基于机器学习和代理模型的CAE参数优化模型建立

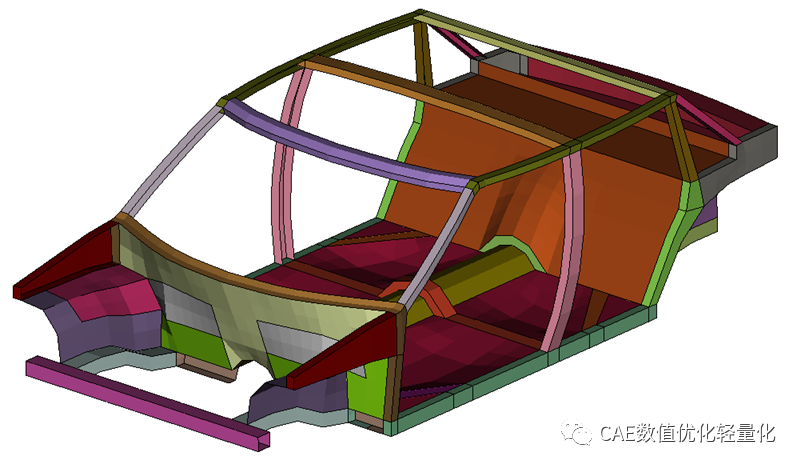
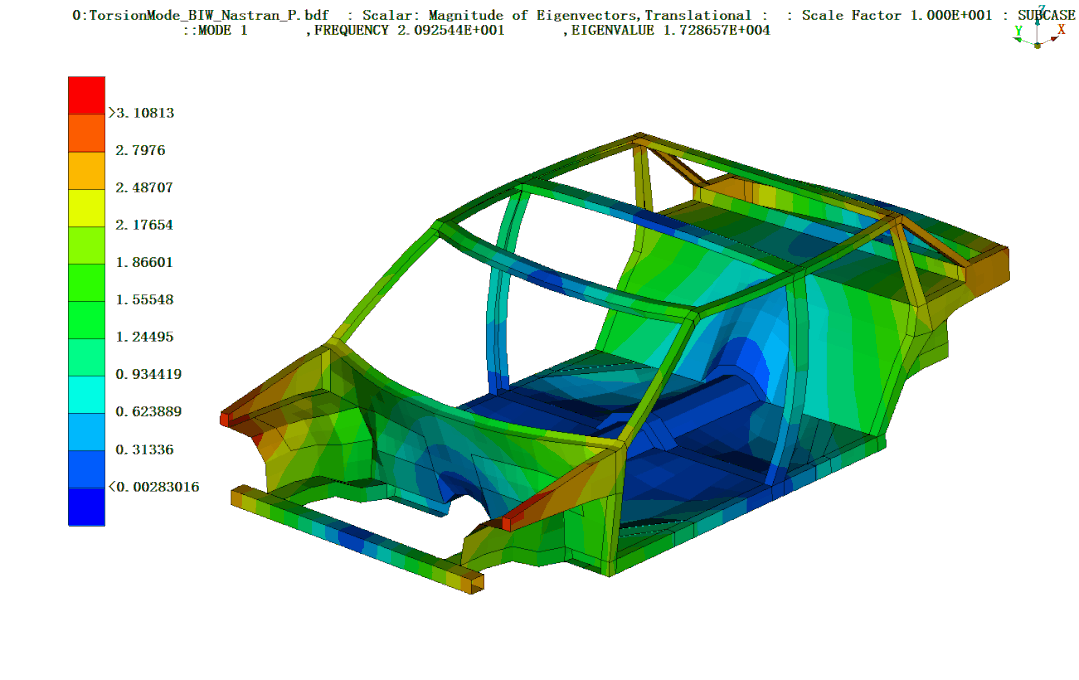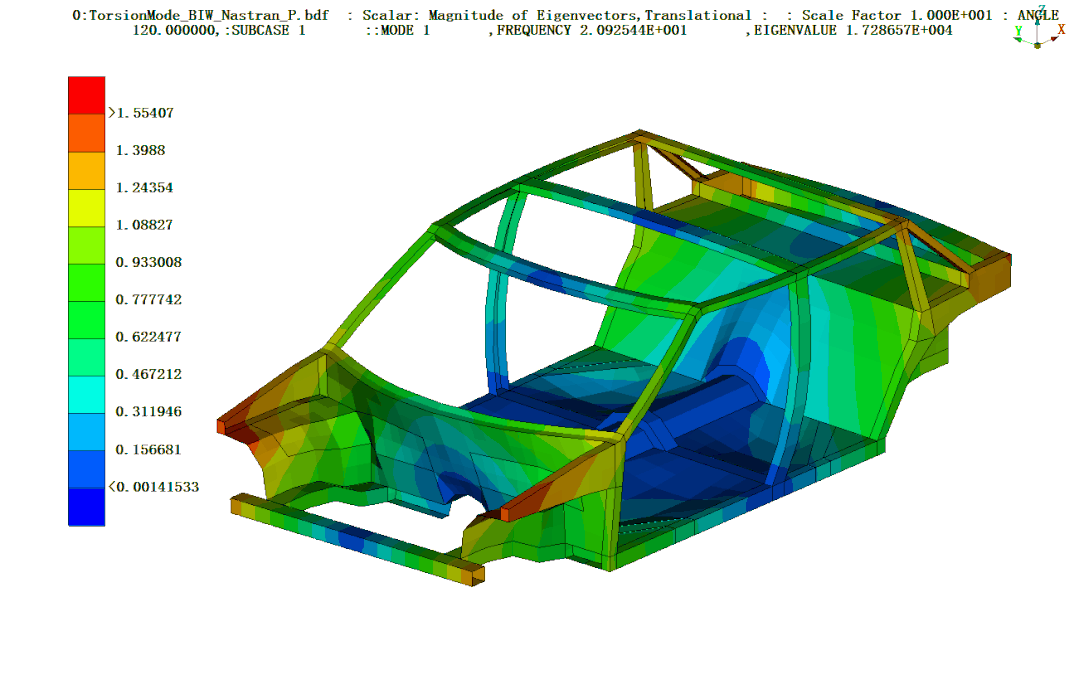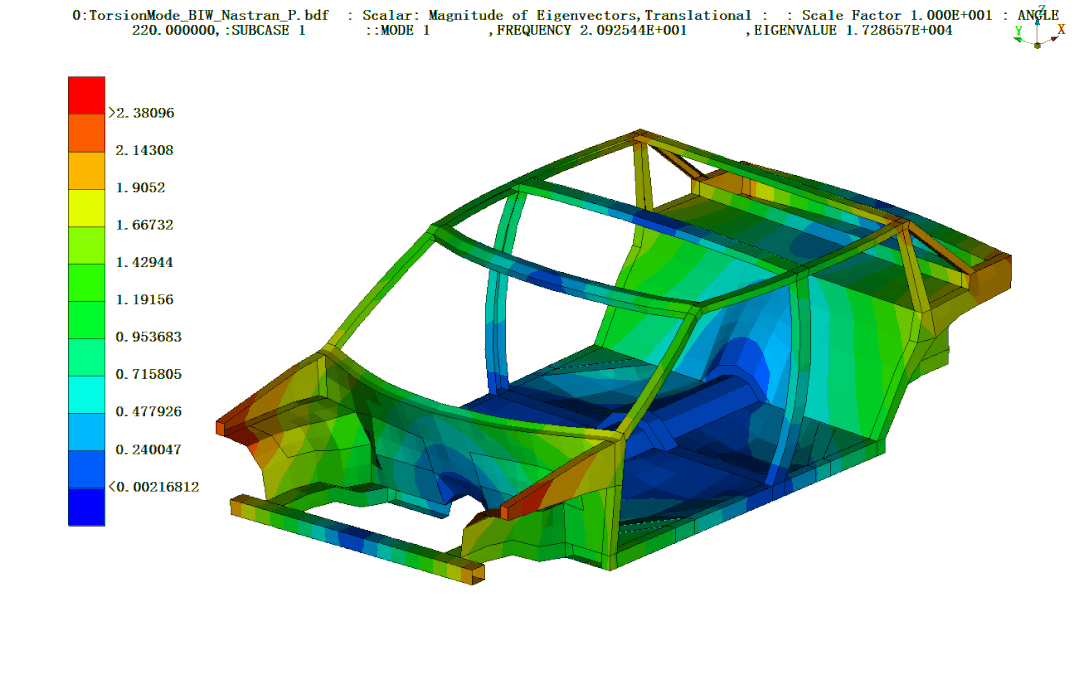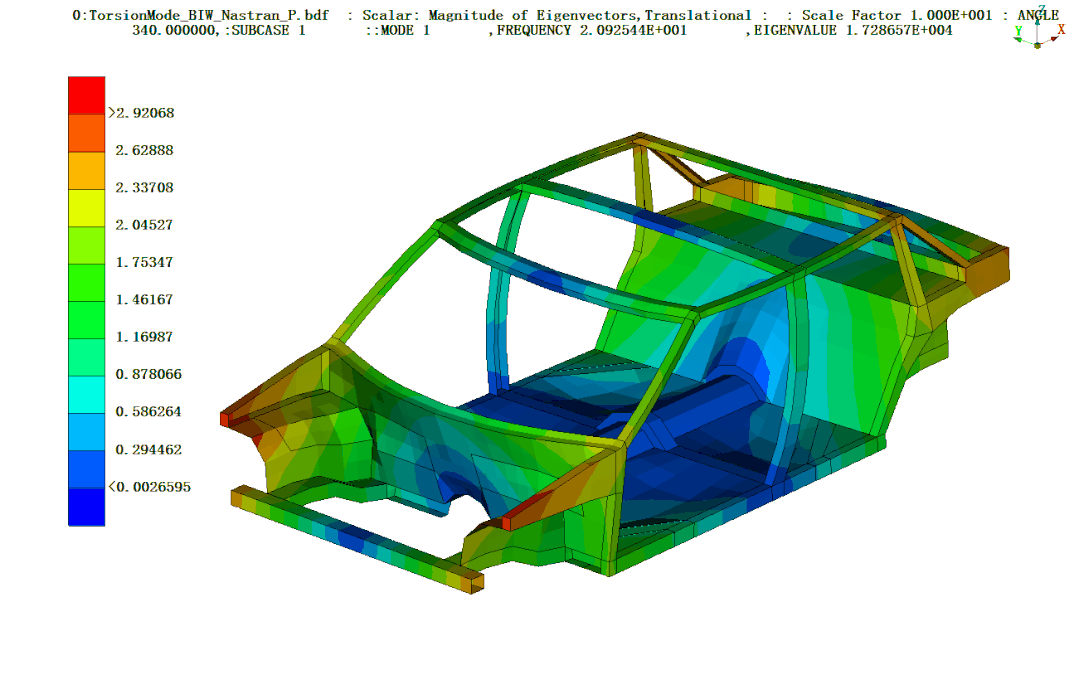
