基于CUDA的GPU并行程序性能优化——GPU/CPU并行计算导论
本文摘要(由AI生成):
这篇文档的主要内容是大数据时代计算平台面临的挑战以及应对措施。文档指出,大数据时代的计算平台需要满足更高的性能要求,而摩尔定律的失效使得单纯依靠增加晶体管数目来提高计算性能的方法已经难以持续。因此,并行计算成为了提升计算性能的重要方法,包括多核和众核并行计算。文档还介绍了 OpenMP、CUDA、OpenCL 等支持并行计算的 API 和框架,以及并行度等衡量并行计算效率的指标。
大数据时代:计算平台面临挑战
• 互联网技术和信息行业飞速发展,大数据时代已经到来
• 大数据时代特点:
• 数据庞大
• 数据类型丰富
• 生成和处理数据速度快
• 对计算平台性能要求越来越高
挑战一:摩尔定律(Moore's Law)是否失效?
• 摩尔定律:Intel创始人之一戈登·摩尔提出。
• 当价格不变时,集成电路上可容纳的晶体管数目约每隔18-24个月便会增加一倍,性能也将提升一倍。
• 遵循摩尔定律,不断增加芯片上晶体管密度,提高单核性能。

图:Intel创始人摩尔和摩尔定律
一方面晶体管数目变多,晶体管尺寸越来越小,在尺寸不断接近物理极限时,晶体管难以再次分割,技术将涉及到量子领域。

图:Intel芯片数目变多,尺寸变小
其次,晶体管数目变多,意味着芯片的功耗越大,发热越大,一旦发热超过极限,晶体管就会面临着被烧穿的风险。
再者,晶体管的尺寸和数目的变化对设计和制造的工艺提出了更高的要求,也提高了生产的成本。

图:晶体管和生产制造成本
对于摩尔定律是否会失效,计算机领域呈现出了不同的看法。英伟达认为摩尔定律已经失效,Intel则认为摩尔定律仍然有效,而OpenAI公司则倾向于新版的摩尔定律的来临。

图:英伟达,Intel和OpenAI对摩尔定律的看法
为提升计算性能,除了增加晶体管的数目,还可以提高晶体管打开和关闭的速度,即晶体管的工作频率,提升芯片的计算性能。
CPU芯片的频率也叫主频,主频的提高会遇到功耗墙的问题。这里先解释一下功耗墙的概念:
CPU芯片的功耗墙是指在处理器设计和运行中,由于功耗限制而对性能造成的一种障碍。通常在设计和生产芯片时会规定芯片的最大产热功率,当处理大量数据时,CPU芯片接近或超过功耗限制,就会产生大量的热量,如果不能及时的排除,就会对芯片的使用寿命和计算性能产生影响。而高性能的芯片冷却技术价格昂贵,而且开发的难度较高,所以功耗的限制,对高性能计算提出了挑战,也对芯片设计和生产制造工艺提出了很高的要求。
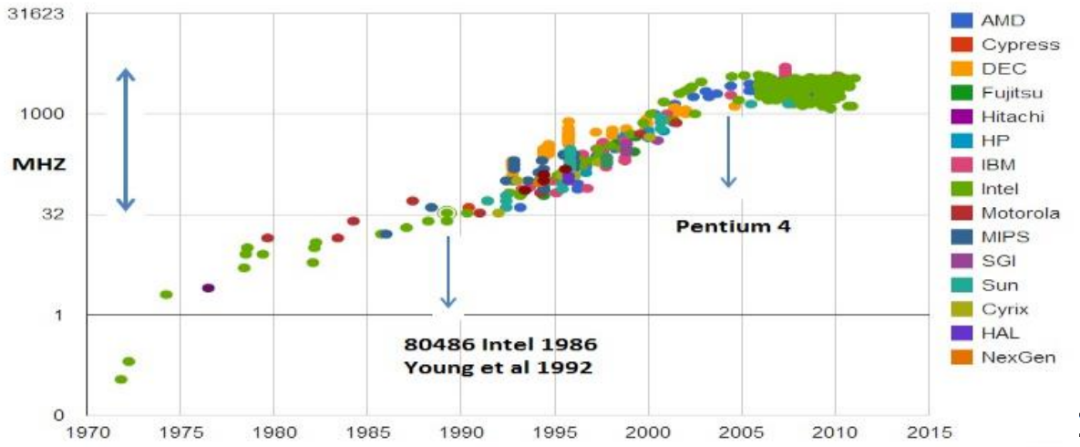
图:不同CPU芯片的功耗和主频
因此,如果凭借提高CPU主频的手段以提高计算效率,主频提高的同时,电力功耗越多,产生的热量也越多,热量增加时,即使频率不变,功耗也会增加。因此,持续提高时钟频率来提升CPU单核性能的模式无法持续。
目前CPU单核的时钟频率大概为2-5GHz:
Intel core i9 13900k: 3GHz,最高5.8GHz;
AMD Threadripper3990x:2.9GHz,最高4.3GHz
在高性能计算时代,为了提高芯片的计算性能,美国著名的电气工程师Seymour Cary曾这样说过:
If you were plowing a field, which would you rather use? Twostrong oxen or 1024 chickens?
---Seymour Cray
以下是对这句话的翻译:
如果你在耕地,你宁愿用哪一个?两头强壮的牛还是1024只鸡?
---Seymour Cray

