论文学习|综述-机器学习在机器故障诊断中的应用:-过去:使用传统机器学习理论的智能故障诊断

非常尊重并感谢科研人员做出的辛勤贡献!
翻译纯做学术分享,因水平有限,若有翻译不当之处,恳请批评指正!
若有侵权,烦请联系处理!
本篇综述详细阐述了机器学习在机器故障诊断方向的发展过程及研究成果,分为过去、现在、未来三个部分,很有广度,值得初学者阅读学习和思考。其未来趋势部分迁移学习对写论文方向很有指导性意义。其写作陈述话术也很值得借鉴。
本篇将介绍第2节:过去:使用传统机器学习理论的智能故障诊断
论文信息
论文题目:Applications of machine learning to machine fault diagnosis: A review and roadmap
期刊、年份:Mechanical Systems and Signal Processing,2019
作者:Yaguo Lei(a*), Bin Yang(a), Xinwei Jiang(a), Feng Jia(a), Naipeng Li(a), Asoke K. Nandi(b)
机构:(a): Key Laboratory of Education Ministry for Modern Design and Rotor-Bearing System, Xi’an Jiaotong University, Xi’an 710049, China
(b): Department of Electronic and Computer Engineering, Brunel University London, Uxbridge UB8 3PH, United Kingdom
目录
1. 引言
2. 过去:用传统机器学习理论进行智能故障诊断
2.1 概述
2.2 第1步:数据收集
2.3 第2步:人工特征提取
2.3.1 特征提取
2.3.2 特征选择
2.4 第3步:健康状态识别
2.4.1 基于专家系统的方法
2.4.2 基于ANN的方法
2.4.3 基于SVM的方法
2.4.4 其他方法
2.5 结语
3. 现在:用深度学习理论进行智能故障诊断
3.1 概述
3.2 第1步:大数据收集
3.3 第2步:基于深度学习的故障诊断
3.3.1 基于堆叠自编码器(Stacked AE)的方法
3.3.2 基于深度置信网络(DBN)的方法
3.3.3 基于卷积神经网络(CNN)的方法
3.3.4 基于ResNet的方法
3.4 结语
4. 未来:用迁移学习进行智能故障诊断
4.1 在工程应用场景用迁移学习进行智能故障诊断的动机
4.2 智能故障诊断中迁移学习的定义
4.2.1 智能故障诊断中迁移难点
4.2.2 智能故障诊断中的迁移场景
