结合主动学习: PWmat_MLFF扩展应用MLFF on the fly

那么这里的MLFF on the fly到底做了什么呢?
MLFF on the fly的基本思想是,在利用MLFF进行MD模拟的每一个步骤中,都对这个结构进行一次判断,并且求得一个参数γ(extrapolation grade),它的意义就是度量了这个结构是否能够被现有训练集良好的预测。当γ大于设定的阈值时,则会进行DFT计算并将DFT得到的力和能量加入训练集并替换掉之前被判断表现的不好的数据,并对新的训练集重新训练出新的模型用于接下来的MLFF的预测。流程图如下
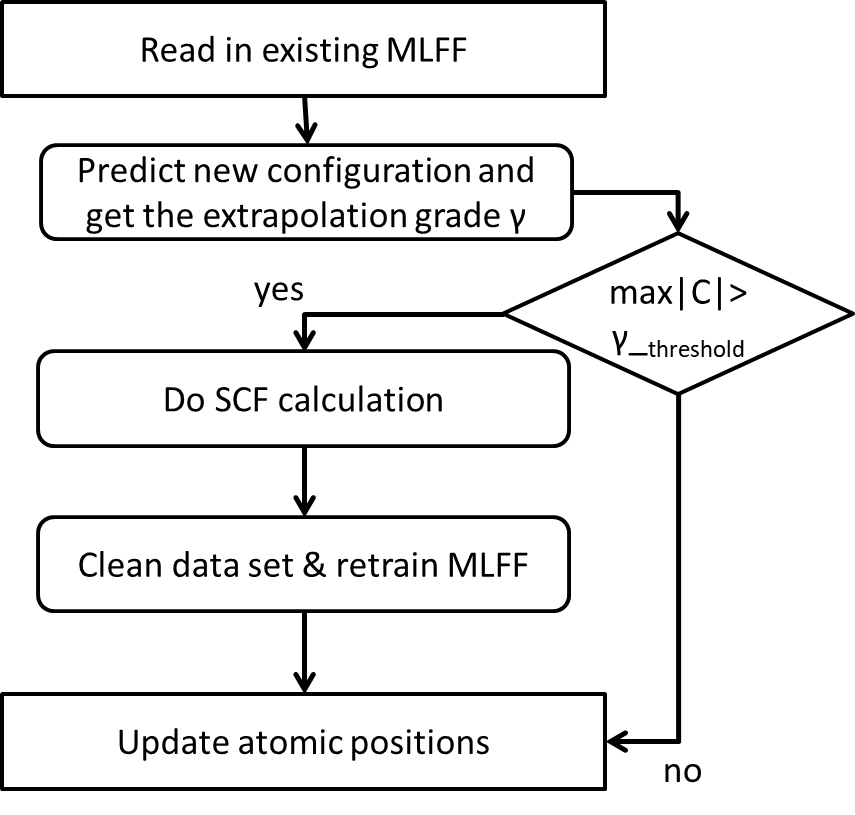
在这里我们用Moment Tensor Potentials(MTPs)来作为ML interatomic interaction的模型。在这个模型里,简单来说就是把总的能量分成来自每个原子上的贡献。在上文中提到的并且是这个方法的关键便是对extrapolation grade γ的定义[1]。在这里我们将γ定义为矩阵C的最大的那个矩阵元,矩阵C是由模型的特征矩阵和其最大行列式的子矩阵的逆相乘得到。其中得到最大行列式的子矩阵的方法叫做maxvol algorithm[2],感兴趣的同学可以自行查阅一下相关算法。整体思路是从这个很长的特征矩阵中寻找一个最线性无关的子矩阵。那么得到的这个子矩阵就更能代表整个训练集。
上述方法可以参考文献
介绍了它的功能,那么这个MLFF on the fly效果如何?
On the fly在运行的过程中每一步的MD模拟前都会对当前的结构进行判断是否能够在当前的训练集的预测范围内,由此可以保证MLFF on the fly得到的结果与DFT得到的结果精度一直保持接近由训练集得到的精度,这句话可能有点怪,它的意思是on the fly这个方法本身并不会改变MLFF对结果预测的准确程度,而是对MLFF的应用场景做一个筛选,判断这个结构能不能被现有的模型良好的预测,也就是“interpolation”而非“extrapolation”。所以这个方法可以用于长时间的分子动力学模拟,可以保证结果的可靠性。
以LiGePS为例(体系原子数50个,一个gamma点,赝势为SG15,Ecut/Ecut2=60/240,Nose-Hoover热浴恒温600K,间隔2fs;MLFF选用线性模型,特征为2b&3b,训练集使用5000步(10ps)的MOVEMENT),extrapolation grade γ阈值设置为10(γ阈值需要大于等于1,越接近1和AIMD的结果误差越小,但同时重新训练的次数会更多)。对比AIMD和MLFF on the fly的结果(每隔30步mlff的预测计算一次DFT,对比两者每个原子上的力和能量的均方根误差),并附上下图两者的均方位移(MSD)与时间的关系。
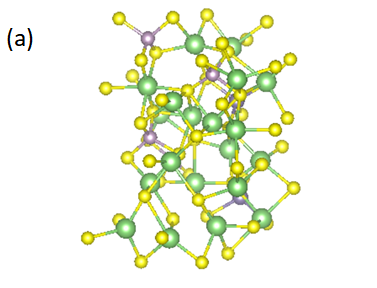

