三个臭皮匠,顶个诸葛亮 | 新论文:用深度集成学习来智能构建滞回模型


论文链接:https://doi.org/10.1016/j.compstruc.2023.107106
太长不看版
本研究提出了一种集成学习方法,将深度神经网络特征提取能力与基于物理机制的显式滞回模型相结合,智能构建滞回模型。该方法的优点在于,其可以自动学习结构的非线性特征(例如捏拢、刚度退化等),从而避免了手动选择特征的主观性和不确定性。另外,该方法可通过集成多个模型提升预测精度和稳定性。案例研究表明,本方法效率高于人工构造的滞回模型,泛化性能优于纯数据驱动的滞回模型。
01
研究背景
结构响应的计算分析依赖于准确合理的滞回模型。现有的滞回模型构造方法可以分为两类:显式方法和隐式方法:
显式方法
显式方法就是人为构造一个滞回规则,然后根据试验数据拟合滞回规则的参数。比如先提出双线性滞回规则,然后根据试验数据拟合双线性规则的屈服强度、硬化刚度等参数。搞抗震的研究生,大部分都经历过这样一个艰苦的过程:做完滞回试验后,从文献中浩如烟海的众多滞回模型中挑选出几个可能最适合自己试验的滞回模型,然后根据自己的试验数据标定滞回模型的参数,希望可以很好的模拟自己的试验结果。但是一方面标定参数很麻烦,另一方面文献中的滞回模型可能也不能和自己的试验吻合良好,往往还要自己动手加以改造搞出一个新模型出来。折磨得很多研究生头发又少了不少。

图1 显式方法
隐式方法
隐式方法则是让计算机通过学习试验数据,然后直接给出滞回规律,即所谓的“端到端”(End-to-End)的方法。随着AI对时序数据学习能力的增强,隐式方法得到了很多关注。本课题组也开展了一些相关研究,具体参见
新论文 | 基于深度学习的滞回模型如何拥有“误差自纠偏”能力?(附数据集和程序) 新论文:结构响应行为预测的深度学习模型有N种,该怎么选? 提升小样本下预测性能近一个数量级 新论文 | 神经网络响应时程预测中的迭代自迁移方法 (附数据集和程序)
理论上,隐式方法可以很好解决显式模型的问题,可以不用人为选定滞回模型并标定参数,而是完全交给计算机完成。但是“理想很丰满,现实往往很骨感”,AI往往需要学习大量的数据才能建立起比较好的端到端预测能力,而土木工程试验的试件数量往往很有限,难以满足AI学习的要求。而且。换一批试件,可能AI就不能很好预测,泛化能力也让人捉急。

图2 隐式方法
那有没有可能把显式方法和隐式方法结合起来呢?我们想到,是否可以先把文献里面已有的滞回模型都输入计算机,建立起一个模型库(本文称为“基模型”)。然后根据试验数据,让AI自己学习如何挑选滞回模型并标定模型参数。更进一步,AI可以挑选多个滞回模型作为“基模型”,然后把他们加权组合,构造出新的滞回模型,即“三个臭皮匠,顶个诸葛亮”。这样AI就不仅有简单的特征提取和标定能力,还有了一点“创新”能力,从而能够更好满足多种多样的需求。

02
研究方法
本文提出了一种深度集成学习驱动的滞回模型构建方法(如图3),其流程框架为:首先选取一定数量的既有滞回模型,构成基模型库,并对每个基模型生成滞回数据;接着基于每个基模型及数据,设计并训练模型参数预测网络,完成基模型神经网络构建;最后设计一个集成学习网络模型,融合各基模型输出结果,从而达到“三个臭皮匠,顶个诸葛亮”的效果。

图3 深度集成学习驱动的滞回模型构建方法
03
基于敏感性分析的基模型神经网络构建
在构建复杂的基模型神经网络过程中,容易遇到一类问题,不同的模型参数在某些特定的加载机制下不会对最终响应产生影响。举个简单的例子,混凝土一直处于弹性阶段,耗能参数(C)、软化参数(ηsoft)对混凝土响应就不会产生影响。但这些数据会让神经网络十分困惑,难以找到优化的方向。

图4 同一滞回曲线可能对应不同参数
因此,本研究提出了一种基于敏感性分析的基模型神经网络构建方法,利用中心差分法计算每个模型参数在特定加载机制下的导数值(公式如下),由于导数值代表这一参数在对应领域内变化对整体滞回曲线的影响,因此可以认为是该参数在该条件下的重要性。
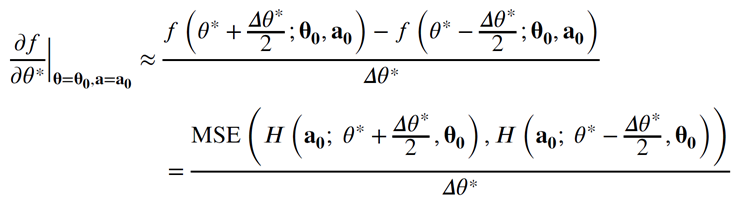
此后我们就可以利用得到的重要性指导神经网络进行反向传播,从而提升神经网络的预测性能。举例而言,在某一条滞回数据中,强化参数(η)对混凝土影响大,对应神经元赋予更大的权重,而耗能参数(C)影响小,则对应神经元赋予更小的权重。

图5 基于敏感性分析的基模型神经网络构建
04
集成学习方法
单一物理滞回模型有时难以满足实际需求,因此,本研究提出基模型加权组合的复杂滞回关系模拟方法。其中,基模型特征融合时采用自适应权重,由多物理模型集成学习以实现权重的自适应预测。具体地,本研究采用具备滞回特征提取和学习的LSTM神经网络作为基模型的特征融合器,本研究中基模型采用线性叠加融合,线性叠加的自适应权重则采用特征融合器进行预测。具体架构如图6所示。该特征融合器接收应变数据与t个(本研究为3个)单一物理滞回模型计算得到的应力数据,取最后一个隐层状态为序列的特征,通过全连接映射为各物理滞回基模型的权重。

图6 集成学习模型架构图
05
结果分析
最后,基于上述方法开展试验数据集预测的验证测试,图7给出了5个典型试验的预测结果(更多的试验结果参见论文)。可以发现,Steel02基模型(第一列)能很好地预测滞回环饱满的滞回关系,但对存在退化、捏拢现象的滞回关系预测结果较差。10参数基模型(第三列)的泛化性能较强,对滞回环饱满或存在退化、捏拢现象的滞回关系都能较好地预测。利用集成学习方法进行特征融合的模型(第四列)效果最佳。

图7 不同模型试验数据预测结果
06
结论
本研究结合人工智能强大的特征提取能力与物理机制驱动的力学模型,提出了一种基于神经网络的单一物理滞回模型参数预测方法,以及对应的数据集构建方法、模型训练方法。滞回模型关键参数的导数相对大小体现该参数对滞回曲线形状的贡献大小。最后,本研究提出了一种多物理滞回模型组合预测方法,利用特征融合器组合多物理滞回模型,在试验数据集上取得了良好的效果。
---End---