4.3 智能故障诊断中基于迁移学习的方法种类
4.3.1 基于特征的方法
4.3.2 基于生成对抗神经网络(GAN)的方法
4.3.3 基于实例方法
4.3.4 基于参数的方法
4.4 结语
5. 讨论:智能故障诊断的未来挑战和路线图
5.1 如何未基于机器学习的故障诊断模型训练提供大量高质量的数据
5.2 如何在大数据革命中针对特殊问题构建基于深度学习的故障诊断模型
5.3 如何保护迁移学习在实际工程应用中不受负迁移的影响
5.4 如何提高基于深度学习的故障诊断模型可解释性
6. 总结
摘要
智能故障诊断(IFD)是指机器学习理论在机器故障诊断中的应用。这是一种解放人类劳动很有前途的方式,并能自动识别机器的健康状态,因此在过去的二三十年中备受关注。虽然IFD已经取得了相当多的成功,但在系统地涵盖IFD从摇篮到开花结果的发展方面,仍然存在空白,很少为未来的发展提供可能的指导方针。为了弥补这一差距,本文根据机器学习理论的进展,对IFD的发展进行了综述和路线图,并给出了未来的展望。过去,传统的机器学习理论开始弱化人类劳动,将人工智能时代带入机器故障诊断。近年来,深度学习理论的出现对IFD进行了改革,自2010年代以来,IFD进一步解放了人工劳动,鼓励构建端到端诊断流程。它意味着直接连接日益增长的监测数据和机器的健康状态之间的关系。在未来,迁移学习理论试图将诊断知识从一个或多个诊断任务转移到其他相关任务中,这有望克服IFD在工程场景中应用的障碍。最后,结合该领域的挑战,绘制IFD的路线图,以显示潜在的研究趋势。
关键词: 机器,智能故障诊断,机器学习,深度学习,迁移学习,综述和路线图
Ⅱ 过去:使用传统机器学习理论的智能故障诊断
本节介绍了传统机器学习理论的动机和应用,并根据常用的诊断步骤(包括数据收集、人工特征提取和健康状态识别)进一步回顾了过去的IFD(Intelligent fault diagnosis)
2.1 综述
传统的故障诊断过程大多是通过人工检测机器的健康状态来进行的,这增加劳动强度,降低了诊断的准确性。先进的信号处理方法[38-40]能够帮助确定故障的类型或故障发生在机器的何处。然而,这些方法很大程度上依赖于专业知识,而维护人员在工程场景中大多缺乏这些知识。此外,信号处理方法的诊断结果过于专门化,无法被机器操作者理解。因此,现代工业应用更青睐能够自动识别机器健康状态的故障诊断方法。
在机器学习理论的帮助下,IFD有望达到上述目的[1,5]。在过去的IFD阶段,一些传统的机器学习理论,如神经网络和支持向量机,被用于机器故障诊断。故障诊断过程包括数据采集、人工特征提取、健康状态识别三个步骤[1],如图1所示。下面的小节将详细介绍每一步。
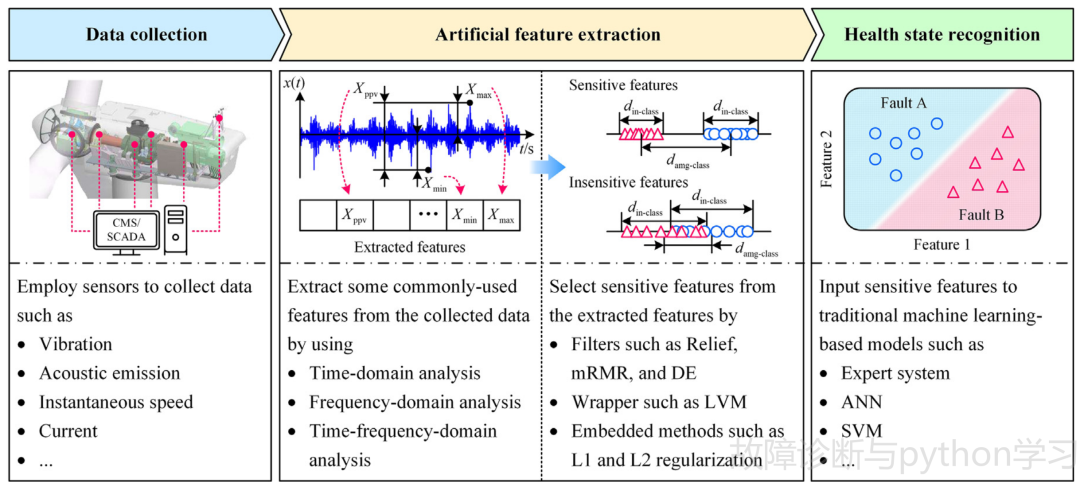
