【行业干货】GPU如何加速流体仿真分析?

本文摘要(由AI生成):
本文主要介绍了 GPU 在 CFD 仿真分析中的应用,包括其发展趋势、计算需求、选择 GPU 的建议、实际案例评测以及其重要性和优势。作者还分享了 Altair AcuSolve、Altair nanoFluidX 和 Altair ultraFluidX 三款软件的 GPU 加速功能,并通过三个案例进行了演示。结果表明,采用 GPU 加速可以显著提高计算速度,缩短分析时间。文章总结指出,GPU 加速已经成为数值分析的新宠,广泛应用于各个领域,特别是在 CFD 分析和渲染方面具有明显优势。
借助于GPU加速计算所提供的非凡应用程序性能,能将CFD程序计算密集部分的工作负载转移到GPU,同时仍有CPU运行其余程序代码,这样计算速度大大提升。
GPU
(一)流体仿真发展趋势与计算需求
GPU
(一)流体仿真发展趋势与计算需求
计算流体仿真力学,英文全称Computational Fluid Dynamics,缩写为CFD,兴起于近50年来,是一门相对年轻的学科。它是数值数学和计算机科学结合的产物,通过空间离散和数值求解的思路,对流体力学的各类问题进行数值实验、模拟和分析研究,以解决学习、科研或者工程设计中的问题。
作为一个强大的计算工具,CFD在产品研发的诸多环节发挥着重要作用,不仅具有低成本,还可以捕捉到实验中难以采集的信息,此外,还能提供可控的环境因素和良好的复现性。从CFD的发展趋势来看,一方面,CFD工具的发展呈现为准确度、自动化、易用性、应用性能的持续提升;另一方面,CFD也与热学、电化学、声学等学科不断融合发展,CFD工具变得更加强大。
面对一个具体的工程问题,CFD工程师在应用CFD工具进行仿真分析时的基本流程,通常可以总结为五步:前处理、网格划分、边界条件加载、求解计算和后处理。但如何去平衡计算量(网格数量)和计算时间,对于很多CFD工程师都是个挑战。
在实际解决问题的过程中,CFD工程师除了希望能选择一款称手的软件工具外,当然也希望计算机的主频越高越好,核心越多越好。但是,核心与计算速度并非线性关系,不会因为核心等比例增长。若想在单台电脑上发挥极限运算能力,还需要使用GPU加速,因为GPU加速通过协调处理器并行运算,能够极大地提升计算能力,尤其适合多个项目同时进行,这样获得的时间收益较大。
GPU
(二)流体仿真为什么要选择GPU?
GPU
(二)流体仿真为什么要选择GPU?
从1970年到今天,CFD始终向处理更高精确度、更复杂的几何结构方向发展。但现阶段,CFD软件应用于复杂流体问题方面还有待拓展,受到的阻碍主要源自以下三个方面:
隐式算法的高内存要求
一些CFD分析工程师总是希望得到完美的残差收敛曲线,以证明计算结果的可靠性,因此,他们会首选隐式算法,这意味着高内存的需求;
CFD结果对网格的强依赖性
网格的合理设计和高质量生成是CFD计算的前提条件,是影响CFD计算结果的最主要的决定性因素之一,是CFD工作中人工工作量最大的部分,也是制约CFD工作效率的瓶颈问题之一。即使在CFD高度发达的国家,网格生成仍占整个CFD计算任务全部人力时间的70%~80%。
工程流体仿真问题复杂多变
在流体力学模拟中,由于流体力学模拟是个复杂的过程,存在极端变形、自由液面以及物质运动交界面等问题,在应用网格数值模拟时,会出现网格扭曲导致计算不收敛或者产生很大的计算误差,需要重新模拟,这使得计算成本大大增加。
从CFD的发展历程看,CFD的每一步发展,都离不开计算机速度和内存的数量级提升。自1999年NVIDIA发布Geforce256图形处理芯片以来,NVIDIA的显卡芯片就开始以GPU称呼,最早是辅助CPU进行图形图像的处理,将降低CPU的运算压力,后来随着GPU性能的不断提升,其应用场景也不断拓展。近年来,随着移动计算、工业智能化的发展,GPU开始用于手机、平板电脑到无人机和机器人等平台的应用程序的加速,世界各地实验室、高校、企业以及科研院的研究人员纷纷采用GPU获得高性能计算支持,在工业领域,GPU也普遍用于仿真计算加速,尤其在汽车、航空航天、工业设备等多个高科技领域,更是掀起了新一轮的CFD应用热潮。
那么,CFD为何要选择GPU加速呢?这是为了使CFD仿真发挥最大效用,CFD工程师往往需要快速得到计算结果。而借助于GPU加速计算所提供的非凡应用程序性能,能将CFD程序计算密集部分的工作负载转移到GPU,同时仍有CPU运行其余程序代码,这样计算速度大大提升。另外,从计算性能来看,在CFD应用中单个GPU的性能远远优于CPU,基于GPU加速的CFD计算速度明显加快,很多复杂的CFD难题得以解决,因此,越来越多的CFD工程师选择GPU加速。
GPU
(三)流体仿真分析GPU选择分享
GPU
(三)流体仿真分析GPU选择分享
CFD是一个计算需求强烈的领域,GPU的选择将从根本上决定CFD分析过程的体验。在CFD分析中,工程师前期花费的时间主要在模型建立和修改上,后期真正的分析时间消耗在计算机上,因此,选择一款适合自身的CFD软件和高性能建模工作站就显得尤为重要。接下来小编软件将选择Altair的CFD工具,硬件将选择NVIDIA RTX8000,通过一些案例模型进行实际评测,希望对大家选择GPU时有所帮助。
评测案例一:
基于Altair AcuSolve™软件的GPU加速
■ 软件环境介绍
Altair AcuSolve™是一款基于GLS-FEM算法的通用热流体求解器,不但有快速良好的收敛速度,还能达到很高的求解精度,同时对网格有良好的兼容性,特别方便于复杂模型网格的划分,广泛应用于汽车、流体机械和海洋平台等工业和科学应用问题的解决。值得一提的是,最新版本的AcuSolve,不仅通过GPU加速提高了3~4倍的计算速度,同时也支持核态沸腾、热辐射、冷凝/蒸发多相流和流固耦合(FSI)等CFD难题的解决。
■ 硬件环境介绍
CPU采用单颗Intel(R) Xeon(R) Gold 6126 CPU @ 2.60GH;GPU选用NVIDIA RTX8000,它采用了NVIDIA Turing架构和NVIDIA RTX平台支持,对于追求以高稳健性、高精度为目标的CFD仿真分析带来了卓越的计算性能体验。
■ 测试模型
在新能源汽车、医疗设备、军工设备等大功率密度的应用场合,设备运行时会产生大量的热损耗,为保证设备的安全运行,需要采用各种冷却措施来对设备进行冷却,水冷是其中一种方式。以新能源车的水冷板为例,其设计直接影电池的温度均匀性,进而影响车辆的续航里程和安全性。本测试模型拥有网格数量4300万,求解方程采用湍流+固体传热组合,湍流模型选择基于SA一方程的模型,设置稳态迭代步为200步,分别采用无GPU和1块GPU加速进行计算时间对比。