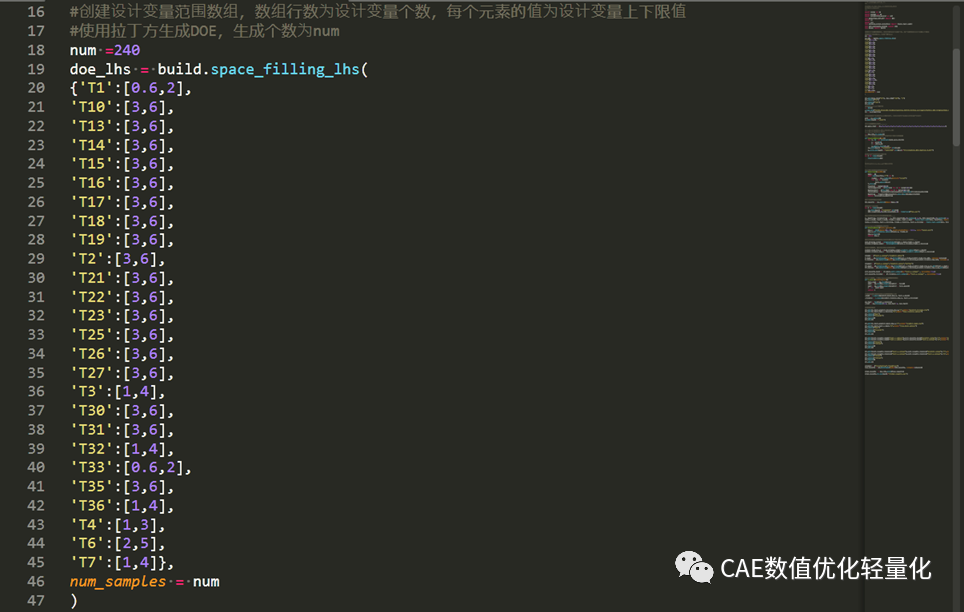

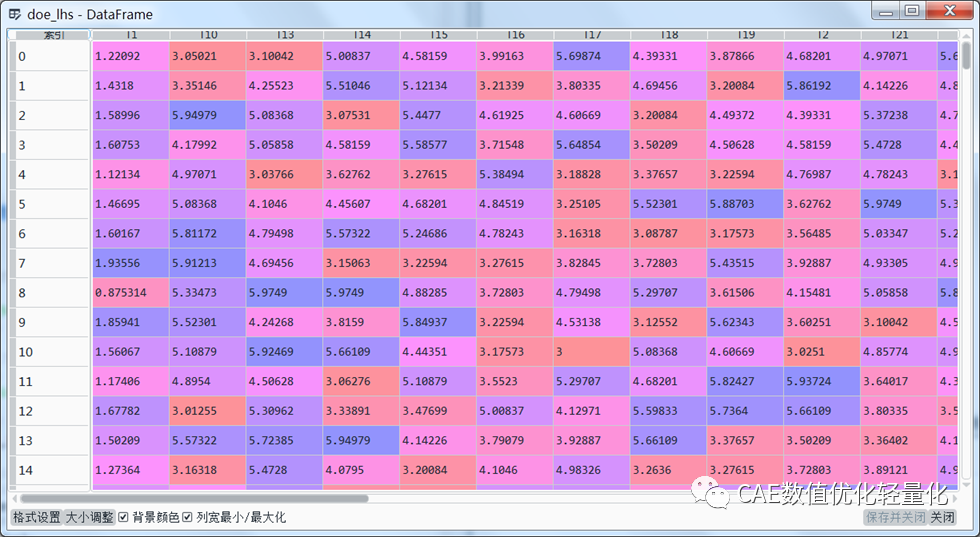
全部DOE样本点数据集:
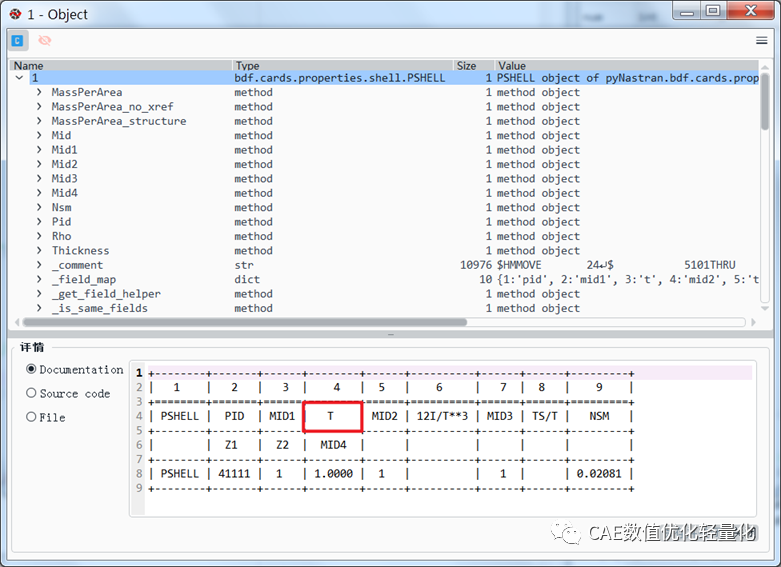
读取nastran计算文件,并获取所有属性集。