图 1 用传统机器学习进行智能故障诊断步骤
2.2 第一步:数据收集
在数据采集步骤中,传感器安装在机器上,不断地收集数据。通常采用不同的传感器,如振动、声发射、温度和电流互感器。其中,振动数据被广泛应用于轴承[4,41]和齿轮箱[42,43]的故障诊断。声发射数据可用于检测轴承[44,45]和齿轮[46,48]的早期故障和变形,特别是在低速运行条件和低频噪声环境下。瞬时转速数据是发动机故障诊断中常用的数据[49 51],具有很强的抗干扰能力。电流数据在电驱动机械故障诊断中起着重要的作用[52 54]。这类数据只需使用电流互感器就可以很容易地收集到。此外,研究人员发现,来自多源传感器的数据具有互补的信息,可以融合这些信息,比仅使用单个传感器[55]的数据可以实现更高的诊断准确率。
2.3 第二步:人工特征提取
人工特征提取包括两步。首先,从采集的数据中提取一些常用的特征,如时域特征、频域特征和时频域特征。这些特性包含反映计算机运行状况状态的运行状况信息。其次,特征选择方法,如过滤器(filters)、包装器(wrappers)和嵌入式方法(embedded methods),用于从提取的特征中选择对机器健康状态敏感的特征。这有利于消除冗余信息,进一步提高诊断结果。下面详细介绍这两个步骤。
2.3.1 特征提取
常用的特征可以从时域、频域分析或时频域提取。
1)时域特征可分为有量纲的和无量纲特征。前者包括平均值(mean)、标准差(standard deviation)、均方根值(root mean square)、峰值(peak value)等,它们受机器转速和负荷的影响。后者主要包括偏度(skewness)、峰度(kurtosis)、波峰指标(crest indicator)、形状指标(shape indicator)、裕度指标(clearance indicator)、脉冲指标(impulse indicator)等,这些对机器的运行条件具有鲁棒性[56,57]。
2)从频谱中提取频域特征,如平均频率(mean frequency)、频率中心(frequency center)、均方根频率(root mean square frequency)等,这些在参考文献中有所介绍[56、57]。它们包含了在时域特征中无法找到的信息。
3)通常采用小波变换(WT)、小波包变换(WPT)或经验模型分解(EMD)等方法提取能量熵[56,57]等时频域特征。这些特性能够反映机器在非平稳运行条件下的健康状态。
2.3.2 特征选取
从时域、频域和时频域提取的特征包含了冗余信息。它们可能会加重计算成本,甚至导致维数过大(原文:curse of dimensionality)。为了弱化这个问题,一些研究[58-65]从收集到的特征中选择对机器健康状态敏感的特征。它们可以分为三类方法,即过滤器、包装器和嵌入式方法。
