【工业大数据分析案例,之三】:绝处逢生

前面我们提到:在工作点附近,自变量的误差非常显著、对模型精度的影响非常大。误差导致的影响可以大体估算的,我找到过很多种办法。估算出来的结果令人吃惊:对很多钢种来说,模型预报的精度极限大概也只有40%左右!
有人说,精度上不去,就要提高检测精度。但现实中往往也是很难的:现代化的企业一直都在想提高检测精度,检测精度低就说明现在很难做到高精度。这样一来,模型追求高精度的目标,现实中根本就是不现实的。
似乎走投无路了,怎么办?
我先后给几千人讲过《技术创新方法》的课。期间常提到起孔子的一句话:“从心所欲,不逾矩”:要进入自由王国,就不能违反违反客观规律。说得直白一点:要想“做什么成什么样”,关键是不去做那些做不成的事情。换句话说,“知道什么是做不成的”,本身就是一种进步。模型也是这么道理。如果白白地花几年时间去提高精度,简直是人生的浪费。
退一步海阔天空。
有人遇到这样的问题,可能就缩回去了。我给学生讲创新课的时候,还有个“退半步”的理论,就是:遇到不可克服的困难时,应当适当调整技术目标。这是怎么回事呢?
有一年我面试研究生,指着桌上的一盆花问:“如果你是一个园丁,要求你不能让这盆花生出烂叶子。你该怎么办?”。 大家都知道,凡是有叶子的植物都会烂叶,绝对不烂是不可能的。这个题目考核的实质是:遇到不可逾越的困难,你应该怎么办? 我最喜欢学生这样回答:“在您来到办公室之前,我先来看看。如果有烂叶子,我就把它剪掉,让您看不到烂叶子。” 换句话说,遇到“不可逾越”的困难,就不能完全拘泥于过去的目标,而要回到更加根本的期望上去,找到解决问题的办法。
现在轮到我回答这个问题了。对于这个问题,我给出的答案是:如果预报结果的精度不可能很高,我就去追求模型本身的高精度。
所谓模型本身的高精度,就是理想状态下的高精度、也就是模型的正确性。这就好比牛顿第一定律:在不受外力的条件下,物体会保持匀速直线运动。这个定律,不可能准确描述世界上任何物体:世界上没有那个物体不受外力。但是,这个定律却是正确的。所以,建立正确的模型,就是要透过现象看本质、排除干扰去建模。
这种模型是有用的:可以用于新钢种设计、优化乃至动态控制等业务。问题的关键是:这样的目标可能吗?下面就给大家看一张图:

图1: 厚度的与强度的关系
上面这张图展示的是某个钢种的抗拉强度和厚度倒数的关系,是用实际的数据直接做出来。现实中怎么会有这么好的曲线呢?因为我做了一个“去噪声”的工作。我的办法是:在每个厚度级别下面,把所有的样本集中在一起,求取厚度和性能的平均值。所以,在上图中,横坐标是厚度倒数的平均值,纵坐标是强度的平均值。就是我第一篇提到的、读硕士时想到的办法。我们知道:在每个厚度点附近,成分和工艺参数都是围绕着工作点做随机波动。这样,求取均值就相当于把随机波动过滤掉了。
这样,厚度和强度之间,就体现出了极强的规律性。
我们把这样的规律性结果称为“子模型”。如果我们能把各种各样的“子模型”都搞清楚,并把“子模型”之间的关系搞清楚,是不是就可以把模型建好呢?下面这张图,体现的是某钢种强度和厚度之间的关系。
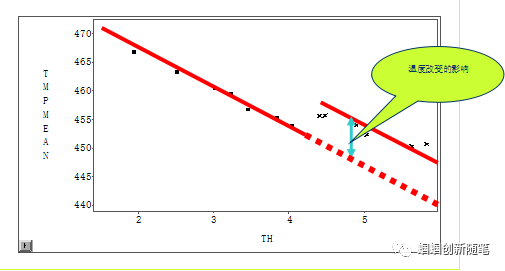
图2 工艺调整的作用
我们注意到,这张关系图中有一个跳变:这这个点上,有一个目标工艺值的跳变——期间的差异,就可以理解为该工艺参数的作用啊。
事实证明,这个思路确实是可行的,只是有漫长的道路要走:我们沿着这条思路走了接近10年的时间。既然思路正确,为什么会走了10年的十年呢?因为太困难了:要从多个侧面论证关系的成立;而论证的论据还不一定能找到。
但这件事为什么现在能做成呢?就是因为我们处于大数据的时代。
前几天,有人质问:你的文章中怎么没有“大数据”的影子,只是带了一个帽子啊。其实,工业大数据圈子里的人,对大数据的定义是有看法的。大数据的一个标准提法是“PT级别”。这个定义其实并没多大意思。
如果按照这个标准去做工业大数据,世界上没几家企业能做。蕴含大量知识和价值的工业数据,可能远不到这个级别。尽管数据量不够多,但如何分析、挖掘出来,却是非常困难的。数据分析中的困难很普遍。国外有专家提出:只要传统的数据处理方法失效,就可以称为大数据了。对这个问题反思的文章其实很多,这里不再多说。
我想强调的是:工业大数据的本质优势之一,是有条件提炼共性、可重复使用的知识。在我看来,这才是大数据时代的最重要的标志。基于这种优势,大数据才成为推动智能化的有力动力。
这种“优势”或“条件”又体现在什么地方呢?
