缓存的处理器进行了置空操作或者设置个分段访问地址。我们能够为各个平台定制出高效且可靠的存取中间件,并对接口进行统一封装,展现给用户的仅为一个API接口。这样,用户无需关心底层实现的细节,即可轻松开发出跨平台的应用程序。

在优化硬件性能的过程中,针对RAM、MLC以及Load/Store操作,我们采取了不同的策略。在拓扑遍历计算的过程中,主要的应对方法如下表所示:
02
自适应数据结构
前文中,我们虽然对硬件进行了抽象处理,但针对数据的大小也存在着边界情况。为了确保数据的完整性和处理效率,我们采用了自适应操作,以避免数据溢出和离散访存导致的利用率低的现象。在实际应用中,数据的热点分布情况是复杂多变的,我们需要进行自适应分段并选择分段的粒度。通过采用高内聚分段算法对热点情况自适应选择分段粒度,保证多线程并发中不发生数据冲突问题。例如,非结构网格邻接矩阵采用分图法,结构网格采用二维或者三维分块法。
分图法:是一种用于将图(Graph)或图相关的数据结构进行划分的方法,它可以将大规模的图或网络划分成若干个子图,以便在不同的计算节点上并行处理。分图法的目的是尽可能均衡地划分图的节点和边,以减少通信开销并提高计算效率。
分块法:用于划分结构化数据(如矩阵),在分块法中,数据被划分成若干个块,每个块包含一定数量的数据元素。这种划分可以帮助提高数据访问的局部性,减少缓存失效和提高计算效率。

一维两色染色

二维四色染色(考虑对角也有临近关系)
四
测试结果展示
测试结果展示
01
算子性能测试
在算子性能测试中,我们选取了单向量累加、向量乘加、向量取倒数、计算调和级数4个算子进行测试。此次测试是在单核环境下完成的,以确保测试结果的准确性和可靠性。
我们对4个算子在神威平台进行了测试,测试结果如下图所示:
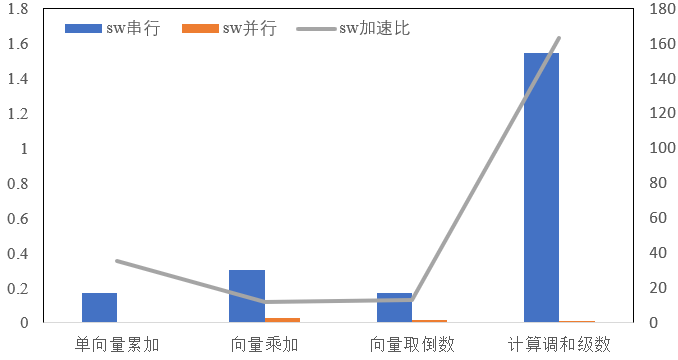
神威平台下算子加速比图
我们可以看出单核环境下使用算子和不使用算子之间存在显著的性能差异:4个算子取得了较高的加速比,加速比均在15以上,其中,调和级数的优化效果最为明显,达到了160的加速比。
02
稀疏矩阵向量乘
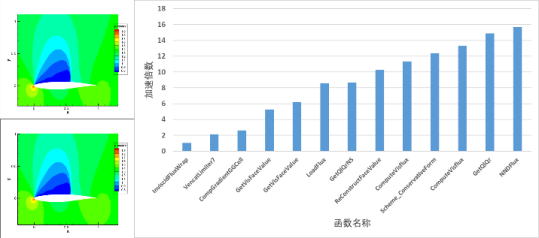
在数值模拟中,求解大规模稀疏线性方程组是非常重要的一个环节。在迭代求解过程中,稀疏矩阵向量乘法是耗时最长的计算核心之一,存在严重的数据局部性差、写冲突、负载不均衡等问题。因此,稀疏矩阵向量乘法已经成为了当前性能优化的难点和研究热点。
我们基于神威平台,随机选取了来自电磁、流体等领域的典型稀疏矩阵算例,测试了近60种矩阵,运行结果如下图所示:

根据上图,我们可看出大部分算例取得了较好的加速比,然而,也有部分算例的加速比并不理想,这可能与内部非零元素的数量以及矩阵的规模有关。为了进一步探索影响加速比的因素,我们计划接下来对非零元素的比例进行测试。加速比是指在进行性能比较时,用来表示在不同条件下执行相同任务所需时间的比值,它被广泛应用于并行效果的对比。加速比=串行时间/并行时间。
对非零元个数测试中,我们选取了1万-100万个不同级别的非零元个数的SuiteParse矩阵(前身为佛罗里达大学稀疏矩阵集 合),它是一组在实际应用中的稀疏矩阵,该集 合被数值线性代数社区广泛用于稀疏矩阵算法的开发和性能评估。矩阵非零元个数和加速比的关系如下图所示:

*算例来源:https://sparse.tamu.edu/
我们可以看出过半算例加速比在5以上,最大加速比接近20。加速效果与非零元个数成正比,即非零元个数越多,加速效果越明显。此外,加速效果还与非零元的比例成正相关,矩阵大小和非零元个数是决定性因素。
五
UNAT应用案例
UNAT应用案例
01
OpenFOAM风资源评估应用
某风电整机头部企业,需要对风场风机发电量进行实时评估,因此对风资源分析的分辨率要求高,仿真分析的规模也比较大,而预测用时不能太长,企业现有的硬件和软件资源无法满足现场要求。
基于神工坊平台,完成仿真求解模块的高性能改造及部署,整体性能提升4.2倍,最终实现产品化的为风资源工程师完成了超过2000个风资源项目的设计和评估。依托于超算平台,其自主研发的风功率预报系统孔明已发布推广,成为行业标杆应用。


02
风雷软件
用户开发了自研CFD软件,实现软件的国产化,但考虑硬件可能存在断供风险,需要在国产超算上进行适配,并实现百亿网格和百万核并行的超大规模数值模拟,但是用户对国产众核架构了解不多,如果从头学习,成本高昂,而且用户自研程序出于保密考虑,不能提供给第三方进行改造。
国内首个开源CFD软件PHengLEI,基于UNAT加速库加速,热点加速比最高达到15+倍,邻接矩阵带宽降低约100倍。