2.3.2.1 基于过滤器的方法(Filter-based method)
过滤器直接对采集到的特征进行预处理,与分类器[58]的训练无关。下面简要介绍一些过滤器。
1) Relief[66]和Relief-F[67]构建了一个相关指标来确定特征对机器健康状态的敏感性。
2)信息增益和增益比[68]也是信息论中常用的两种特征选择方法。选取信息增益和增益比较大的特征对诊断模型进行训练,提高诊断结果。
3)最小冗余最大相关性(Minimum Redundancy Maximum Relevance, mRMR)[69]试图选择具有最大不相似性的特征。
4) Fisher评分[70]是一种特征选择的距离度量方法,其目标是选择一个能使类间距离最大化而类内距离最小化的特征。
5)距离评价(Distance evaluation, DE)[71,72]通过距离度量选择特征集,其中敏感特征服从在类内距离小,而在类间距离大的特点。
2.3.2.2 基于包装器的方法(Wrapper-based)
与基于过滤器的方法不同,包装器关注特征选择与训练分类器[58]的交互。换句话说,分类器的性能被用来评估所选择的特征集。如果所选的特征子集不能产生最优的分类精度,则在下一次迭代中重新选择另一个子集,直到所选的特征使分类器的性能达到最优。拉斯维加斯包装器(Las Vegas wrapper, LVW)[73]被广泛用于特征的选择,其中Las Vegas算法用于搜索特征子集,以分类器的误差作为特征评估的度量
2.3.2.3 嵌入式方法
嵌入式方法将特征选择融入到分类器的训练中。一般在分类器的优化对象上施加正则化条件,并在分类器训练完成后自动选择特征[58]。通常考虑两个正则化。一个是L1正则化[74],另一个是L2正则化[75]。这两种方法都可以缓解在少量样本的训练中出现的过拟合问题。而L1项更倾向于获得稀疏参数,这样可以抛弃分类中的冗余特征,进一步增强分类器的分类性能。
2.4 第三步:健康状态识别
健康状态识别使用基于机器学习的诊断模型来建立选定特征与机器健康状态之间的关系。为了达到这一目的,首先使用标记样本对诊断模型进行训练。在此之后,当输入样本未标记时,模型能够识别机器的健康状态。根据研究的流行程度,我们将在接下来的小节中简单介绍四种使用传统机器学习的IFD方法。
2.4.1 基于专家系统的方法
2.4.1.1 专家系统简介
专家系统被认为是一种可以提供专家级诊断知识来解决机器诊断任务的方法,而不是大量的人工劳动。基于专家系统的诊断模型如图2所示,由数据库(database)、知识库(knowledge base)、推理引擎(inference engine)、用户界面(user interface)和解释系统(explanation system)五个部分组成[76]。各部分简述如下:
①动态数据库:收集在解决诊断任务的每个部分产生的数据,作为推理引擎操作的记忆。
②知识库:包含了与诊断任务相关的专家知识。此外,它还进一步包含故障特征,为推理引擎提供健康信息
③推理引擎:利用知识库中输入的健康信息和推理知识(设计的规则和策略)与动态数据集和解释系统交互,进而推断诊断结果。
④用户界面:是一个功能集成的界面,用户可以在其中与系统进行数据传输、参数配置、结果采集、问题定义和咨询等交互。
⑤解释系统:响应用户推理对推理过程的咨询,并进一步解释专家系统做出给定诊断决策的原因。

图 2 专家系统诊断框架
2.4.1.2 专家系统在机械故障诊断的应用
根据推理引擎不同,基于专家系统的诊断模型可分为基于规则推理(rule-based reasoning)、基于模糊逻辑推理(fuzzy logic-based reasoning)、基于神经网络推理(neural network-based reasoning)和基于案例推理(case-based reasoning)四类。每一部分的综述如下。
1)采用基于规则推理方法对诊断知识进行操作,并根据设计的规则进行决策[15,77]。在IFD领域,Krishnamurthi等[78]为一个辛辛那提Milacron 786机器人设计了一个基于规则推理的专家系统,这是该领域最早的研究之一。所设计的诊断框架在知识获取、应用系统生成、学习和解释等方面大大减少了诊断模型的开发时间和工作量。Gelgele等[79]采用IF-THEN规则构建了基于专家系统的汽车发动机诊断模型。将基于规则推理方法应用于液压系统[80]、滚动轴承[81]、离心泵[82]的故障诊断。尽管基于规则的推理可以建立从选定特征到健康状态的非线性映射,但对于复杂机器,随着规则设计数量的增加,推理效率会下降。
2)基于模糊逻辑推理将模糊集理论引入推理引擎来描述不精确的非数值信息[15,77]。在IFD中,Lee等[83]设计了电力系统的模糊推理系统,这是模糊逻辑推理应用的最早工作之一。该系统由元推理系统(Meta inference system)、混合诊断专家系统(expert system for hybrid diagnosis)、变电站诊断专家系统(expert system for the diagnosis of substations)和输电网诊断专家系统(expert system for the diagnosis of transmission network)四个部分组成,提高了故障诊断过程的效率和可靠性。Liu等[84]采用模糊多属性群决策方法(fuzzy multi-attribute group decision making group)构建基于专家系统的诊断模型。Wu等人[85]使用模糊逻辑推理来识别踏板车发动机的健康状态。Berredjem等[86]将模糊专家系统应用于轴承故障诊断,取得了较高的诊断精度。基于模糊逻辑的推理性能与模糊数据集有关,但模糊数据集难以捕获。因此,这种推理通常学习能力较低,可能会降低诊断准确率。