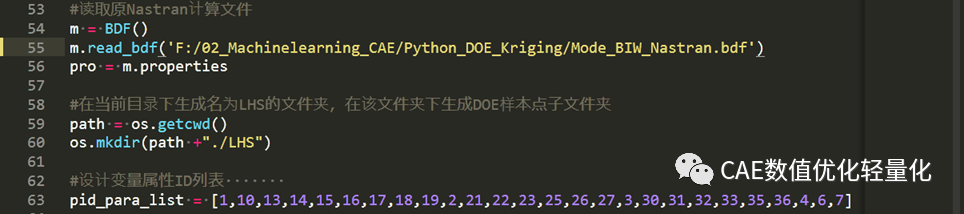
这里需要对对应的部件属性进行厚度修改,修改数值为DOE样本点中数值。
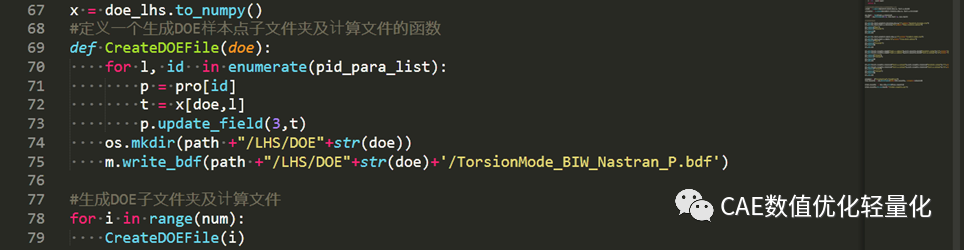
定义一个生成DOE计算点的函数,并生成DOE样本计算文件。
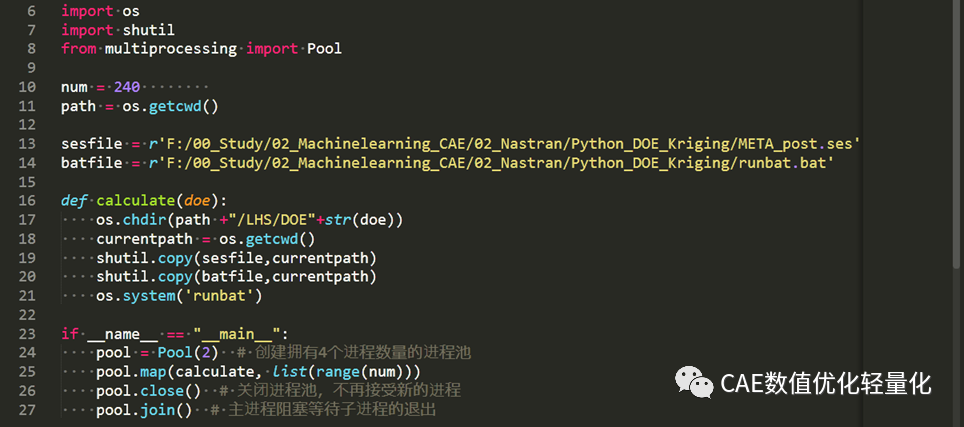