我曾经问朋友:大数据容易建模还是小数据容易建模?很多人说:当然是大数据了! 其实,这样看如何看待“建模”了。我们知道:在N个变量的参数空间中,N+1个样本就可以拟合出一个无误差的线性模型——这难道不是非常容易吗?
小数据建模的真正问题在于:这样的模型可靠吗?如果玩真的,你敢用吗?在大数据时代,就很容易检验这个模型靠谱不靠谱啊。所以,大数据容易建模,指的是容易建立靠谱的模型。要得到靠谱的模型,需要有足够的数据来验证、训练模型。其中,最理想的情况就是符合“数据=全体样本”的条件、要有足够多的数据去辨识、抑制数据中的噪声干扰(就像图1~2 所述的那样:这样一张图的背后,其实就有数万个样本)。
“数据=全体样本”就是样本分布比较完备、不会出现抽样造成的系统性偏差。那么,什么叫“抽样造成的系统性偏差”?
网络上曾经有过一个段子: 雷军用调研小米手机用户需求的办法,调研对电视的需求。但是,按照调研结果生产的小米电视后,销路却很差。雷军百思不得其解:为什么对手机有效的方法,对电视就失效了呢? 这时,有高人指点到:用小米手机的人,有多少人家里又客厅啊?
在这个段子中:调查的对象和目标客户不是同一批人,故而调查结论出现偏差。其实,调研出现系统性偏差是很正常的、也是人们常犯的错误(到大学者那里调研技术创新,有时就会犯这个错误)。
大数据的优势之一,就是数据分析针对全集,进而避免这样的错误。所以,数据量未必特别重要,重要的是数据集 合覆盖的范围是不是相对完整。数据覆盖得完整了,人们就容易找到模仿或验证的对象、就容易建立可靠的模型;数据集不完整,有些地方的预报就容易失效——这个道理不是很简单吗?所以,纠缠于数据总量本身多大,不是很明智的——当然,从商业需求上看,软硬件供货商很希望用户有很大的数据量,一般买他们的产品或服务。事实上,即便是数据量不是很大,工业过程数据处理还有很多问题没搞清楚呢!
大数据的价值在于蕴含大知识。但大知识如何挖掘出来?前面用图1、图2,展示了如何从数据中发现最基本的知识。但我要做的,是把这些知识综合起来。如果把这些基本的知识比作“砖块”,综合的过程就是“盖大楼”的过程。这也相当不容易。所以我想:数据研究工作,可能有一个发展阶段:从数据技术、到数据科学再到数据工程。
当然,这是个遥远的设想。现在的重点,或许主要是发展“数据科学”的问题。
在十年前我就意识到:大数据里面可以挖掘出人们过去无法确认的科学规律、会成为进行科学研究的主流方法之一。这种考虑就是基于大数据更容易排除干扰:尤其是对于多变量问题,会有显著的优势。
大家注意到:绝大多数的物理学定律,是研究很少的变量之间的关系;即便涉及到多个变量,往往也可以拆分成若干个相对简单、独立的函数关系。换句话说:科学家很少会说清楚很多变量复杂地纠缠在一起的问题——这方面的问题是本质性的复杂,而不是不存在,是过去难以研究的。钢铁的成分、组织和性能之间的关系,恰恰就是这样的问题。换句话说,大数据为解决这类问题带来了机遇。
如果把数据分析当成科学问题,就会发现:科学研究的很多观念、思想是同样适合于数据分析。所以我觉得:从事数据分析的人,最好找机会读一下科学哲学领域的著作。
例如:科学的工作,是在存在干扰的环境下寻找背后的规律的。寻找规律的难点在什么地方?就是剔除干扰!
再如,科学研究重视因果。工业过程数据分析也要重视因果。重视因果的有两个方面的原因:首先是因为工业过程数据分析中经常会遇到相关而非因果关系;其次是工业过程追求可靠性,往往需要找出因果关系来指导我们正确的行动。这一点是工业大数据不同于其他领域的重要特点。
“因果性”的概念很少有人提到。我在大学读控制理论时,读到过“因果性”的定义。不久前大数据理论成为热点以后,“因果性”又被提出来——但大数据理论提出这个概念的目的与我相反:不是为了重视,而是为了蔑视。
10多年前,我读到一篇关于因果统计的文章,和我的想法非常吻合、让我拍案叫绝、如沐春风。这篇文章是北大数学系教授、中国现场统计学会理事长耿直老师写的。此后多年,我成了一个不断地给耿老师添麻烦的人。让我至今心有愧意。
关于因果性话题很长,看来需要专门写一篇来讨论。今天太晚了,只好打住。欢迎大家继续关注。