3)基于神经网络推理继承了神经网络的学习、联想和记忆能力[15,77]。Wu等[87,88]分别利用概率神经网络(probability neural network)和广义回归神经网络(generalized regression neural network)构建了基于专家系统的内燃机诊断模型。Hajnayeb等[89]采用多层感知器神经网络(multi-layer perceptron neural network)构建推理引擎,推断收集到的数据与轴承健康状态之间的关系。Jayaswal等[90]将神经网络和模糊规则相结合,构建基于专家系统的轴承诊断模型。基于神经网络的推理需要从足够的训练数据中获取诊断知识,这在工程场景中是很难满足的。另外,由于神经网络的黑盒子,这种推理不能清楚地解释推理过程和所保存知识的物理意义。
4)基于案例的推理尝试根据类似存在问题的解决方案来解决专门问题[15]。Vingerhoeds等人[91]使用基于案例的推理,将列车制造商和铁路公司的知识和经验结合起来进行在线故障诊断。Varma等[92]提出了一种利用车载故障信息进行机车基于案例推理的故障诊断系统。Wu等[93]开发了现代商用飞机故障诊断专家系统,该系统采用基于案例推理和模糊逻辑设计。Vong等[94]为汽车发动机点火系统构建了基于案例推理和核k-means的计算机辅助诊断系统
(专家系统的总结及缺点)
基于专家系统的诊断模型将专家的诊断知识表示为推理算法,自动识别机器的健康状态。然而,诊断模型的性能很大程度上依赖于专家知识,专家知识难以获取和表达。不正确和不完整的知识可能会降低诊断的准确性。此外,专家系统缺乏自学习能力,导致诊断知识库难以扩展和修正。
2.4.2 基于人工神经网络(ANN)的方法
人工神经网络模拟了人脑在信息处理中的活动,是建立诊断模型的有效途径。本节回顾了神经网络在机器故障诊断中的应用
2.4.2.1 ANN简介
反向传播神经网络(BPNN)是一种有监督学习的多层感知器,由前向传播(forward propagation)和反向传播(back propagation)两部分组成。在前向传播中,如图3所示。
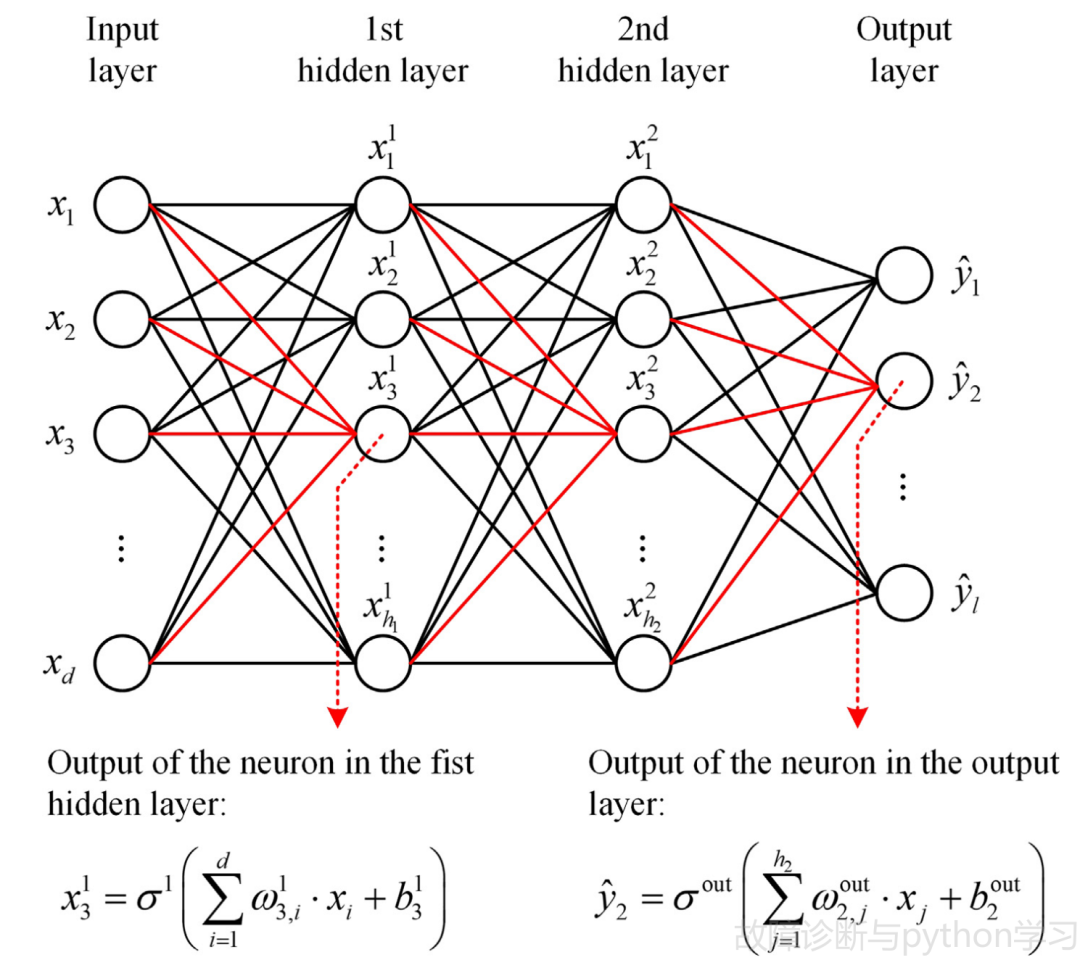
图 3 两个隐藏层的BPCNN结构
输入样本经过多个隐藏层处理,最终通过输出层映射到目标类中。假设训练数据集