图:Seymour Cary
(https://www.diariodesevilla.es/efemerides/Nace-Seymour-Cray-ordenador-comercial_0_1505549540.html)
中国也有一句老话:三个臭皮匠顶个诸葛亮。从某种程度上来说也是借鉴了这样的数量第一的思想。

图:三个臭皮匠顶个诸葛亮(https://www.sohu.com/a/456431157_121053768#google_vignette)
从此以后,众核和多核上的并行计算成为了提升计算性能的重要方法。并行计算指的是应用多个计算资源求解一个计算问题。目的是对问题加速求解或提高求解问题的规模。
并行计算
并行计算基本条件
实现并行计算需要满足一些基本的条件,包括:硬件、软件、并行度等
1. 硬件:并行计算资源
CPU、GPU、MIC、DSP、FPGA......
CPU:central processing unit——中央处理器
中央处理器(CPU)——也称为中央处理器或主处理器——是给定计算机中最重要的处理器。它的电子电路执行计算机程序的指令,如算术、逻辑、控制和输入/输出(I/O)操作。

图:英特尔酷睿i9-14900K的CPU
(https://en.wi kipedia.org/wiki/Central_processing_unit)
GPU:graphics processing unit——图形处理器
图形处理单元(GPU)是一种专门的电子电路,最初设计用于加速计算机图形和图像处理(在视频卡上或嵌入主板、手机、个人电脑、工作站和游戏机上)。

图:Nvidia GeForce RTX 4090的GPU
(https://umklogix.com.au/product/nvidia-geforce-rtx-4090-gigabyte-rtx-4090-gaming-oc-24g-graphics-card/?utm_source=Google%20Shopping&utm_campaign=Google%20Shopping&utm_medium=cpc&utm_term=7741&gad_source=1&gclid=CjwKCAiA6KWvBhAREiwAFPZM7qqMDw2pHBW6lheHZxRJbF4BW5g067o-ubrjHJLoBY2b6fE3JU0MTxoCjQAQAvD_BwE)
Intel MIC:因特尔Many Integrated Core多集成核心
它旨在用于超级计算机、服务器和高端工作站。其体系结构允许使用标准编程语言和应用程序编程接口(API),如OpenMP

图:至强融核(一款因特尔多集成核心)(https://en.wi kipedia.org/wiki/Xeon_Phi)
DSP:Digital Signal Processor——数字信号处理器
数字信号处理器(DSP)是一种专门的微处理器芯片,其架构针对数字信号处理的操作需求进行了优化。