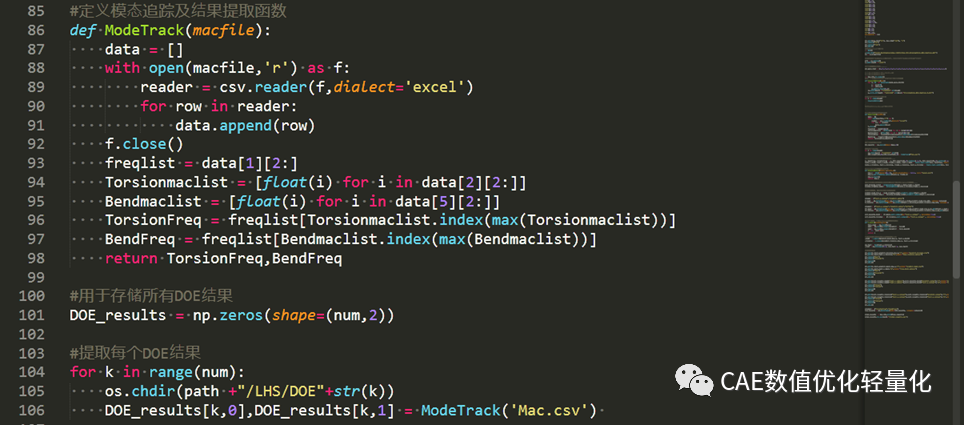
定义一个模态追踪函数,通过每个DOE样本点的结果文件mac来获得弯曲模态和扭转模态结果。并将所有结果汇总到一个数组结果中。
二.机器学习模型训练


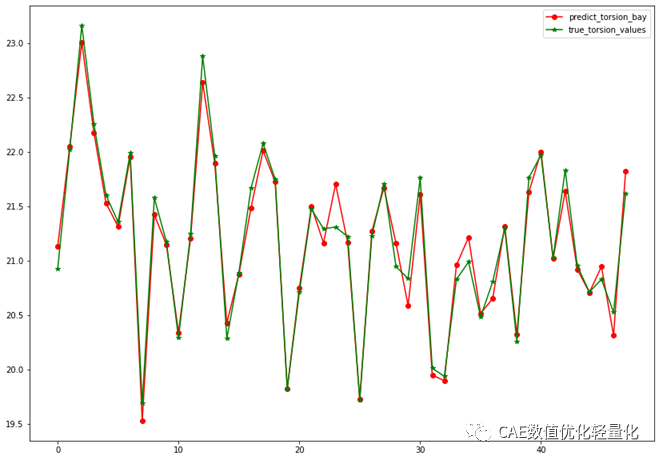
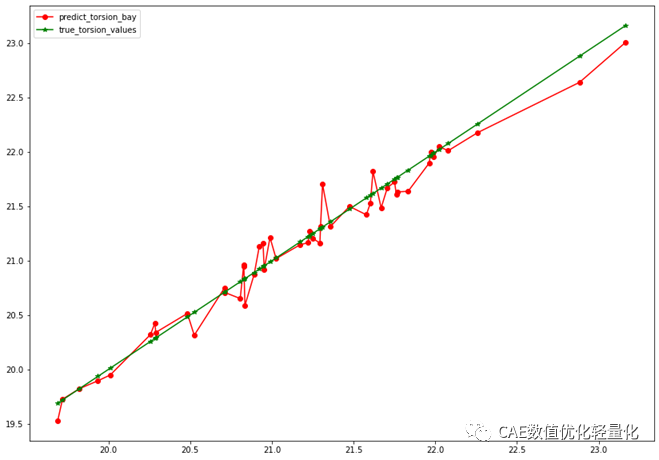