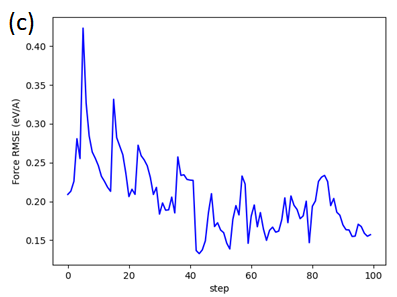

(a)LiGePS结构; (b)每个原子上能量的rmse ; (c)每个原子上受力的rmse; (d)LiGePS中Li的MSD
从这个结果可以看出,在MLFF on the fly在进行了长时间的模拟前后,MLFF得到的力与能量的RMSE都一直保持在0.25eV/angstrom和0.7eV的附近震荡,维持了MLFF初始训练集展现出的性能。
再来对比MLFF on the fly 与AIMD的速度
在设置了不同的extrapolation grade γ(th_1)阈值之后会影响程序的效率,越接近于1的阈值可能会明显的增多程序运行过程中重新训练的次数。(数据来自于mcloud2,使用1个节点4块3080Ti,LiGePS体系原子数50个,一个gamma点,赝势为SG15,Ecut/Ecut2=60/240,Nose-Hoover热浴恒温600K,间隔2fs,运行30000步)
γ(th_1) | 运行过程中重新训练的次数 | 消耗时间 |
1.02 | 980 | 24.91h |
1.1 | 226 | 10.87h |
10 | 10 | 6.85h |
AIMD | / | 48h |
在实际的运行过程中,重新训练特征和补充新结构的DFT结果都会消耗更多的时间,所以在使用时需要注意结合需求调节阈值。但随着运行的步数的变多,重新训练的需求也会随之减弱,并相对收敛,如下图所示
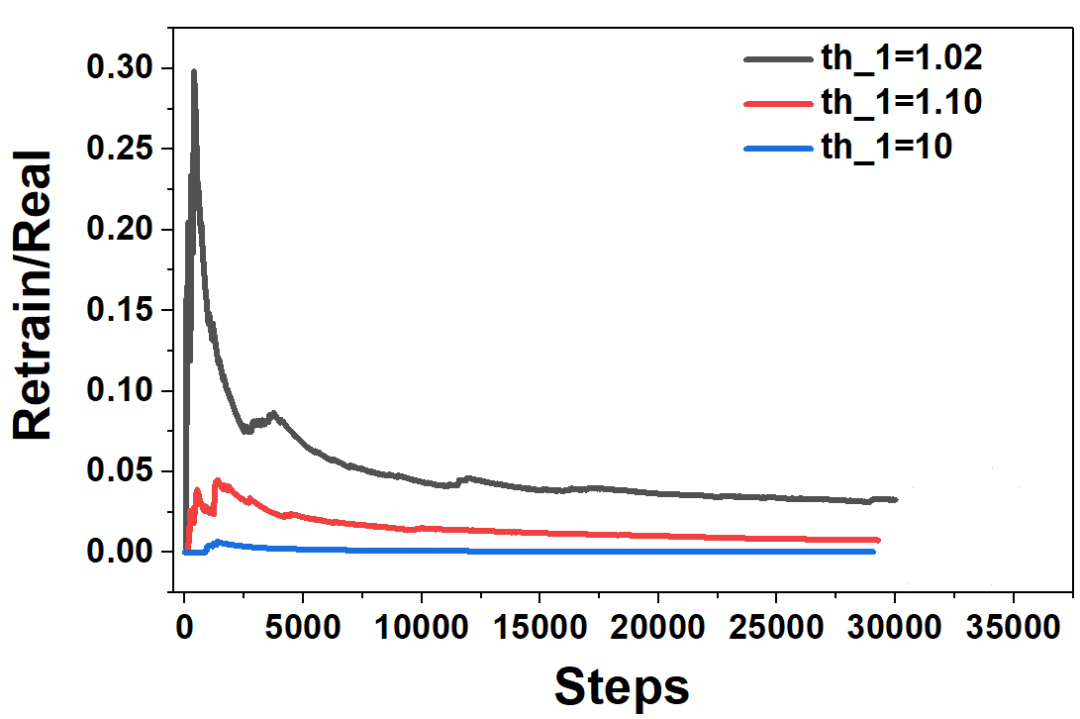
在MLFF运行过程中,重新训练的步数与实际运行步数的比值
第二点就是可以通过运行MLFF on the fly来得到一个更为可靠的力场。因为在运行过程中,主动学习算法 会不断地扩大能够预测的结构的边界,所以一个运行足够长的结果不仅有MD的结果还有可靠的力场可以用于相同体系的MLFF的MD模拟。值得注意的是,最后得到的训练集是一个非常小的训练集,在重新生成特征和训练时将会非常的迅速。但请不要往里面添加额外的训练集,这可能会很大程度的影响结果的准确性。
综上做个总结,那么该如何选择MLFF on the fly和MLFF的呢?首先MLFF on the fly本身就是对MLFF的方法的一个扩展使用方法,两者并无本质区别。那么在实际使用时值得关注的点就是运行的效率以及结果和DFT的贴合程度,所以当已有的AIMD的训练集覆盖面足够广时可以直接使用MLFF获得MD结果;当对训练集并不自信,需要主动学习方法进一步扩展训练集预测边界或者需要进行长时间模拟的话可以使用MLFF on the fly保证模型的结果不会太偏离DFT的结果。
—E N D—
公司简介
北京龙讯旷腾科技有限公司是成立于2015年的国家高新技术企业,是国内材料计算模拟工具软件研发创新的领导者,致力于开发满足“工业4.0”所需的原子精度材料研发Q-CAD(quantum-computer aided design)软件。公司自主开发的量子材料计算软件PWmat(平面波赝势方法并基于GPU加速)可以进行电子结构计算和从头算分子动力学模拟,适用于晶体、缺陷体系、半导体体系、金属体系、纳米体系、量子点、团簇和分子体系等。


