原文链接:https://blog.altairjp.co.jp/ml05-recognition
Altair是一家跨国公司,所以有很多来自不同国家的人在日本工作。
当我告诉一位在我们日本办公室工作的意大利工程师 “我听到的cars和cards完全一样”时,他说“我甚至不明白日语中的筷子和桥梁的区别(音都是hashi,重音位置不一样)”。
我们为什么不使用机器学习来区分一些人难以区分的问题呢?因此,让我们试试用机器学习来进行语音识别。
发生“听到的cars和cards完全一样”这种情况的原因是,作为空气物理振动的“声音”和我们每个人在头脑中重现的“声音”是不一样的。cars和cards的舌头动作和位置不同,所以作为空气振动的 "声音 "也完全不同。
然而,作为土生土长并完全适应日语的日本人,在这两种情况下,我的脑子里都回放着 "cars "的 "声音"。大脑并没有给我们物理属性的真实数值,而是用对个体都有感觉的东西来代替所有的数值。
让我们试试语音识别
首先,像我这样把筷子和桥的声音各录了25次。
筷子(hashi)的声音
桥梁(hashi)的声音
你可能会想,"过去我经常认为我的声音录制多遍有什么意义?然而,即使你认为你的发音是一样的,但每次的实际数据是很不同的。我在下面排了三个筷子的音频波形,你可以清楚地看到,它们每次都是不同的。换句话说,大脑每次都能把不同的东西认作一根“筷子”,这很神奇。
机器学习:语音识别 - 筷子和桥的区别
将语音转换为数值数据
现在,为了使用机器学习,我们不能使用声音的原貌,我们需要把它当作有一些设计变量和反应的数值数据。我在 Altair 社区中找到了一个好的方法,我发现了一篇名为 "如何从Compose的标准OML语言中使用Python函数 "的文章。
它对wav文件做1/3倍频带处理。让我们来做一下这个。
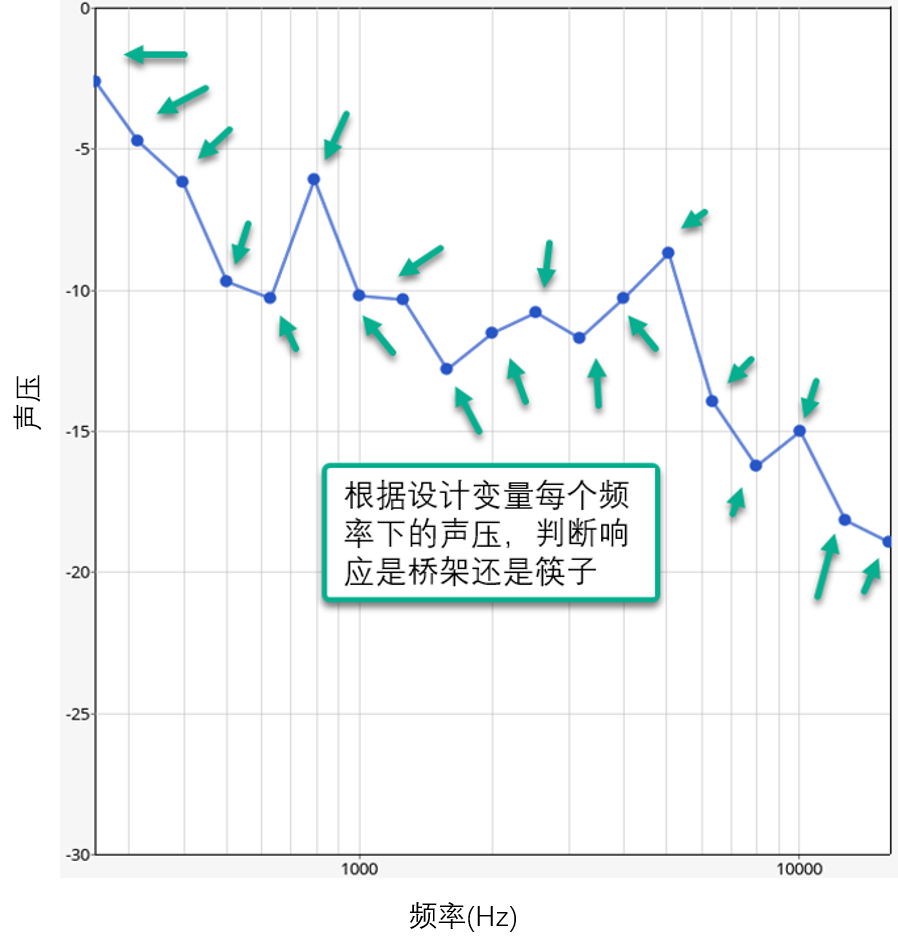
如下图所示,每个频率下的声压(我用250-16000Hz来匹配我的麦克风特性)是设计变量,而响应是决定是桥架还是筷子。
然后你可以在Excel中创建一个这样的数据集。
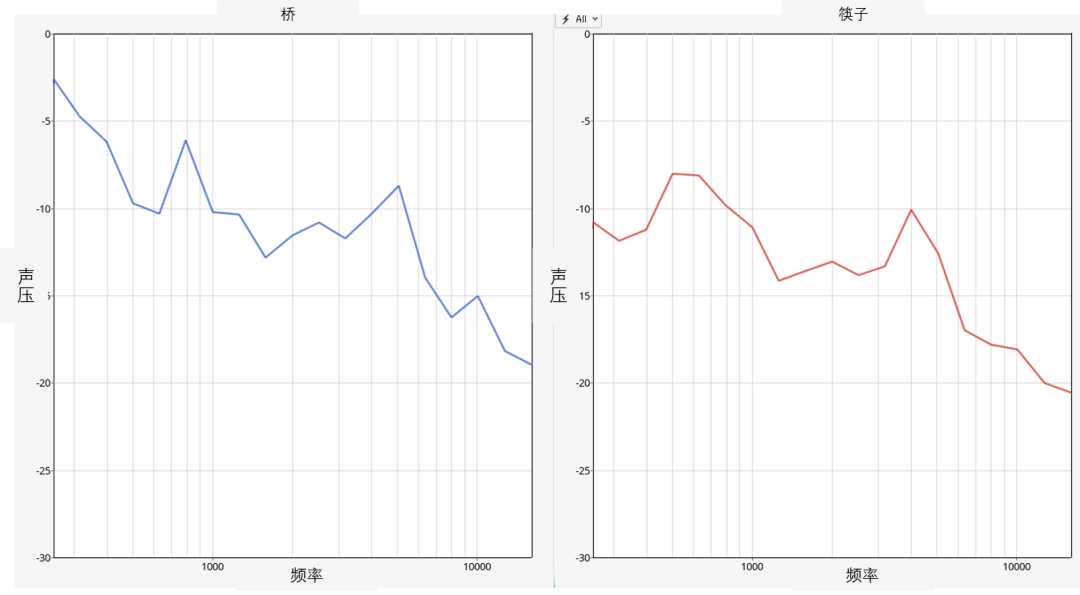
顺便说一下,这就是整个数据的样子。总体上看还是有些区别的,但一个一个地看似乎没有明显的区别,说实话,我很担心 Altair 的机器学习是否能够准确的分辨出其中的差别?
