SCI一区开源代码推荐 | 基于张量表示的机器RUL可迁移性分析和选择性迁移学习

本篇研究论文是针对数据分布和故障演化特征差异很大的不同机器的剩余寿命预测问题,提出了新的选择性迁移学习方法,用于跨机器的剩余寿命预测。适合于迁移学习、剩余寿命预测研究领域者学习者。
1 论文基本信息
论文题目:Tensor Representation-based Transferability Analytics and Selective Transfer Learning of Prognostic Knowledge for Remaining Useful Life Prediction Across Machines
论文期刊:Reliability Engineering and System ,Safety
论文时间:February 2024
作者:Wentao Mao(a,b) , Wen Zhang(a), Ke Feng(c,*), Michael Beer(d,e,f) and Chunsheng Yang(g)
机构:
(a)School of Computer and Information Engineering, Henan Normal University, Xinxiang, China, Xinxiang, 453007, China
(b)Engineering Lab of Intelligence Business & Internet of Things of Henan Province, Xinxiang, 453007, China
(c)Department of Industrial Systems Engineering and Management, National University of Singapore, 117576, Singapore
(d)Institute for Risk and Reliability, Leibniz University Hannover, Callinstr. 34, Hannover, 30167, Germany
(e)Institute for Risk and Uncertainty, University of Liverpool, Peach Street, Liverpool, L69 7ZF, United Kingdom
(f)Department of Civil Engineering, Tsinghua University, Beijing, 100190, China