通过训练集进行支持向量机模型的训练,并通过测试集进行对模型精度的测试。通常CAE分析优化代理模型精度是使用R2值进行评价的,一般要求大于95%。




三.代理模型(元模型)
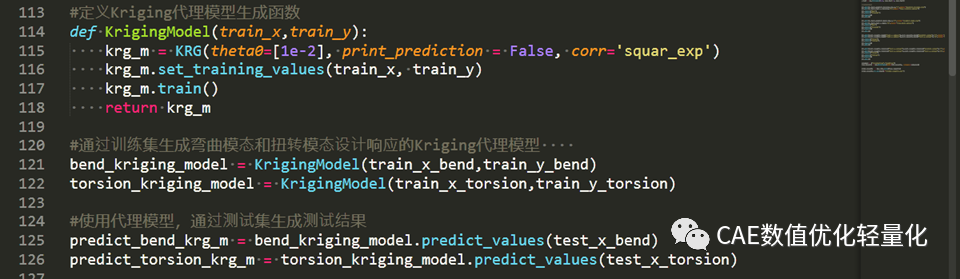
定义Kriging代理模型生成函数,并通过训练集进行代理模型生成。然后通过训练集进行模型精度测试。



可以发现,在小数据集时传统的代理模型要比机器学习模型精度高的多