HFSS软件的HPC基本配置方法

1. HPC基本配置方法(本方法不适用于SIwave)
软件安装完成后,用户就可以使用软件进行建模、仿真计算了。但是,若要充分调用计算机的资源,还需对HPC并行计算进行一定的配置。
1.1. HPC的类型
HPC license分为两种,HPC与HPC Pack,它们在软件中的配置方法,略有区别。
1.2. HPC类型的配置
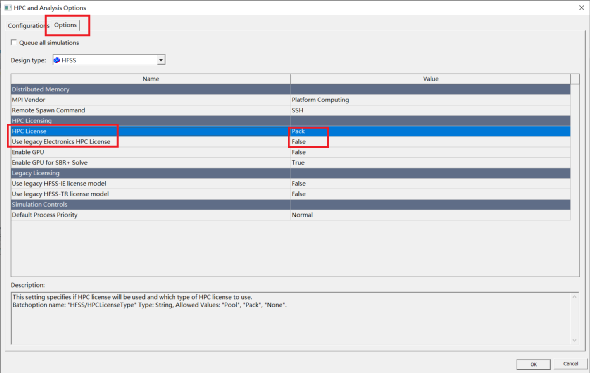
打开软件菜单栏,选择Tools\Options\HPC and Analysis Options,打开如下对话框,选中“Options”选项卡,见下图。
图中蓝色部分“HPC License”项,包含“Pool”、“Pack”与“None”三个子选项。HPC License对应于“Pool”,HPC Pack对应于“Pack”。选择与License匹配的类型即可。
1.3. 本地电脑Local的多处理器设置
1)打开软件菜单栏,选择Tools\Options\HPC and Analysis Options,打开如下对话框,默认为“Configurations”选项卡。
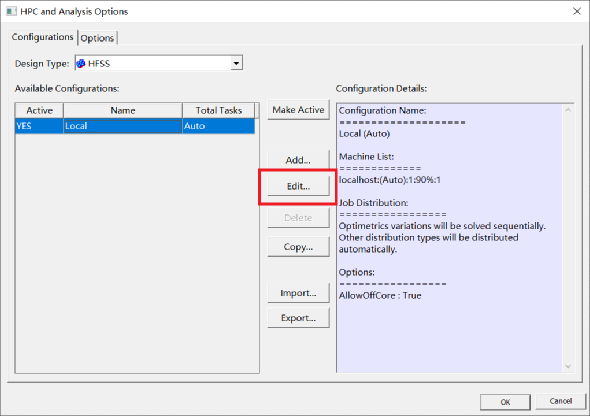
2)点击“Edit”,打开Local设置对话框,设置CPU总数与task任务数(分的域数)。
设置的CPU总数不大于license授权文件支持的CPU数量,也不能超出计算机硬件的CPU数量。关于license授权文件支持的CPU数量,请与对应的ANSYS销售人员确认。

1.4. 远程调用服务器的多处理器设置(RSM)
1)打开软件菜单栏,选择Tools\Options\HPC and Analysis Options,打开如下对话框,点击“Add”。
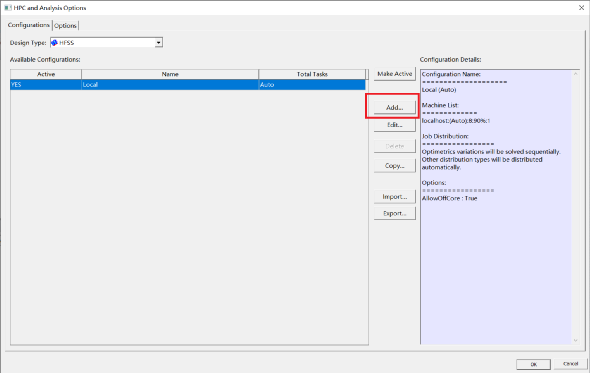
2)为本次HPC配置取个名字,通过添加服务器名称、IP地址等,将服务器加入到列表中,并设置总的CPU数;分的域数可手动添加,也可选择自动设置选项。

3)通过点击“Test”,测试远程服务器的设置是否成功。

4)点击“OK”,回到HPC设置中的“Configurations”选项卡,通过“Make Active”,可以在Local与远程调用服务器之间进行切换。

1.5. 完成HPC的基本配置
通过HPC的基本配置,可以实现本地电脑与RSM远程调用的多CPU并行运算,以及域分解提高求解效率。必须说明的是,RSM远程调用,本地电脑并不参与运算求解,而只显示操作界面。
如果需要实现多电脑分布式并行运算,以求解更大更复杂的问题,我们需要进行高级HPC设置,即MPI的配置方法(仅适用于HFSS)。
2. HPC高级配置 (仅HFSS) —— Message Passing Interface (MPI)
MPI即消息传递接接口,是目前使用最为广泛的实现并行计算的一种方式。在消息传递模型中,计算由一个或者多个进程构成,进程间的通信通过调用库函数发送和接收消息来完成。通信是一种协同的行为。
ANSYS EM Suite 16.0包含两种MPI方式,即IBM Platform MPI与Intel MPI。用户可以自由选择,取其中一种即可。
MPI配置前的准备工作
对于需要参加分布式并行运算的电脑,
1)都必须拥有一个相同的用户名以及相同的密码,该用户属性必须为管理员账户;
2)要确保每一台电脑都安装了相同版本的ANSYS EM 软件,而且软件都安装在相同的目录下(建议默认安装路径);
3)各电脑之间是相互连通的,即“ping”命令可以在任意两台电脑间成功执行,并完成数据的收发。
2.1. Intel MPI安装与配置
2.1.1. 运行ANSYS EM Suite安装包的“autorun.exe”,进入安装界面
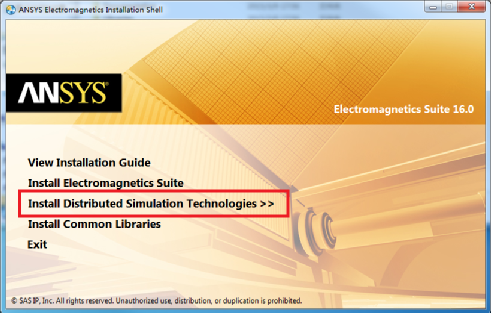
2.1.2. 选择“Install Distributed Simulation Technologies”,打开如下界面