图:L7A1045 DSP芯片(https://en.wi kipedia.org/wiki/Digital_signal_processor)
FPGA:Field-Programmable Gate Array——现场可编程门阵列
现场可编程门阵列(FPGA)是一种可配置集成电路,可在制造后进行编程或重新编程。FPGA是被称为可编程逻辑器件(PLD)的更广泛逻辑器件的一部分。它们由可编程逻辑块和互连的阵列组成,可被配置为执行各种数字功能。FPGA通常用于需要灵活性、速度和并行处理能力的应用,如电信、汽车、航空航天和工业部门。

图:来自 Altera 的 Stratix IV FPGA
(https://en.w ikipedia.org/wiki/Field-programmable_gate_array#Design_starts)
2. 软件:支持并行编程的编译软件
MPI、OpenMP、CUDA、OpenCL
MPI:Message Passing Interface——消息传递接口
消息传递接口(MPI)是一种标准化和可移植的消息传递标准,设计用于在并行计算架构上运行。[1] MPI标准定义了库例程的语法和语义,这些例程对使用C、C++和Fortran编写可移植消息传递程序的广大用户非常有用。有几个开源MPI实现,促进了并行软件行业的发展,并鼓励开发可移植和可扩展的大规模并行应用程序。
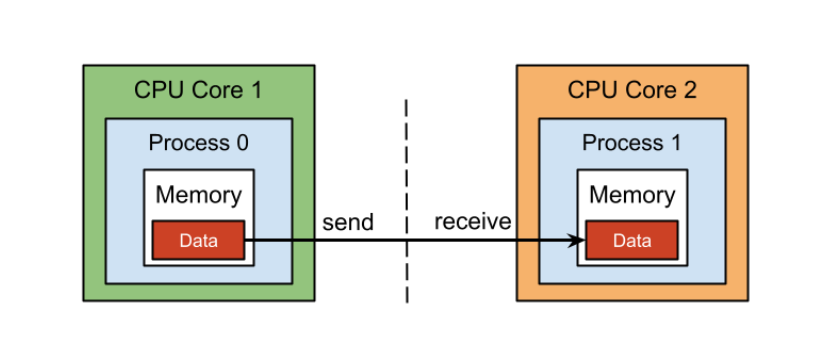
图:MPI点对点通信示意图(https://hpc.nmsu.edu/discovery/mpi/introduction/)
OpenMP:Open Multi-Processing——开放式多重处理
OpenMP(Open Multi-Processing)是一种应用程序编程接口(API),支持在许多平台、指令集体系结构和操作系统(包括Solaris、AIX、FreeBSD、HP-UX、Linux、macOS和Windows)上使用C、C++和Fortran[3]进行多平台共享内存多处理编程。它由一组编译器指令、库例程和影响运行时行为的环境变量组成。