,而随着数据集的增大时,机器学习模型的精度会随着数据集的增大而提高。
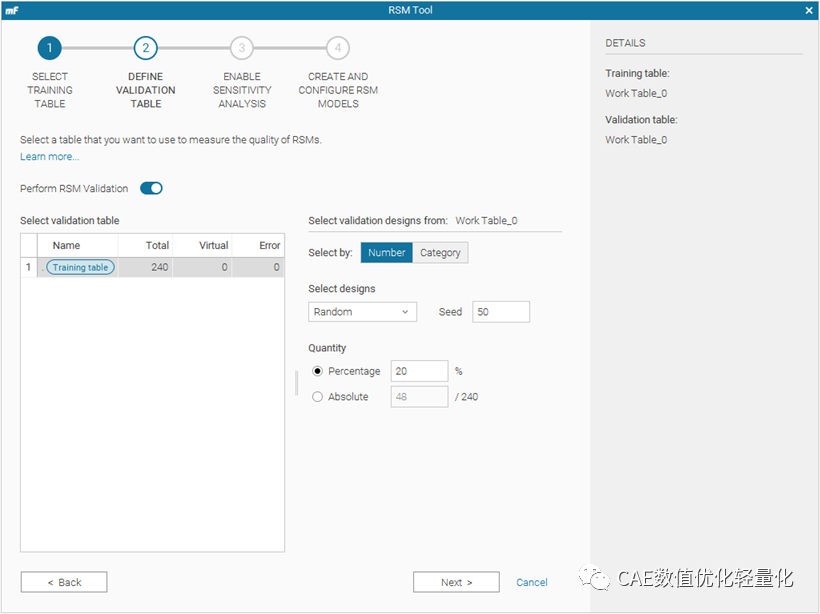
为了进行对比,使用优化软件进行相关分析。本例中使用modefrontier进行。通过将数据集按8:2分为训练集和测试集数据。
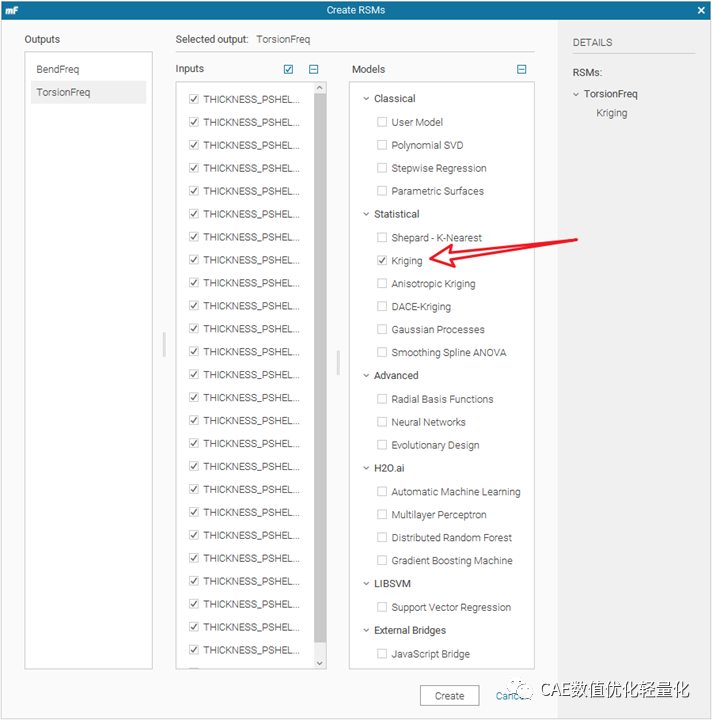