(g)Institute of Artificia lIntelligence ,Guangzho uUniversity ,Guangzhou ,510006 ,China
2 摘要
3 目录
4 引言
机器故障时间的评估,即剩余使用寿命(RUL),一直是预测和健康管理领域的一个引人注目的研究课题[1]。在过去的十年里,随着机器学习的快速发展,各种算法被用于模型构建,包括浅层模型,如支持向量机(SVM)[2]、高斯过程回归(GPR)[1],以及深度神经网络,如深度信念网(DBN)[3]、长短期记忆(LSTM)[4]和卷积神经网络(CNN)[5]。
最近,已经引入了迁移学习技术来解决不同工作条件下的RUL预测问题,也称为RUL迁移预测[6,7]。有关详细调查,请参阅第2节。为了评估源域数据中的预测知识对目标域任务的益处,可迁移性正成为RUL迁移预测中的一个关键问题。然而,与故障诊断不同,RUL预测的可迁移性分析有着独特的要求。具体而言,时间退化特征比判别特征更显著,在提取预测知识时,应减少退化过程中随机性的负面影响。现有方法[5,7],假设具有相同制造规格的机器在不同的工作条件下运行时具有相似的退化过程。这一假设带来了更大的挑战,因为与不同工作条件下的退化特性相比,退化特性存在更大的差异。例如,对于像盾构机或高速列车这样的复杂机器,收集实际的运行故障数据并不容易。制造商通常在工厂或实验室收集测试机器的全寿命数据,以评估性能。然而,由于测试机器在边界条件和模型方面是对真实世界机器的简化,因此它们的退化过程可能在数据规模和退化特性方面存在显著差异。因此,评估不同机器之间的可迁移性正成为一个重要的问题。
尽管之前的一些论文[8,9]试图通过从监测数据中获得退化特征(如几何形状和趋势)来解决这个问题,但他们没有考虑固有的退化机制,如故障模式信息。如图1(a)所示,不同的故障模式可能具有相似的分级趋势,但它们的基本预测知识会有所不同。此外,这是利用故障模式信息来改进RUL预测的研究[10],但它不适用于目标机器可能具有混合或未知故障模式的机器之间的RUL预测。此外,由于工作条件的改变,相同的故障模式可能导致形状明显不同的退化过程,如图1(b)所示。因此,仅使用故障模式作为可迁移性度量可能导致负迁移,从而导致知识迁移的偏差。
图1 不同机器之间的RUL迁移预测示意图,其中(a)和(b)分别是具有相似形状但不同故障模式和具有相同故障模式但不同形状的退化过程;(c) 是本文提出的选择性知识迁移的示意图。本文以XJTU-SY滚动轴承数据集为例。
基于上述分析,RUL跨机器迁移预测的主要挑战可以概括为:
1)如何评估分布差异较大的数据的可迁移性;
2)当目标机器的故障模式未知时,如何建立知识迁移通道。
为了应对这些挑战,本文从退化特性和故障模式两个方面对其可迁移性进行了评估。然后构建一个选择性迁移学习模型,使用可迁移性分析来迁移预测知识,如图1(c)所示。
具体地,引入张量表示技术来促进可迁移性分析。张量-塔克分解能够从原始数据中提取固有信息,这有助于表示每个故障模式的共同退化趋势,以元退化趋势命名。还可以计算两个域的退化序列之间的几何结构和趋势相似性,以评估可迁移性。所提出的选择性迁移学习模型使用加权初始化和自适应冻结来自适应地迁移预测知识。理论分析表明,该模型可以显著降低目标任务预测误差的上限。
为了验证我们的方法,以滚动轴承为测试对象,使用三个基准数据集设置了一系列跨机器预测任务:XJTU-SY轴承数据集、IEEE PHMChallenge 2012轴承数据集(简称PHM)和新南威尔士大学轴承数据集(简称UNSW)。这三个数据集都是运行到失效的实验,其中提供了XJTU-SY和UNSW中的故障模式,而PHM中的故障模型是未知的。实验结果证明了所提出的可迁移性度量的合理性和所提出的方法的有效性。我们方法的实现代码可以在GitHub上找到(https://github.com/unikz22/Selective-transfer-learning-based-on-tensor-representation)。
本研究工作的主要新颖性和贡献可概括如下:
本文介绍了一种新的度量M-TDI,用于评估基于张量表示的RUL预测的可迁移性。与现有方法不同,M-TDI在交替优化的背景下对预测知识的相关性进行了动态评估。值得注意的是,该度量在处理退化随机性方面表现出稳健的性能。据我们所知,这是在RUL预测领域内探索可迁移性分析的开创性工作。
本文介绍了一种预测不同机器间RUL迁移的创新方法。利用可迁移性评估,所提出的方法可以有效地迁移知识,尽管数据分布存在显著差异。值得注意的是,即使在面对目标机器的故障模式不存在的情况时,这种方法也表现出色,突出了其在实际应用和部署中的巨大潜力。
本文为所提出的方法建立了预测误差的上限。这个上限是该方法将提高RUL迁移学习可靠性的理论保证。此外,这一界限为具有微调的回归迁移学习背后的原理提供了有力的支持。据我们所知,本研究对RUL迁移学习的可靠性进行理论分析的初步尝试。
5 方法框架
目前对RUL预测的研究存在几个局限性。
首先,大多数方法无法处理不同机器之间的显著分布差异,并且它们在目标域中也缺乏故障模式信息。