图:OpenMP嵌入计算机(https://hpc.mediawiki.hull.ac.uk/Programming/OpenMP)
CUDA:Compute Unified Device Architecture——统一计算设备架构
CUDA是一种并行计算平台和应用程序编程接口(API),允许软件使用某些类型的图形处理单元(GPU)进行加速通用处理,这种方法称为GPU上的通用计算(GPGPU)。CUDA是一个软件层,可以直接访问GPU的虚拟指令集和用于执行计算内核的并行计算元素。除了驱动程序和运行时内核外,CUDA平台还包括编译器、库和开发工具,以帮助程序员加速其应用程序。
图:CUDA和计算机架构
(https://blogs.nvidia.com/blog/what-is-cuda-2/)
OpenCL:Open Computing Language——开放式计算语言
OpenCL(开放式计算语言)是一种用于编写跨异构平台执行的程序的框架,该平台由中央处理器(CPU)、图形处理单元(GPU)、数字信号处理器(DSP)、现场可编程门阵列(FPGA)和其他处理器或硬件加速器组成。OpenCL指定了用于对这些设备进行编程的编程语言(基于C99、C++14和C++17)以及用于控制平台和在计算设备上执行程序的应用程序接口(API)。OpenCL使用基于任务和数据的并行性为并行计算提供了一个标准接口。
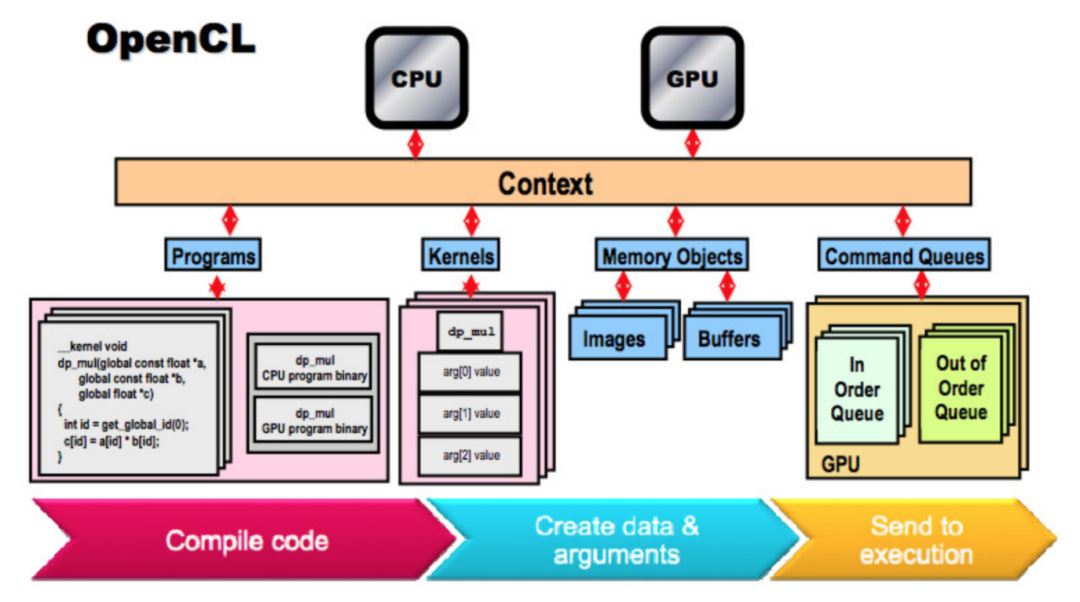
图:OpenCL的架构示意图。
(http://thebeardsage.com/opencl-architecture-and-program/)
3. 并行度:应用能否划分为多个子任务,并行执行。
并行度是指程序在多个处理器上的并行执行次数,以及每个处理器上执行的任务量。
并行度是衡量并行计算效率的一个重要指标,它直接关系到程序执行的速度和资源利用的效率。在并行计算中,一个高并行度的作业可以同时在多个处理器上运行更多的任务,这样可以显著减少计算时间,提高计算效率。但是,并行度的设置并不是越高越好,因为过高的并行度可能会导致资源竞争和管理开销的增加,反而降低效率。
在不同的计算框架和环境中,并行度的设置方式可能有所不同。例如,在Flink中,可以在整个作业的层面统一设置并行度,也可以针对特定的算子单独设置。而在Spark中,可以通过调整各个stage的task数量来控制并行度。

图:ColossalAI的张量并行
(https://finisky.github.io/how-to-train-large-language-model/)
并行计算的广泛应用
并行计算在很多个领域都有重要的作用,例如:
气象海洋
材料科学
仿真模拟
航空航天
金融
气象海洋
计算机模拟全球气候的并行计算技术的必要性是非常明显的。它可以帮助科学家更好地理解全球气候系统的复杂性,提高预测准确性,为应对气候变化提供科学依据。