为了进行对比,选择Kriging模型。Modefrontier同样有机器学习模型,如支持向量机回归,K近邻、多层感知机等等。这方面modefrontier较其他优化软件要先进的多。包括数据处理等内容也较其他优化软件更加丰富。
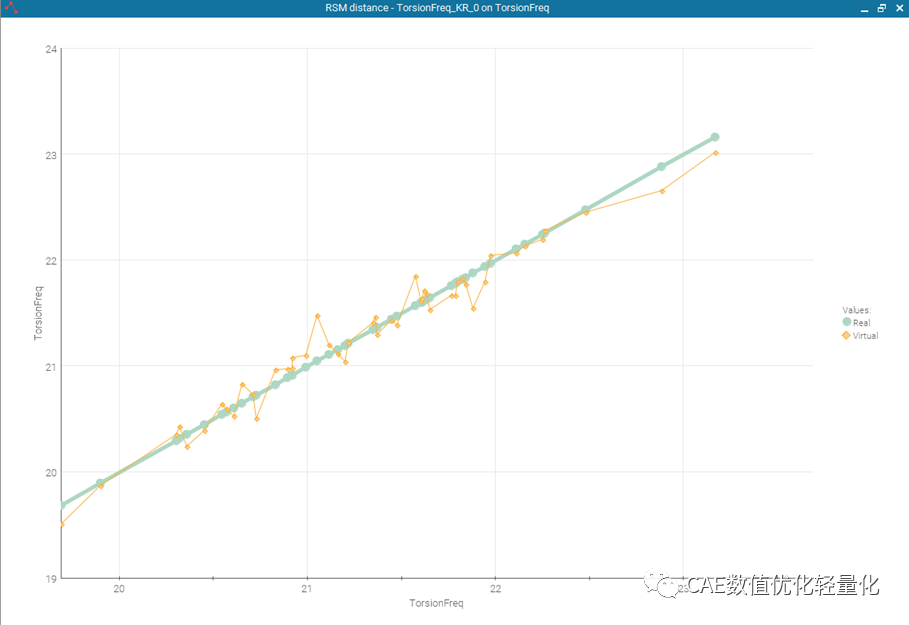
在测试集中进行分析后,代理模型计算结果和真实结果偏差曲线。
四.敏感度分析

使用增量矩阵法进行灵敏度分析




灵敏度分析主要进行设计空间缩减,这与机器学习的降维的目标是一样的。如机器学习的主成分分析,因子分析等。
通过建立的高精度的代理模型或机器学习模型可以进行后续的参数优化分析。
登录后免费查看全文
著作权归作者所有,欢迎分享,未经许可,不得转载
首次发布时间:2023-09-02
最近编辑:1年前

硕士
|
白车身结构设...
专注ANSA使用技巧-微信公众号『C...

相关推荐
最新文章
热门文章