其次,目前的可迁移性分析方法主要关注特征相似性、分布对齐和参数显著性,但它们并不足以表示特定迁移学习任务所要迁移的领域知识。
最后,在没有与预测任务联合分析的情况下,独立评估可迁移性,这可能导致知识迁移有偏差,降低迁移的可靠性。
本文试图从理论和实践两个方面来解决这些局限性。
从理论上讲,本文利用张量优化来寻找本质的退化信息和有效的迁移通道,这可以建立一种新的可迁移性分析研究范式,即将静态可迁移性度量转换为动态可迁移性,然后用预测任务对其进行优化。
从实践角度来看,本文设计了一种选择性迁移策略,即使目标任务中的故障模式信息不可用,该策略也有助于评估数据分布差异较大的RUL值。
本节所提出的一种新的跨不同机器的RUL迁移预测方法,如图2所示。该方法由三部分组成:
(1) 基于张量表示的元退化趋势提取;
(2) 基于故障模式和退化特征构建可迁移性度量;
(3) 选择性迁移学习网络与基于交替优化的训练算法。
 图2 拟提出方法的流程图
图2 拟提出方法的流程图
6 实验验证
选择滚动轴承作为验证对象,在PHM、XJTU-SY和UNSW三个基准数据集上进行了实验验证。编程环境为Matlab2014a和Python3.7,计算机配置i7-4790处理器和16G内存。
 图3 本文中使用的试验台,(a)用于PHM数据集的PRONOTIA平台[31],(b)XJTU-SY平台[32],(c)UNSW数据集平台[33]
图3 本文中使用的试验台,(a)用于PHM数据集的PRONOTIA平台[31],(b)XJTU-SY平台[32],(c)UNSW数据集平台[33]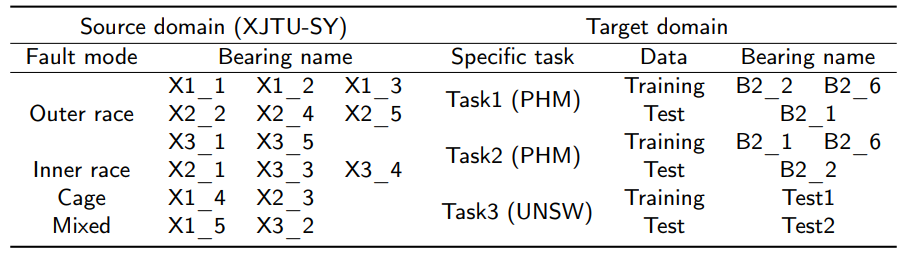
PHM数据集中的故障模式是未知的,而XJTU-SY和UNSW数据集中的故障模式已经给出。因此,通过将XJTU-SY数据集设置为源域,将PHM和UNSW数据集分别设置为目标域,构建了两组跨机器的迁移预测任务。
如表1所示,PHM数据集中的两个轴承(B2_1和B2_2)被随机选择作为测试轴承,交替构建两个特定的任务。值得注意的是,只有快速退化数据用于模型训练。任务1中的目标轴承B2_2和B2_6分别具有55个和18个处于快速退化状态的样本。在任务2中,目标轴承B2_1具有41个样本用于模型训练。尽管轴承B2_1、B2_2和B2_6可能具有不同的分布,但它们仍然在相同的工作条件下运行,并且它们的退化特性具有较小的发散性。与第二工况下的其他轴承相比,轴承B2_1和B2_2都具有更长的退化过程。因此,将这两个轴承分别设置为任务1和任务2中的目标轴承,有望提高更好的可视化效果。