图:全球气候变暖高性能仿真
(https://www.gfdl.noaa.gov/gfdl-simulation-of-global-warming/)
计算机模拟全球气候的并行计算技术的重要性主要体现在以下几个方面:
1. 复杂性:全球气候系统是一个高度复杂的系统,涉及大气、海洋、陆地、冰冻圈和生物圈等多个子系统之间的相互作用。这些子系统之间存在着复杂的非线性关系,因此需要大量的计算资源来模拟这些过程。
2. 大数据量:全球气候模拟产生了大量的数据,包括温度、湿度、风速、气压等气候变量。这些数据需要存储和处理,以便进行分析和预测。使用传统的串行计算方法处理这些数据可能需要相当长的时间,而使用并行计算技术可以加快数据处理速度,提高效率。
3. 实时性要求:全球气候模拟需要及时响应气候变化事件,如极端天气事件、海平面上升等。这些事件可能会对人类社会造成重大影响,因此需要快速准确地预测和评估其风险。使用并行计算技术可以满足实时性要求,为决策提供支持。
4. 模型不确定性:全球气候模型中存在不确定性因素,如自然变异性、测量误差等。为了更准确地预测气候变化,需要对模型进行多次模拟和比较。使用并行计算技术可以同时运行多个模拟,提高模型比较的效率。
5. 国际合作与共享:全球气候变化是全人类面临的共同挑战,需要各国合作共同应对。在国际合作中,共享数据和研究成果是非常重要的。使用并行计算技术可以方便地共享数据和研究成果,促进国际合作与交流。
材料科学
使用并行计算技术在材料科学的研究中是非常必要的。它可以帮助研究人员更好地理解材料的结构和性质,加快新材料的设计和发现过程,推动材料科学的发展。

图:由星形聚合物形成的微球的模拟。这是迄今为止使用HOOMD进行的最大规模的模拟研究,有1100万个粒子。(doi: 10.1002/adma.201570177)
在材料科学的研究中,使用并行计算技术的重要性主要体现在以下几个方面:
1. 复杂的模拟和计算:材料科学涉及的模拟和计算通常非常复杂,需要处理大量数据和进行高性能计算。使用传统的串行计算方法可能需要相当长的时间,而使用并行计算技术可以显著提高计算速度和效率。
2. 多尺度模拟:材料科学研究涉及多个尺度,从原子尺度到宏观尺度。在不同尺度上进行模拟和计算需要不同的方法和算法,而这些方法和算法往往需要大量的计算资源。使用并行计算技术可以实现多尺度模拟,提高研究效率。
3. 高通量筛选:在新材料的设计和发现过程中,需要进行高通量筛选,即对大量候选材料进行快速评估和筛选。这需要使用高效的计算方法和算法,以便在短时间内完成筛选任务。并行计算技术可以提供高效的计算能力,满足高通量筛选的需求。
4. 数据驱动的材料科学:随着数据科学和机器学习技术的发展,数据驱动的材料科学逐渐成为研究的热点。在数据驱动的材料科学中,需要处理大量的实验和计算数据,并从中提取有用的信息和知识。使用并行计算技术可以加快数据处理和分析的速度,促进数据驱动的材料科学的发展。
仿真模拟
数值模拟也就是在计算机当中建立真实物理世界的数字模型并复现物理世界当中的现象,使用并行计算技术在数值模拟中是非常必要的。它可以帮助研究人员更好地解决复杂的科学问题,提高研究效率和精度,推动科学技术的发展。也可以加快工业界设备等的研发和设计。

图:车辆行驶中气流的CFD模拟。
(https://developer.nvidia.com/blog/computational-fluid-dynamics-revolution-driven-by-gpu-acceleration/)

图:Simcenter STAR-CCM+202.21型号LeMans 104M在GPU上的性能与仅使用CPU的执行相比表明,性能最好的平台是NVIDIA A100 PCIe 80GB,速度高出20倍。
(https://developer.nvidia.com/blog/computational-fluid-dynamics-revolution-driven-by-gpu-acceleration/)