动力电池水冷板模型
■ 测试结果
数据表明,无GPU加速时,水冷板分析的计算时间需要21小时;采用单块NVIDIA RTX8000加速,水冷板分析的计算时间只需要4小时。由此可见,采用Altair AcuSolve进行水冷板仿真分析,并提供NVIDIA GPU的增强支持,计算速度与无GPU加速相比提高了4.25倍。显然,这种方式对于CFD工程师快速探索水冷板的设计,并根据准确的计算结果做出决策非常有益。

计算时间对比
评测案例二:
基于Altair nanoFluidX™软件的GPU加速
■ 软件环境介绍
Altair nanoFluidX™是一款基于粒子的流体动力学(SPH)仿真工具,用于预测运动轨迹复杂的几何结构周围的流体。以整车CFD仿真为例,传统CFD方法需要建立网格耗时巨大,但Altair nanoFluidX基于粒子的特性,无需建立网格,还可基于GPU显卡计算,非常有助于工程师获得简洁而高效的CFD解决方案。
■ 硬件环境介绍
CPU采用单颗Intel(R) Xeon(R) Gold 6126 CPU @ 2.60GH;GPU选用NVIDIA RTX8000和NVIDIA Tesla V100,由于Altair nanoFluidX采用的粒子方法,其计算是由一系列的流体粒子的相互作用完成,在计算中每个粒子所执行的计算是完全相同的,而在不同的数据上执行相同的程序,恰恰是GPU计算最擅长的。