(1)
其中
(2)
其中
(3)
为了解决这个问题,我们用梯度下降法更新训练参数
(4)
其中
2.4.2.2 ANN在故障诊断的应用
表 5 神经网络在机器故障诊断中的应用综述

关于神经网络在故障诊断中的应用的文献如表5所示,根据诊断对象分为包括滚动轴承、齿轮、电机、发动机等五类。在方法上,BPNN、径向基函数网络(RBFN)和小波神经网络(WNN)被广泛应用于完成诊断任务。一些研究者进一步研究了用于机器故障诊断的神经网络的种类。Merainani等[95]利用自组织特征映射神经网络(self-organizing feature map neural network)识别自动变速箱在不同运行模式下的健康状态。Wong等[96]提出了用于轴承故障诊断的改进自组织映射。Yang等[71]利用具有自适应共振理论(adaptive resonance theory)的Kohonen神经网络构建了转子系统的诊断模型,获得了比传统RBFN更高的诊断精度。Chen等[97]采用概率神经网络对水轮发电机组进行高效故障诊断。Zhong等[98]提出了一种用于转子系统故障诊断的层次神经网络(hierarchical ANN)方法,该方法将标签空间划分为多个子空间,可以识别多个故障。Barakat等[99,100]引入生长神经网络(growing neural network)构建电机轴承诊断模型,与传统RBFN和概率神经网络相比,该模型在大量数据下获得了更高的诊断准确率。
由于ANN的诊断模型具有很强的自学习能力,能够从输入数据中自动学习诊断知识,最大限度地降低经验风险。此外,它们可以很容易地识别机器的多种状态。然而,有两个缺点。首先,随着监测数据输入的增加,诊断模型的复杂性会大大提高。模型参数的增加降低了训练效率,进而导致过拟合,降低了诊断模型的诊断精度。其次,基于人工神经网络的诊断模型缺乏严格的理论支持,存在“黑盒”现象。因此,它们的可解释性很低。
2.4.3 基于支持向量机(SVM)的方法
支持向量机是一种有监督学习方法,在分类任务中受到广泛关注。本节简要回顾支持向量机的理论,并总结其在机器故障诊断中的应用。
2.4.3.1 SVM简介
假设数据集
(5)
其中
(6)
如图4所示,支持向量H1和H2满足式(6)中的约束条件,线性支持向量机在正负数据集之间放置一个超平面
(7)
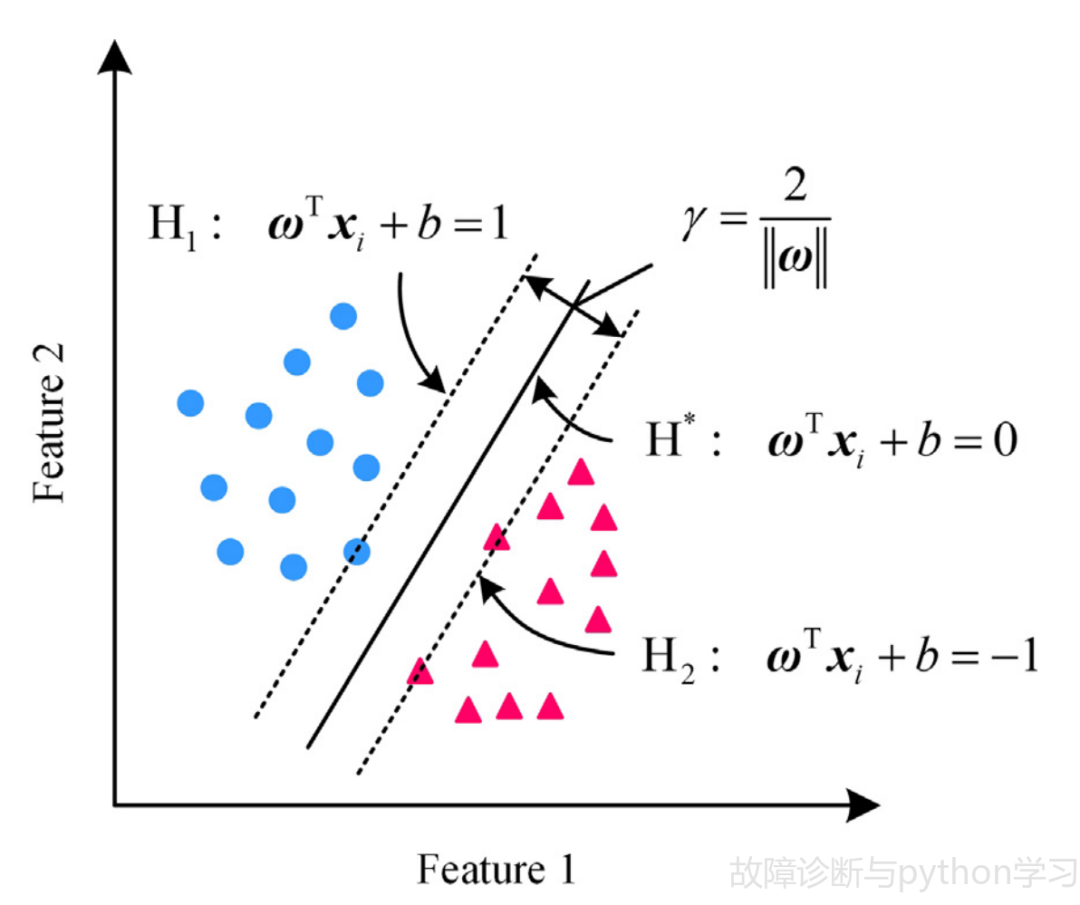
图 4 线性支持向量机分类
2.4.3.2 SVM在故障诊断的应用
表 6 线性支持向量机分类
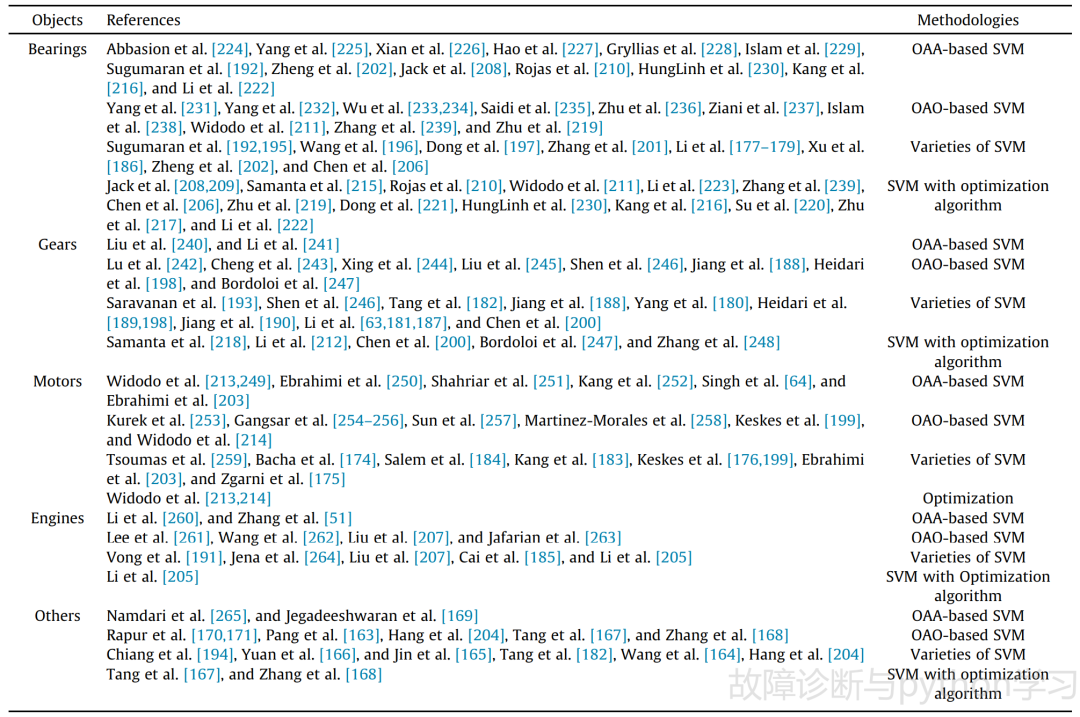