图:Simcenter STAR-CCM+基于(左)GPU和(右)CPU的运行之间压力系数平均值的比较结果。
(https://developer.nvidia.com/blog/computational-fluid-dynamics-revolution-driven-by-gpu-acceleration/)
在数值模拟中使用并行计算技术的必要性主要体现在以下几个方面:
1. 提高计算效率:数值模拟通常需要处理大量的数据和进行复杂的计算,使用传统的串行计算方法可能需要相当长的时间。使用并行计算技术可以显著提高计算速度和效率,缩短模拟时间,从而加快研究进度。
2. 处理大规模问题:在许多领域,如气候模拟、地震模拟等,需要处理的问题规模巨大,涉及大量的数据和复杂的物理过程。使用并行计算技术可以有效地处理这些问题,提高模拟的准确性和可靠性。
3. 实现高性能计算:并行计算技术可以利用多处理器或多核处理器的计算能力,实现高性能计算。这可以为数值模拟提供更强大的计算资源,满足高精度、高分辨率的模拟需求。
4. 促进科学研究的发展:随着科学技术的不断进步,对数值模拟的需求越来越高。使用并行计算技术可以帮助科学家更好地理解复杂系统的演化过程和机理,推动相关领域的发展。
5. 提高资源利用率:通过使用并行计算技术,可以充分利用现有的计算资源,提高资源利用率。这对于节省成本、降低能耗具有重要意义。
航空航天/国防

图:在航空航天和国防应用中使用GPU加速计算最大限度地提高任务关键性能
(https://www.thinkmate.com/inside/articles/maximizing-mission-critical-performance-aerospace-defense-applications)
在航空航天/国防工业中,快速的数据处理和分析在决策和保持对对手的竞争优势方面发挥着关键作用。最大限度地提高绩效是一个关键目标。无论是开发下一代飞机、设计先进的军事硬件,还是运行复杂的实时模拟,加速计算性能的能力对于确保高效有效的结果至关重要。
GPU加速计算已经成为这一领域的游戏规则改变者。GPU被设计用于处理大量数据,并可以同时执行多个任务,这使其成为航空航天和国防领域计算密集型工作负载的理想选择。
GPU加速计算有可能通过实现复杂系统的更快、更高效的模拟和建模,彻底改变航空航天行业。在航空航天工程中,GPU加速计算已被用于模拟和分析飞机发动机、飞行控制系统、导弹推进和制导以及结构部件的性能。这项技术使工程师能够实时建模、模拟和测试飞机设计,减少了测试所需的时间,并提高了结果的准确性。有了GPU加速计算,航空航天公司可以更快、更高效地设计和测试新飞机,从而显著节省成本并加快上市时间。
同样,在国防应用中,GPU加速计算有可能增强态势感知和决策能力。GPU加速计算的使用允许实时处理和分析来自各种来源的数据,包括卫星图像、雷达系统和无人机。这项技术使军事人员能够快速准确地识别潜在威胁并采取适当行动,从而提高作战效能并取得更好的结果。
其他用例包括:
1. 图像和信号处理:航空航天和国防工业经常处理大量的图像和信号数据。GPU可以加速这些数据的处理,从而实现更快的分析和决策。
2. 机器学习(ML):机器学习在航空航天和国防应用中变得越来越重要,尤其是在自动驾驶汽车和无人机等领域。GPU可以加速机器学习模型的训练,从而实现更快、更准确的决策。
3. 密码学:在航空航天和国防工业中,安全通信至关重要。加密算法可能是计算密集型的,GPU加速计算可以用于加速加密和解密过程,提供更快、更安全的通信。
4. 高性能计算(HPC):许多航空航天和国防应用都需要高性能计算,这通常是通过使用CPU集群来实现的。然而,GPU加速计算也可以用于实现HPC,提供了一种经济高效的解决方案。
金融
GPU加速在金融行业中的必要性主要体现在其能够提供强大的并行计算能力,支持人工智能应用,实现实时数据分析,降低交易延迟,推动数字化转型,并增强金融机构的国际竞争力。随着金融科技的发展,GPU加速将成为金融行业提高效率和创新能力的重要工具。
在金融行业中,使用GPU加速的必要性可能体现在以下几个方面:
1. 处理大量数据:金融行业需要处理的数据量巨大,包括交易数据、市场数据、风险数据等。GPU具有高度并行的计算能力,能够同时处理大量的数据,从而加快数据处理速度,提高业务效率。
2. 支持人工智能应用:金融行业中的人工智能应用,如算法交易、风险管理、客户服务等,都需要强大的算力支持。GPU加速可以提供这种算力,帮助金融机构在有限的资源条件下高效快捷地使用人工智能应用,创造更多业务价值。
3. 实现实时分析:金融市场变化迅速,实时分析对于交易决策至关重要。GPU加速可以提高数据分析的速度,使金融机构能够快速响应市场变化,做出更加及时和精准的交易决策。
4. 降低延迟:在高频交易等领域,毫秒级的延迟都可能影响交易结果。GPU加速可以降低数据处理和计算的延迟,提高交易执行的速度和准确性。
5. 数字化转型:金融行业的数字化转型需要处理大量的线上交易和经营管理数据。GPU加速可以帮助金融机构提高服务客户的能力,增强经营长尾客户的能力,以及快速抓住市场机遇。
6. 硬件加速技术的竞争:国际上,对冲基金等机构已经将FPGA等硬件加速技术应用于交易环节,提高了交易效率和竞争力。虽然FPGA和GPU在应用场景上有所不同,但GPU加速同样可以为国内金融机构提供技术支持,增强其在国际市场上的竞争力。