整车涉水模型
■ 测试模型
整车涉水分析是近年来新兴的CFD仿真领域,主要研究汽车以一定速度涉水时,关键零部件的进水风险,如防火墙渗水,传统的发动机进气口进水,电动汽车电气短路等问题。整车涉水模型往往需要消耗大量的计算资源和时间进行求解,以本次建立的整车涉水模型为例,拥有粒子数量为4100万,设置车速为50公里/小时、瞬态物理时间为4秒,建立单相流模型,本次测试分别采用1块NVIDIA RTX8000、2块NVIDIA RTX800、4块NVIDIA RTX8000和4块V100加速,对比计算时间。
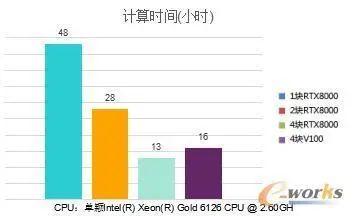
计算时间对比
■ 测试结果
数据表明,采用1块、2块、4块NVIDIA RTX8000加速,整车涉水分析分别需要花费48小时、28小时、13小时;采用4块V100,则需要16个小时。从计算时间来看,采用4块NVIDIA RTX8000加速,计算时间最少,与采用1块NVIDIA RTX8000加速相比,计算速度提升了约2.7倍。计算结果也表明,采用基于GPU加速和Altair nanoFluidX的组合方式,允许CFD工程师在一个更可接受的短时间内研究类似整车涉水这样的复杂流体问题。
评测案例三:
基于Altair ultraFluidX™软件的GPU加速
■ 软件环境介绍
Altair ultraFluidX™专用于超快预测乘用车、轻型卡车、赛车和重型车辆的空气动力特性的仿真分析,它基于格子玻尔兹曼(LBM)技术,无需建立网格,这大大缩短了建模时间,使得设计变得更加容易,同时保留了所有重要的几何细节。
■ 硬件环境介绍
CPU采用单颗Intel(R) Xeon(R) Gold 6126 CPU @ 2.60GH;GPU选用NVIDIA RTX8000和NVIDIA Tesla V100,由于Altair ultraFluidX采用的LBM方法,非常适合大规模并行架构,而采用GPU加速,可以明显提高吞吐量,达到Altair ultraFluidX的周转时间,同时降低硬件和能源成本。
■ 测试模型
对于车辆的早期开发优化,采用CFD手段无疑是最有效且最经济的方法,但这类CFD分析往往是高内存和高计算资源消耗的典型代表,需要使用GPU来优化计算性能。以此次建立的汽车虚拟风洞模型为例,拥有格子数量1亿6千万,格子的最小尺寸为1.8mm,设置车速为140公里/小时、瞬态物理时间为2秒,分别采用2块NVIDIA RTX8000、4块NVIDIA RTX8000和4块V100加速,对比计算时间。
汽车虚拟风洞模型
■ 测试结果
数据表明,采用2块、4块NVIDIA RTX8000加速,模拟汽车虚拟风洞分别需要花费14小时、8小时;采用4块V100,则需要8.4个小时。三种GPU加速中,采用4块NVIDIA RTX8000加速,计算时间最少,与采用2块NVIDIA RTX8000加速相比,计算速度提升了约0.75倍。计算结果也表明,基于GPU和Altair ultraFluidX的组合方式,可以明显加速汽车虚拟风洞分析,有效缩短汽车开发周期。

计算时间对比
GPU
(四)总结
GPU
(四)总结

作为当前最重要的三大协处理加速技术之一,GPU已经成为数值分析的新宠,广泛应用于各个领域。以流体仿真领域为例,随着CFD分析对计算能力的要求日益增高,越来越多的CFD工程师倾向于采用GPU加速,例如借助 NVIDIA RTX8000加速,能以远低于传统CPU解决方案的成本、空间和功耗,获得无与伦比的计算性能。
同时,在渲染方面,利用NVIDIA RTX8000强大的运算能力,将流场和流体构件建立数学模型,并用数字化可视化的形式表现出来,可以获得任意位置的结果值,这无疑也极大地提高了设计的精确性。e-works认为,优秀的计算性能和尖端的数值方法的组合,在更短的时间内研究复杂的流体问题,将成为未来CFD领域高效而主流的方式。
本文转载自 e-works 数字化企业
作者:吴星星 熊东旭