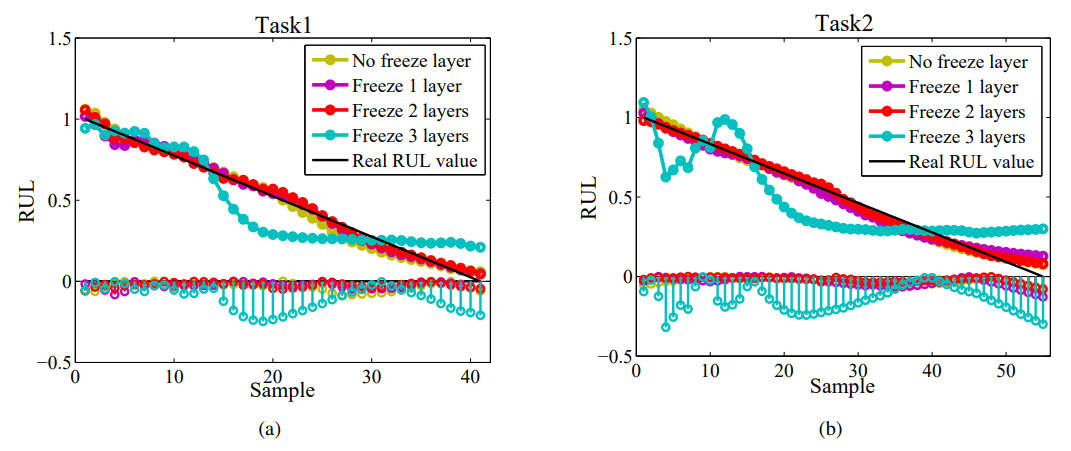 图4 (a)任务1和(b)任务2冻结不同层的RUL预测结果
图4 (a)任务1和(b)任务2冻结不同层的RUL预测结果 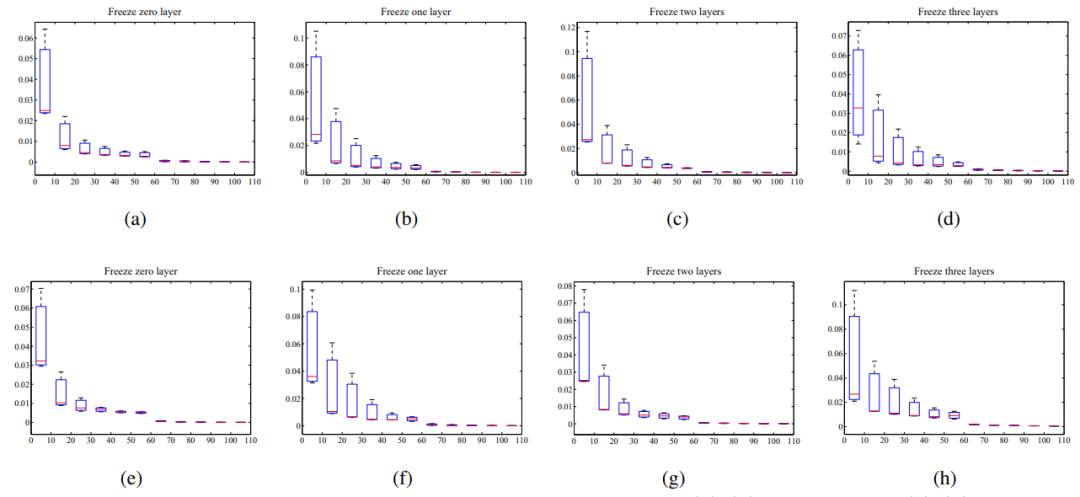 图5 冻结不同层的损失下降方框图,其中(a)-(d)在任务1上,(e)-(h)在任务2上。
图5 冻结不同层的损失下降方框图,其中(a)-(d)在任务1上,(e)-(h)在任务2上。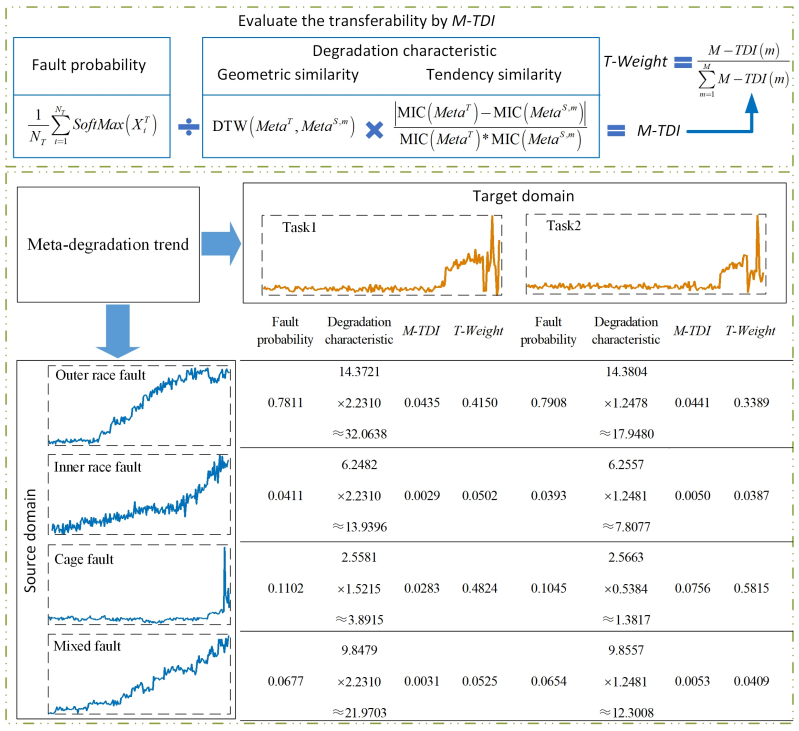 图6 对任务1和任务2的T-Weight的详细计算。由于T-Weight的最大值与最小值之间的差异大于1/4,建议根据式(8)冻结两个或更多层
图6 对任务1和任务2的T-Weight的详细计算。由于T-Weight的最大值与最小值之间的差异大于1/4,建议根据式(8)冻结两个或更多层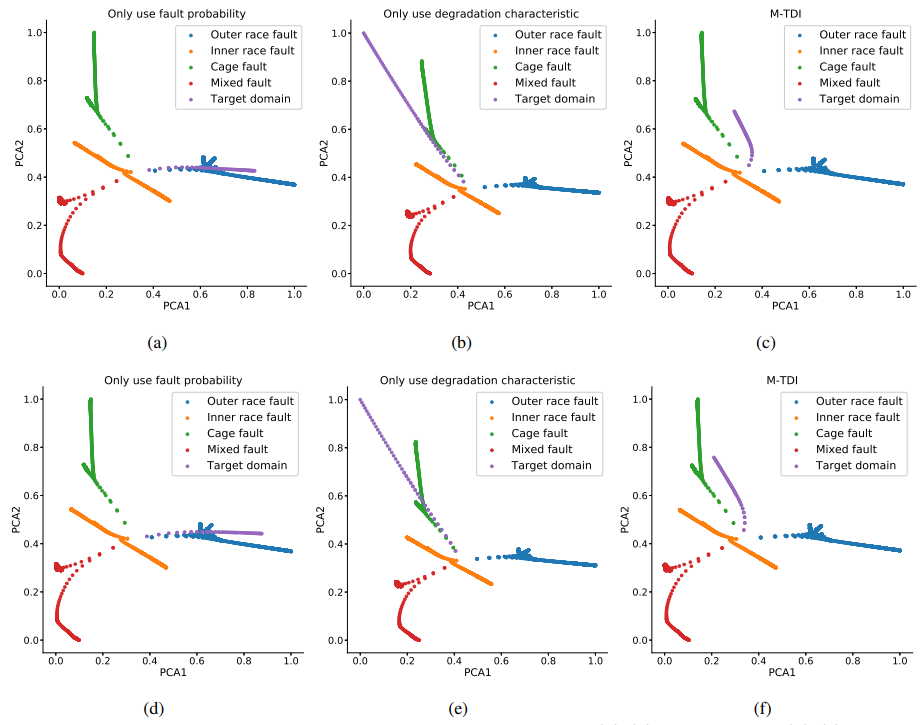 图7 对应于不同度量的特征分布,其中(a)-(c)在Task1上,(d)-(f)在Task2上
图7 对应于不同度量的特征分布,其中(a)-(c)在Task1上,(d)-(f)在Task2上注:下列所提及等式可点击阅读原文跳转进行对应查看。
等式(6)由两部分组成(分子和分母)。分别使用分子和分母设计了两个新的度量(命名为故障概率和退化特性)。图6显示了这三个度量的值,图7显示了相应的特征分布。当仅使用故障模式时,目标域数据被分类为外部竞争故障(任务1为78.11%,任务2为79.08%)。但如果使用退化特征,目标域数据在几何形状和趋势方面与源域中的保持架故障数据更相似。相反,所提出的度量M-TDI,如T-Weight所反映的,可以利用故障模式信息和退化特性,从而提供可迁移性的综合评估。数值结果可以由图7精确反映。当仅使用故障概率时,目标域数据的特征分布接近源域外圈故障数据的分布,如蓝线上的紫色线所示(外圈故障)。在图7(b)和(d)中,紫色线转向绿色线(保持架故障),表明目标域数据在退化特征上与保持架故障数据具有更好的相似性。矛盾的结果与图6中的结果相同。无论使用哪种度量,预测结果都不令人满意。M-TDI(T-Weight)可以在这两个指标之间进行权衡,并促进预测知识的迁移。
 图8 消融实验的RUL预测结果,其中(a)在任务1上,(b)在任务2上。
图8 消融实验的RUL预测结果,其中(a)在任务1上,(b)在任务2上。除了式(6)之外,提出的方法还包括张量优化。进行了以下消融实验:
1) 没有张量优化;
2) 没有退化特征的度量;