图:NVIDIA GPU在金融当中的大量数据计算效率的提升
(https://blogs.nvidia.com/blog/latest-benchmarks-show-how-financial-industry-can-harness-nvidia-dgx-platform-to-better-manage-market-uncertainty/)
异构计算
异构计算是指针对计算任务发挥CPU的逻辑处理的长处,同时也利用GPU等快速处理大量数据的特点,对人工智能、大数据分析等领域的研究数据快速处理。
一般而言,异构计算有以下的特点:
1. 多样性:异构计算环境包括各种类型的处理器和加速器,如CPU、GPU、DSP(数字信号处理器)、ASIC(应用特定集成电路)和FPGA(现场可编程门阵列)等。
2. 并行与分布式:异构计算通常涉及并行计算和分布式计算,可以是在单个设备上同时支持SIMD(单指令多数据)和MIMD(多指令多数据)的方式,或者是多个设备通过高速网络互连实现的计算形式。
3. 性能优化:传统的计算能力提升方法(如提高CPU时钟频率)面临散热和能耗的限制。而异构计算通过整合不同类型的计算单元,可以在较低的功耗下实现更高的性能。
异构计算特别适用于需要大量并行处理的任务,如人工智能(AI)、机器视觉、自动驾驶等领域。这些任务往往涉及到规则的数据结构和可预测的存取模式,非常适合于GPU等专用计算单元来执行。这种计算形式的优势在于能够根据不同的应用场景选择最合适的处理器,从而优化运算速度和能源效率。例如,CPU擅长处理复杂的指令调度和不可预测的存取模式,而GPU则擅于处理规则的数据结构和大量的并行操作。
尽管异构计算带来了许多好处,但在实施时也面临着一些挑战,如不同硬件之间的兼容性问题、程序的移植和优化、以及系统的管理和调度等。
两个重要概念
延迟:操作从开始到结束所需要的时间。
吞吐量:单位时间内处理成功的运算数量。
CPU和GPU的对比
架构对比
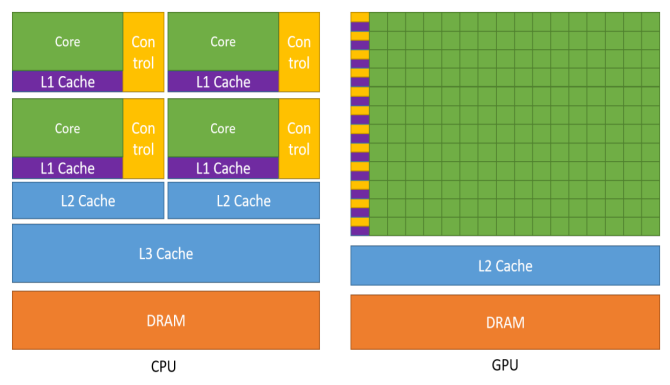
图:CPU和GPU架构的对比
CPU
大容量多级缓存;
核数少且大;
控制单元复杂。
GPU
缓存层极少、容量小;
大量的计算核心;
包含简单的控制单元。
线程机制对比
CPU线程切换缓慢:
重量级线程:执行非常复杂的控制逻辑,对串行程序执行优化 ;
一个核同一时刻运行一个线程的指令,使用几乎全部寄存器;