用深度学习创建预测模型
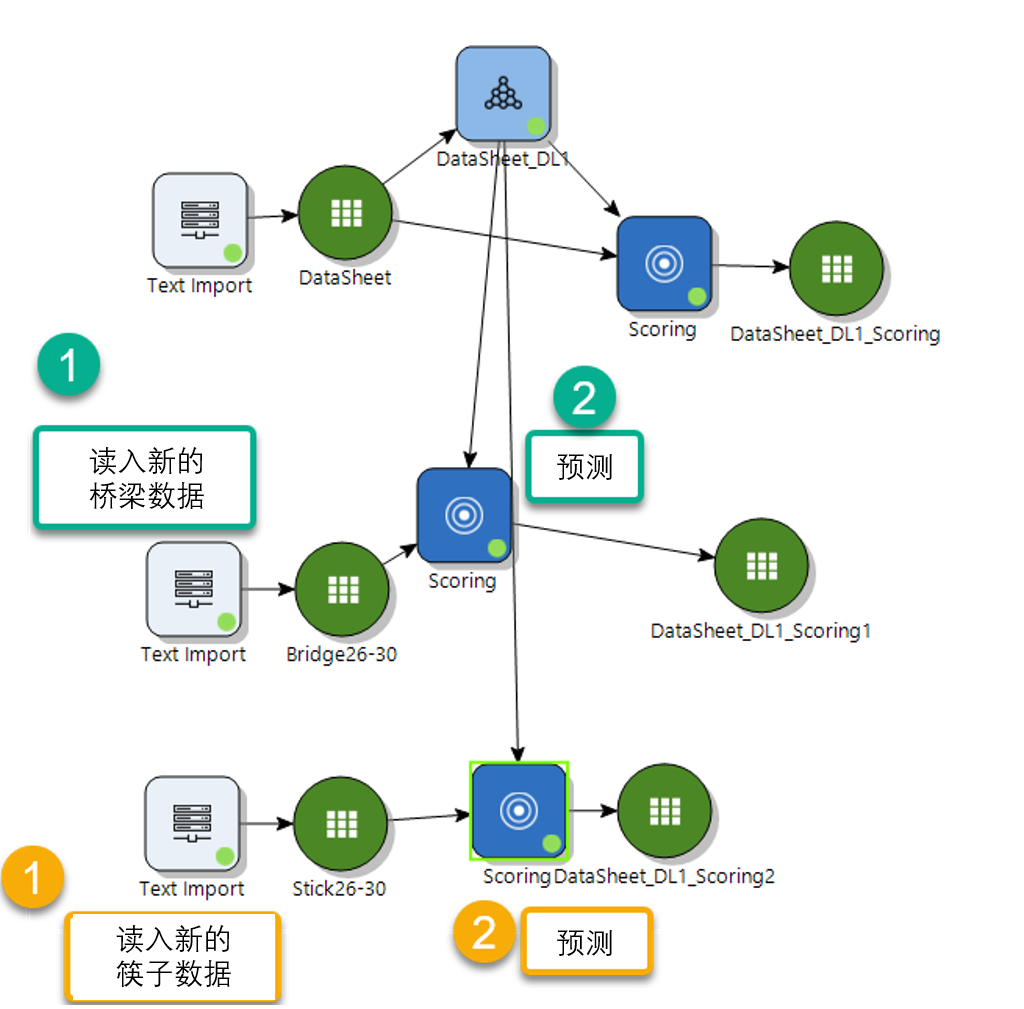
接下来就轮到 Altair Knowledge Studio 出场发挥作用了。首先,用我最喜欢的深度学习创建一个预测模型,如下图所示,这在 Knowledge Studio 中做真的很容易。
测试预测模型是否能识别桥梁和筷子
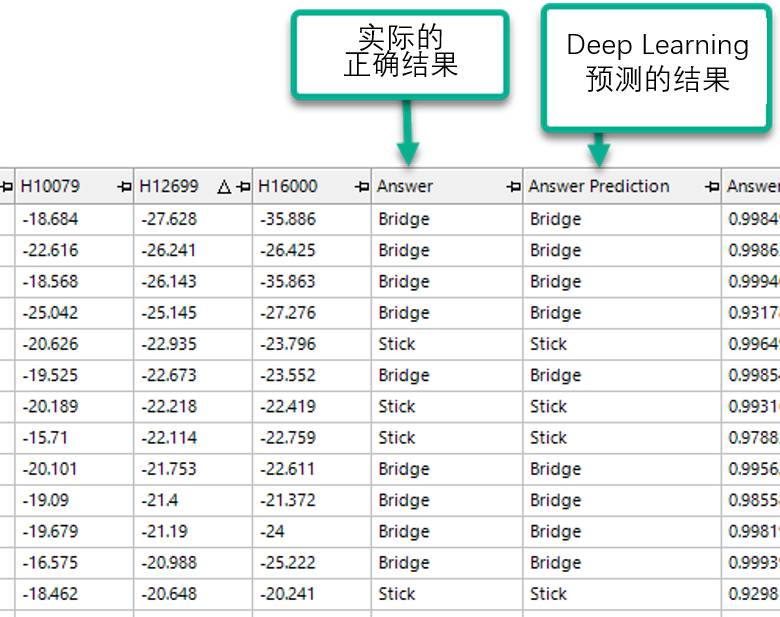
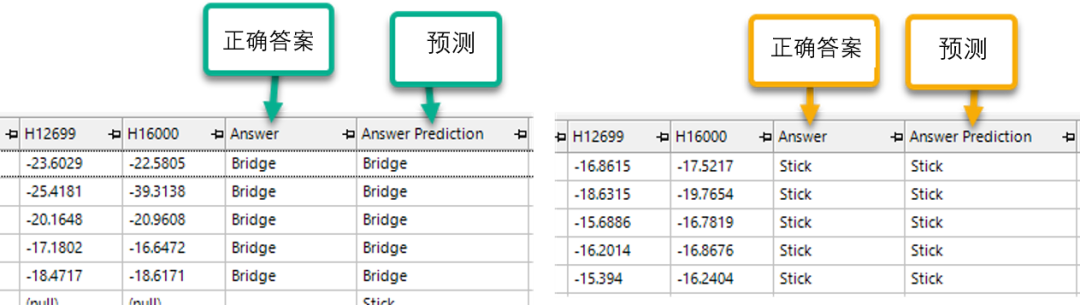
接下来,我们从训练数据的50个音频文件中分别重新录制了桥和筷子各5次,共10次,以验证深度学习模型是否能正确预测,整个过程仍然非常简单。
现在,让我们检查一下预测结果。所有的预测都准确!深度学习在预测方面做得很好。
智能手机和AI扬声器中的语音识别是嵌入了可应用在更大规模和更高分辨率条件下的预测模型。
总结
你怎么看呢?我们展示了使用机器学习来区分人们可能不容易区分的事请。我相信有很多地方可以使用机器学习,所以我希望你能想到去使用它。