3) 没有故障概率的度量;
4) 没有M-TDl,即仅使用目标域数据微调预测模型。
消融实验的结果如图8所示。没有张量优化的结果显著减小,这表明高质量的特征表示可以有助于知识迁移。然而,紫色线显示了最差的预测效果,表明需要适当的迁移策略。此外,没有劣化特性的迁移(深绿色线)不能实现良好的性能。这意味着只有传递故障模式信息才会使知识发生偏差。无故障概率的迁移也有类似的效果。相比之下,所提出的方法可以从这两个方面利用可迁移性,并获得有利的迁移效果。
 图9 式(9)中不同参数设置对MAE和RMSE的灵敏度,其中(a)-(c)执行任务1,(d)-(f)执行任务2。
图9 式(9)中不同参数设置对MAE和RMSE的灵敏度,其中(a)-(c)执行任务1,(d)-(f)执行任务2。 图10 不同网络设置对MAE和RMSE预测误差的敏感性评价,其中(a)-(c)为Task1, (d)-(f)为Task2。
图10 不同网络设置对MAE和RMSE预测误差的敏感性评价,其中(a)-(c)为Task1, (d)-(f)为Task2。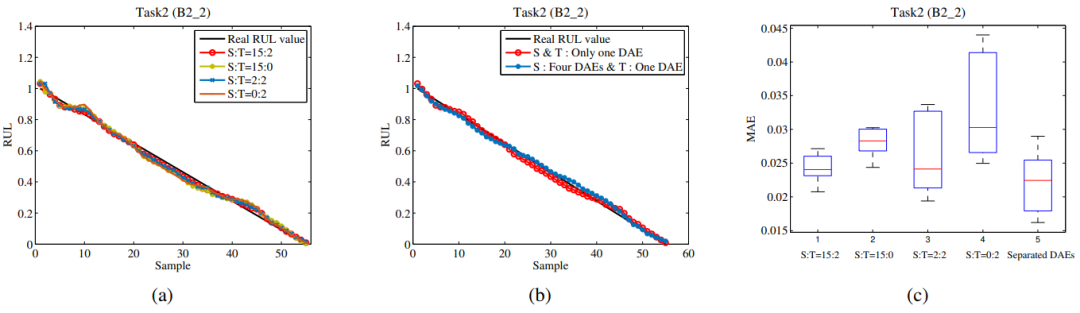 图11 任务2的预测结果,其中(a)轴承样本的不同比例,(b)分离的DAE和(c)误差方框图
图11 任务2的预测结果,其中(a)轴承样本的不同比例,(b)分离的DAE和(c)误差方框图
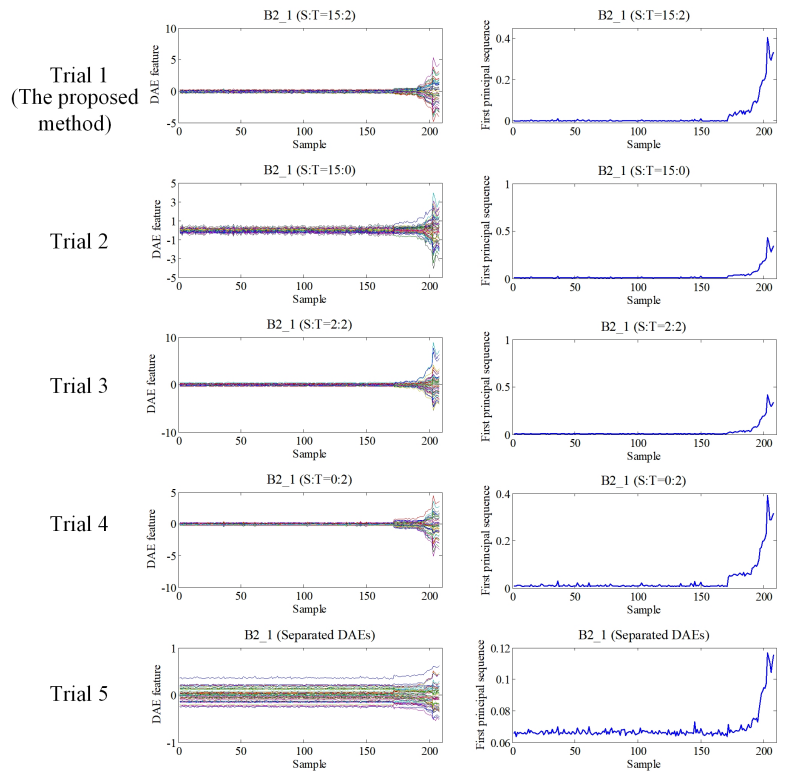
图12 PHM数据集中目标轴承B2_1的DAE特征(左列)及其第一个主序列(右列)。这里PCA用于一维可视化
试验1的设置与本文中使用的设置相同


表4 所有15种方法预测效果的数值结果。RMSE和MAE越低,得分越高,表示预测性能越好。
对于任务1和任务2,由于具有较少代表性能力的特征,方法4-7得到的结果比所提出的方法差得多。对于分布差异较大的数据,将数据映射到同一特征空间以迁移预测知识并不容易。尽管方法1-3采用了能够更好地反映退化特性的深度学习技术,但它们仍然不如所提出的方法。一个有趣的现象是,这三种方法的预测效果与方法8和10-11的预测效果接近。这表明,一旦特征表示足够好,仅仅进行微调或域自适应就不能显著提高预测性能。需要一种更合理的迁移策略,方法9采用了子空间自适应加微调的策略进行了验证。对于方法12-14,它们的结果优于方法8和方法10-11,这表明退化知识的选择性迁移更有利于数据分布差异较大的目标任务。然而,它们的预测性能仍然比我们的差,因为这些方法没有进行全面的信息提取和表示。基于样本显著性的可解释性分析,方法12实现了预测知识的有效迁移,提高了迁移效果。但它的结果仍然比我们的差,因为这种方法没有集成故障模式信息,而故障模式信息对跨机器的RUL预测至关重要。