多线程机制下线程切换,上下文切换代价昂贵。
GPU线程切换零开销:
轻量级线程:适合简单控制逻辑的数据并行任务
努力于让每个线程都分配到真实的寄存器,实现零开销的线程切换。
CPU缩短延迟:
采用了复杂的控制逻辑和分支预测,以及大量的缓存
使执行单元以很短的延迟获得数据和指令。
GPU延迟隐藏:
延迟隐藏,大量线程用计算隐藏延迟。
核数/计算能力对比
CPU多核
芯片上集成的核心数量以及线程数受限
Intel i9-13900k 24核32线程
GPU多核
单核频率低于cpu,但是核数更多
GPU浮点运算能力更强
nvidia rtx4090,有16384个cuda核
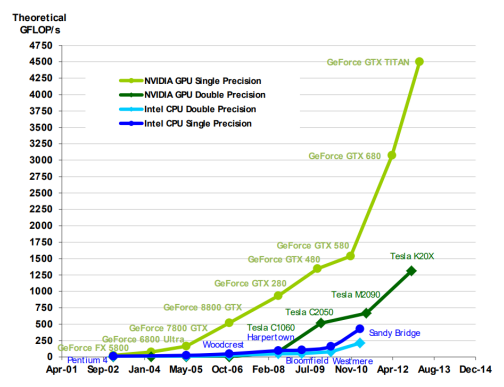
图:NVIDIA的GPU处理数据的能力
内存宽带对比
CPU内存
通过dimm插槽与主板连接
内存可扩展
GPU显存
颗粒直接焊在pcb(print circuit block,印刷电路块)
印制电路板)板上,信号完整性更好
工作频率更高
存储器控制单元数目多于cpu,总的存储器位宽更宽
总的来说,CPU和GPU的特点如下:
CPU:延迟导向设计
GPU:吞吐导向设计
CPU更适合控制密集型的串行任务,实现调度,复杂的控制流程
GPU更适合计算密集的并行计算
CPU+GPU异构:有效提高计算速度与性能
GPGPU——General Processing Graphics Processor Unit
正是因为GPU在计算方面的优势,研究人员讲GPU的应用范围拓展,用于图形渲染以外的领域。这要求把计算问题设法转化为图形计算问题求解,因此NVIDIA在2006年开发了CUDA。利用CUDA,不需要具备图形学的知识,降低学习和使用GPU并行计算的门槛,使得并行编程技术被广泛应用于科学计算、深度学习、图形处理等领域。
CUDA也支持C/C++/Fortran/Python/JAVA等多种语言,进一步方便了使用。CUDA中还封装了大量的成熟且经过充分优化的数学库。

图:CUDA支持的编程语言

图:CUDA提供的数学库和对应功能
参考资料
CUDA C Programming Guide
CUDA C Best Practices Guide
https://docs.nvidia.com/cuda
https://developer.nvidia.com/cuda-zone