用好工业大数据的基础是数据质量

工业大数据的重要作用是支持智能决策。我们可以把计算机的智能决策抽象成一个数学公式,即计算Y=F(X)。我们进行这种计算时,潜伏着一个基本的要求:X和Y是与某个特定对象相关联的参数。比如,X某个产品的性能,X是生产这个产品时的工艺参数。X、Y背后都与某个特定的产品关联着。显然,如果对应关系出现差错,计算就会出现问题。
怎么才能对应好呢?要解决这个问题,要从源头上考虑问题。
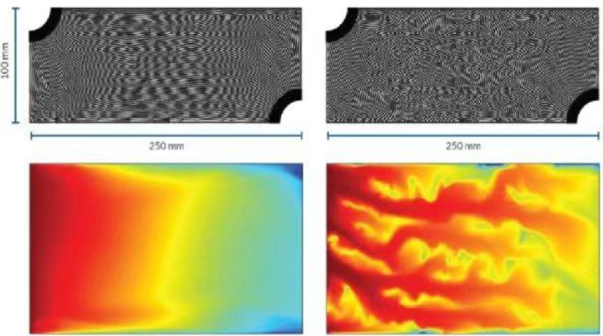
首先要从提高生产过程的标准化和稳定性做起。当我们计算Y=F(X)时,默认一个条件:X确定之后Y就确定了。如果生产过程标准化程度和稳定性差,往往意味着X确定之后生产过程仍然有较大的“自由度”。这就意味着,对Y存在不可见因素的影响。这时,X确定了Y也不能确定。由此可见,管理不好的企业,难以有效地利用工业大数据。
其次要关注数据的采集过程。数据采集时,如果是人类输入数据,则数据的精度和时间往往就难以把握。所以,在数据质量要求高的过程,数据必须是机器自动采集的。机器采集的本质好处,是能把生产和采集的过程统一起来,让数据空间准确描述物理空间。另外需要关注的是:如果人们对数据的精度要求高,就要考虑数据采集过程本身带来的干扰。这不仅需要采集过程的标准化和稳定性,还要增加用于研究采集过程干扰的数据。
第三要解决产品在不同工位的数据对应问题。在流水线上生产时,产品在每个工位上的数据都要对应好。产品从一个工位走到另外一个工位时,是容易跟丢的。所以,物料移动的自动化很重要。这种条件下,让机器自动地记录,产品就不容易跟丢。所以,我看一个企业的智能化程度时,往往比较关注厂内物流的自动化。
第四个要解决的是时间的一致性问题。有些产品的质量或性能与加工或等待的时间有关。从加工设备采集数据时,可能采用设备自己的时钟。如果设备的时钟不统一,加工或等待时间就难以准确计算。另外,有些时候我们需要分析因果关系,而因果关系的属性之一是“原因在先\结果在后”。设备时钟不统一时,先后关系和延迟时间就难以判断,从而严重影响数据质量。
如果我们不从源头上解决问题,很可能花了很多功夫做数据分析,最后无功而返。如果不在数据质量上下功夫,一味地关注模型或算法,很可能是缘木求鱼。遗憾的是:很多人就是这么做的。从上面的分析也可以看出:应用好工业大数据,并非仅仅是数据工作者的事情。
技术工作者最怕的是技术逻辑中的断点。从事智能化工作时,可能需要大量的数据;一条数据有问题,可能会影响整个系统的稳定、可靠性。数据质量问题就像一粒尘土,当它摆在技术人员面前时,可能会成为阻碍技术走向成功的高山。数据质量决定于应用场景。应用场景不同,数据质量的内涵就不一样。常见的内涵包括数据的精度、种类、采集和传递频度、存储的周期等。所以,数据的高质量有赖于数据的存储和处理能力。
做数据分析工作有时就像(就是)搞科学研究,数据质量决定了你能够研究的深度。数据质量达不到一定的程度,有些问题就没有办法解决。反之,如果数据质量高到一定程度,研究工作就可能带来突破。从某种意义上说,数据分析师机会的多寡,决定于数据质量。
几年前讨论“工业大数据”概念时,我提出一个观点:工业大数据时代的本质,是数据质量足够高的时代。我们推进企业的数字化转型,本质上就是让计算机多干活;在工业场景下,计算机干活的关键是安全、稳定、少出错;而安全、稳定、少出错的关键,是有较高的数据质量;如果数据的采集、存储、处理能力不足,数据质量就难以提升;工业大数据时代,让我们有条件解决数据质量问题。