 图13 总共13种方法的RUL预测结果,其中(a)-(c)在任务1上,(d)-(f)在任务2上,(g)-(i)在任务3上
图13 总共13种方法的RUL预测结果,其中(a)-(c)在任务1上,(d)-(f)在任务2上,(g)-(i)在任务3上
尽管UNSW数据集是在实验室收集的,但它主要涉及模拟真实世界运行条件下的轴承故障(剥落)严重程度评估。同时,与其他数据集相比,其退化过程表现出更多的随机性和噪声干扰。所有方法对任务3的预测性能都明显恶化。在所有14种方法中,只有方法12和方法13两种方法能达到一定的预测效果。其他11种方法都失败了,要么导致大的函数(方法4,9-10),要么导致明显失真的预测值(方法1-3,5-7,8,11,14)。特别是对于后者,有些方法基本上保持不变或功能较小,这是完全没有意义的。这种比较效应源于数据分布差异大,对复杂退化数据的特征提取较少。方法8和10-11的结果表明,只有微调或域自适应不能处理具有大分布偏差的预测任务。尽管在PHM数据集上表现良好,但方法14仍然得到了更差的结果,这确实让我们感到惊讶。由于方法14利用鉴别器输出来实现加权预测和微调,其迁移策略无法支持复杂退化过程的知识迁移。由于选择性或集成迁移策略,方法12-13的结果优于其他深度迁移学习方法。然而,他们的结果仍然比我们的结果差,因为他们没有集成故障模式信息,这对于跨机器的RUL预测至关重要。相反,所提出的方法不仅分析了源域数据的可迁移性,而且使用可迁移性度量来促进知识迁移。然后可以实现有针对性的知识迁移,以提高迁移学习的效果。合理的可迁移性分析被认为在跨机器的RUL迁移预测中发挥着关键作用。
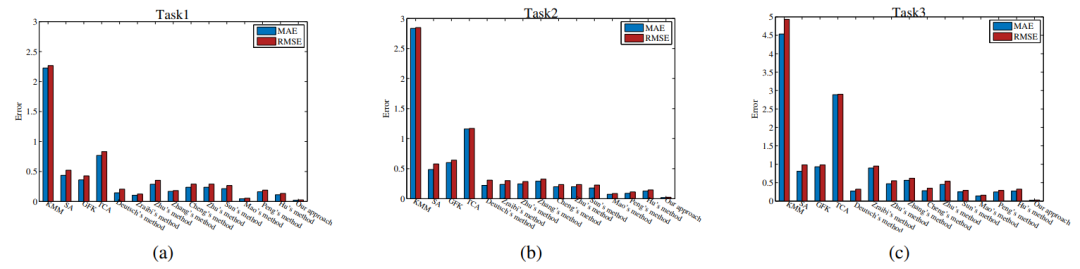 图14:总共15个方法的RMSE和MAE,其中(a)在Task1上,(b)在Task2上,(c)在Task3上
图14:总共15个方法的RMSE和MAE,其中(a)在Task1上,(b)在Task2上,(c)在Task3上观察到的性能差异也可以归因于对数据规模的依赖。深度学习方法通常需要大量数据来从退化过程中的噪声和其他随机干扰中提取退化知识。相反,所提出的具有可迁移性分析的知识迁移机制可以显著提高迁移效率,减少对高数据量的需求,其优点如下:
