力学的第四范式:数据驱动力学(data-driven mechanics)
文一:

数据驱动的计算力学
摘要:
我们开发了一种新的计算范式,我们称之为数据驱动计算,根据这种计算直接从实验材料数据和相关的约束和守恒定律(如兼容性和平衡)进行计算,从而完全绕开了传统计算的经验材料建模步骤。数据驱动求解器寻求从最接近满足守恒定律的预先指定的数据集中为每个材料点分配状态。同样,数据驱动求解器的目标是找到满足守恒定律的状态,这是最接近的数据集。由此产生的数据驱动问题由相空间中受守恒律约束的距离函数最小化组成。通过两个应用实例,即非线性三维桁架的静力平衡和线性弹性力学,激发了数据驱动范式,研究了数据驱动求解器的性能。在这些测试中,数据驱动求解器在数据点数和局部数据分配方面都表现出良好的收敛性能。数据驱动问题的变化结构也使其可以进行分析。我们发现,当数据集在相空间中越来越接近经典的物质定律时,数据驱动的解收敛到经典解。我们还说明了数据驱动求解器对空间离散化的鲁棒性。特别地,我们证明了线弹性有限元离散的数据驱动解在网格尺寸和数据集逼近方面联合收敛

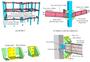
图:用边界条件对问题几何进行建模

图:(a) 拉伸加载的薄拉伸试样的模拟设置示意图。对于三维模型,样品的厚度为1mm。(b) 由两个刚性销和拉伸试样组成的三维模拟装置的等距视图。

图:收敛数据驱动解局部惩罚函数 Fe (ε,σ)值的分布。
文二:

数据驱动的力学多尺度建模
摘要:
我们提出了一个用于材料多尺度力学分析的数据驱动框架。所提出的框架依赖于力学中的数据驱动公式(Kirchdoerfer和Ortiz 2016),材料数据直接从低尺度计算中提取。特别强调了两个关键元素:材料历史的参数化和机械状态空间的最佳采样。我们展示了该框架在预测沙子行为中的应用,沙子是一种典型的复杂历史相关材料。特别是,该模型能够预测复杂非单调加载路径下的材料响应,并与平面应变和三轴压缩剪切带实验进行了很好的比较。

图:(a) 离散化宏观边值问题(b)采样期间晶胞计算的微观力学模型(c)在多尺度数据驱动框架内提出的相空间采样方法。

图:(a)二维和(b) LS-DEM 中的三维颗粒组件。(c)摩擦颗粒接触。

图:材料数据集(彩色),数据驱动模拟(◆), 和验证实验(▪) 在简单剪切中:(a)剪切应变与剪切应力(b)内能与耗散。

图:(a) 采用Anastasopoulos等人(2007)的实验断层破裂装置。(b)断层破裂的LS-DEM模拟(c)断层破裂和由此产生的剪切带的数据驱动模拟。
文三:

数据驱动断裂力学
我们为变分脆性断裂力学提出了一种新的数据驱动范式。去除了与断裂相关的材料建模假设,并将源自变分原理的控制方程与一组离散数据点相结合,从而形成了一种无模型数据驱动的求解方法。给定载荷步长的解被确定为数据集中最满足变分断裂问题产生的Kuhn–Tucker条件或适当能量泛函的全局最小化的点,从而产生变分断裂力学的局部和全局最小化方法的数据驱动对应物。两种配方都在有噪声和无噪声的不同测试配置上进行了测试,并测试了Griffith和R曲线型断裂行为

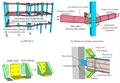
图:(a) 平衡问题的示意图和(b)显示加载/弹性卸载行为的平衡曲线的示意图。

图:双悬臂梁试验方案及几何形状。

图:使用全局最小化的Griffith裂缝的数据驱动结果:参考和数据驱动结果之间的比较(a),根据能量(b)和能量释放率(c),在加载步骤35(即,在裂纹跳跃处)的数据驱动搜索程序。
文四:

流形嵌入数据驱动机制
摘要:
本文介绍了一种流形嵌入数据驱动范式,在没有传统本构定律的情况下解决小应变和有限应变弹性问题。该公式遵循经典的数据驱动范式,寻求符合线性动量和相容性条件平衡的解决方案,同时通过最小化距离测量来保持与材料数据的一致。我们的出发点是引入全局流形嵌入,作为学习由光滑流形数学表示的本构数据的几何趋势的一种手段。通过训练一个可逆神经网络将底层本构流形的数据嵌入欧几里得空间,我们重新表述了局部距离最小化问题,该问题需要计算密集型组合搜索,以确定最接近守恒定律的最优数据点,并采用成本高效的投影步骤。同时,在不同材料对称性的路径无关弹性材料上进行的数值实验表明,当处理尺寸有限或数据缺失的数据集时,神经网络学习的几何归纳偏差有助于确保更一致的预测。

图:(A)原始距离最小化方法(Kirchdoerfer和Ortiz,2016)与(b)本文中引入的方法之间的比较。

图:通过所提出的方案获得的解字段与数据库上的最近邻投影之间的比较。在(c)和(f)中,蛮力距离最小化方案为左上方和右上方的杆提供了错误的应力状态

图:通过两种数据驱动方法(即全局嵌入(本研究)和最近邻投影)获得的解场与经典的基于模型的非线性有限元(作为基本事实)之间的比较。模拟是在平面应变条件下进行的。
文五:

热力学一致数据驱动计算力学
摘要:
在数据密集型科学的范式中,对给定物理现象的控制方程的自动、无监督发现在应用科学的几个分支中引起了很多关注。在这项工作中,我们提出了一种能够避免识别复杂系统本构方程的方法,而是通过使用实验数据以纯数值方式工作。与大多数现有技术形成鲜明对比的是,该方法不依赖于对模型的任何特定形式的假设(除了经典物理学(例如热力学第二定律)施加的一些基本限制之外),也不强迫算法在预定义的算子集中找到那些预测最适合可用数据的算子。相反,该方法能够识别动力学的哈密顿(保守)和耗散部分,同时满足基本定律,例如能量守恒或熵的正生成。针对离散力学和连续体力学的一些例子对所提出的方法进行了测试,其准确结果证明了所提出方法的有效性。

图:热摆问题的结果。两个质量的轨迹。数据(圆圈)与已识别系统的数值积分。|zmeas|=34个数据点集上的单片识别