2.1.3. 点击“Install Intel MPI”,选择解压目录,进入MPI安装界面
2.1.4. 点击“下一步”,按照默认安装设置

2.1.5. 最后点击“完成”

2.1.6. 通过ANSYS EM软件的安装目录找到“wmpiregister.exe“文件,以管理员身份运行,打开注册对话框。
具体的文件目录,可参考如下位置 “C:\Program Files\AnsysEM\AnsysEM16.0\Win64\common\fluent_mpi\multiport\mpi\win64\intel\bin”。

2.1.7. 输入域名和多机共有的用户名,若多机同域,域名可省略;另外,注册成功后,会显示成功提示信息“Password encrypted into the Registry“。

2.1.8. 在所有参加分布式计算的计算机上,重复步骤5.1.1至5.1.7,完成Intel MPI的配置。
2.2. IBM Platform MPI 安装与配置
2.2.1. 运行ANSYS EM Suite安装包的“autorun.exe”,进入安装界面
2.2.2. 选择“Install Distributed Simulation Technologies”,打开如下界面

2.2.3. 选择“Install IBM Platform MPI”,进入MPI安装界面
2.2.4. 选择安装目录,默认即可
2.2.5. 选择对应操作系统“for Windows XP/2003/Vista/2008/7”,如下图
2.2.6. 安装至下图时,切记勾选项要全部选中

2.2.7. 默认安装直至最后完成

2.2.8. 开始/运行/cmd,打开DOS命令窗口
2.2.9. 利用cd命令,将当前路径切换至如下目录
C:\Program Files\AnsysEM\AnsysEM16.0\win64\common\fluent_mpi\multiport\mpi
\win64\pcmpi\bin(软件默认安装情况下)
2.2.10. 运行命令“mpidiag –s <你的计算机名> -at -cache”,注册密码
命令是将用户本机(用于界面操作与并行设置的本地电脑,控制并行运算)的信息添加至MPI信息中。
具体操作,见下图示例。其中“beigcao”为本地用户的个人PC,注册的密码为多机共有用户名对应的密码。注册成功后会返回一条信息,并给出共有的用户名“gcao”。

2.2.11. 重复步骤5.2.1至5.2.10,在每一台参加运算的电脑上配置一次(除计算机名外,与图中配置完全一致),以实现最终的多机并行。
2.2.12. 完成IBM Platform MPI的配置。
2.3. CPU资源配置
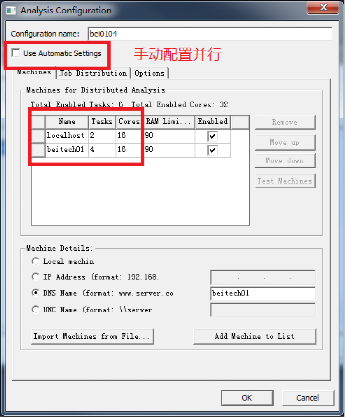
首先,获取所有参加并行计算的电脑名称与CPU数量,找开HFSS中的多处理器设置选项卡。具体操作请参照步骤4.4。
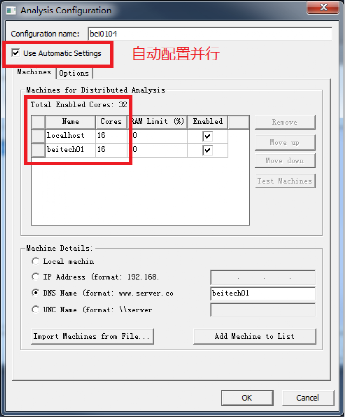
其次,添加各个电脑名称,并配置每个电脑的CPU总数与分的域数。
最后,本地电脑应作为主节点,位置应在最前方。
手动方式与自动方式的两种配置结果,可参照下图。(图中为两台电脑并行计算,Local与beitech01)
2.4. Profile中查看多机并行运算的过程
打开一个工程文件,将求解器由默认的“Direct Solver”更改为“Domain Decomposition”,即域分解法,进行仿真计算。多机并行可在Profile中查看。

2.5. MPI配置完成
当仿真中看到步骤5.4的结果时,就说明MPI配置成功。
需要注意的是,步骤5.4中而我们看到的有5个域,而其实共有6个域。这是因为作为主节点的本地电脑Beitech04,其中一个域用来进行整体仿真的控制,即作了头节点。
MPI配置成功之后,用户可根据自己仿真资源消耗的情况,自由选择由几台电脑并行计算;本地电脑也可只操作而不参加并行运算等。
THE END