1) 采用核心张量来明确表示退化知识,减少退化过程中的随机干扰; 2) 使用核心张量作为LSTM的输入还可以提高初始特征质量,避免噪声干扰; 3) 所设计的交替优化方案有利于确定最优张量表示和知识迁移效果,避免了特征退化,降低了小规模数据的过拟合风险; 4) 基于M-TDI的迁移策略能够通过选择性冻结和微调有效地迁移预测知识,这进一步避免了对大规模数据的需求。
在这个实验中,一个方位的训练数据只是几十到一千个样本。在这个数据尺度上,我们的方法比其他深度学习方法的预测误差低得多。
我们用错误的故障概率进一步检验了所提出方法的可靠性。在表1中列出的三个任务中,只有任务3(UNSW)在目标域中具有已知的故障模式。因此,我们使用任务3进行验证。通过CNN分类器,我们可以得到目标域数据的故障概率值:0.8313(外圈故障)、0.0293(内圈故障)、0.0545(保持架故障)、0.0849(复合故障),其中分类结果与真实信息保持一致。我们进一步将概率值修改为不正确的值,如表5中所示。预测结果和收敛性能如图15-16所示。以外圈故障为例,图15还说明了T-Weight值的变化。

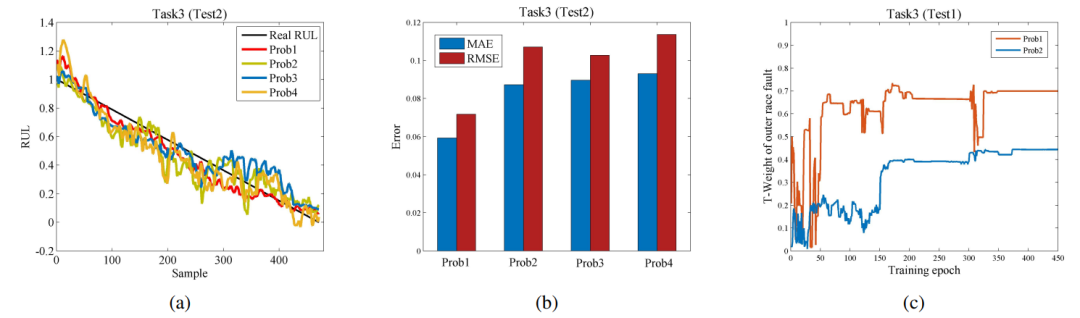 图15 具有不同故障概率值的Task3上的RUL预测性能,其中(a)和(b)分别是测试轴承Test2上的预测RUL值和相应的预测误差,(c)是训练轴承Test1上外圈故障的T-Weight值。
图15 具有不同故障概率值的Task3上的RUL预测性能,其中(a)和(b)分别是测试轴承Test2上的预测RUL值和相应的预测误差,(c)是训练轴承Test1上外圈故障的T-Weight值。
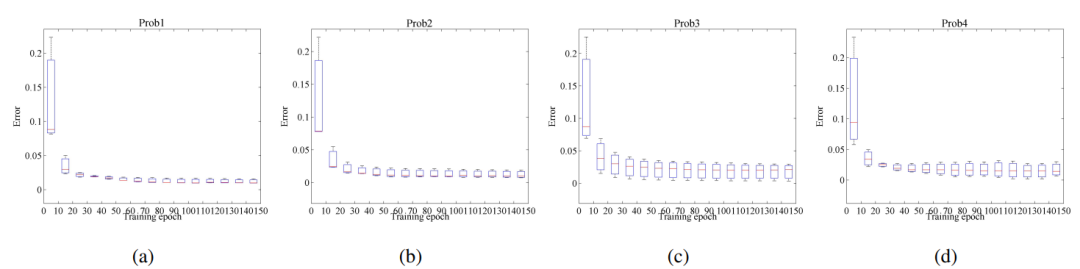 图16 具有不同故障概率值的任务3的损失下降方框图
图16 具有不同故障概率值的任务3的损失下降方框图
显而易见,具有错误故障概率的预测结果比所提出的方法更有偏差,在训练过程中收敛不稳定。然而,与表4相比,它们的预测误差仍然低于其他比较方法(方法1-14)。我们还从图15(c)中观察到一个非常有趣的现象。即使外圈故障的初始概率值设置得很小,相应的T-Weight值仍然可以随着训练而攀升到更高的值。这一结果有效地证明了所提出的方法的自修复能力,或者说可靠性。尽管存在错误的故障概率,但该方法可以通过引入退化特征信息自适应地识别有用的预测知识,并通过交替优化方案实现有效的知识迁移。结果,可以尽可能地保证迁移效果以及RUL预测性能。
7 结论
编辑:董浩杰
审核、校对:李正平、张勇、王畅、陈凯歌、赵栓栓、曹希铭
该文资料(RUL选择性迁移学习)搜集自网络,仅用作学术分享,不做商业用途,若侵权,后台联系小编进行删除。