表6详细总结了SVM在IFD中的应用。研究结果表明,支持向量机在健康状态识别中是一种广泛使用的机器学习方法,尤其适用于滚动轴承、齿轮、电机、发动机、转子系统[163-168]和液压设备[169-171]的故障诊断。对于这些诊断对象,基于支持向量机的诊断模型期望能识别多种状态,而不仅仅是健康和故障的二种状态。因此,本文主要讨论了一对多策略(one-against-all strategy, OAA)和一对一策略(one-against-one strategy, OAO)[17]。Platt等人[172]和Hsu等人[173]比较了OAA和OAO的性能,为选择先验策略以获得更好的诊断准确率提供了有价值的建议。此后,又有文献进一步介绍了支持向量机应用中的一些先进的多类策略,如直接无环图[174-176]和二叉树[164-166,177-185],有效地克服了OAA和OAO的缺点。为了提高基于支持向量机模型的诊断准确率,研究人员主要关注两个分支,即改进支持向量机和算法优化。对于前者,他们修改后的支持向量机应用于机械故障诊断,如最小二乘支持向量机(63,165,186-191),近端SVM(192-194),一类SVM[195],超球面SVM[196],小波SVM(182,189,197-200),集成SVM [201,202],模糊SVM[203,204],多核SVM[205,206],和相关向量机[207],其诊断性能优于传统的基于SVM的方法。此外,还对算法进行了优化,改进了复杂的求解方法,简化了支持向量机的参数选择。为了达到这一目的,一些研究者引入了优化算法,如内核Adatron算法[208,209]、序列最小优化[210,214]、遗传算法[209,215-218]、粒子群算法(particle swarm optimization)[167,205,206,219-222]、蚁群算法(ant colony optimazation)[168,22]
与ANN不同,基于SVM的诊断模型是通过最小化结构风险来训练的,由于理论严谨,有利于提高模型的可解释性。支持向量机的优化目标解为凸二次优化,使诊断模型易于获得全局最优解,从而获得较高的诊断准确率。基于支持向量机的诊断模型需要考虑三个缺点。首先,这种诊断模型能够有效地处理少量的监测数据。但是,由于数据量大,拟合困难,导致计算量大。其次,基于支持向量机的诊断模型性能对核参数敏感。不适当的核参数甚至不能产生可靠的诊断结果。第三,SVM算法最初是用来解决二分类任务的。对于IFD中的多类分类任务,往往需要使用复杂的体系结构,如OAA和OAO,来集成多个基于SVM模型的结果。
2.4.1 其它方法
除了前面提到的方法外,IFD中还广泛关注其他方法,如kNN、PGM和决策树。我们将在本小节中回顾它们
2.4.4.1 K近邻(k nearest neighbors, kNN)
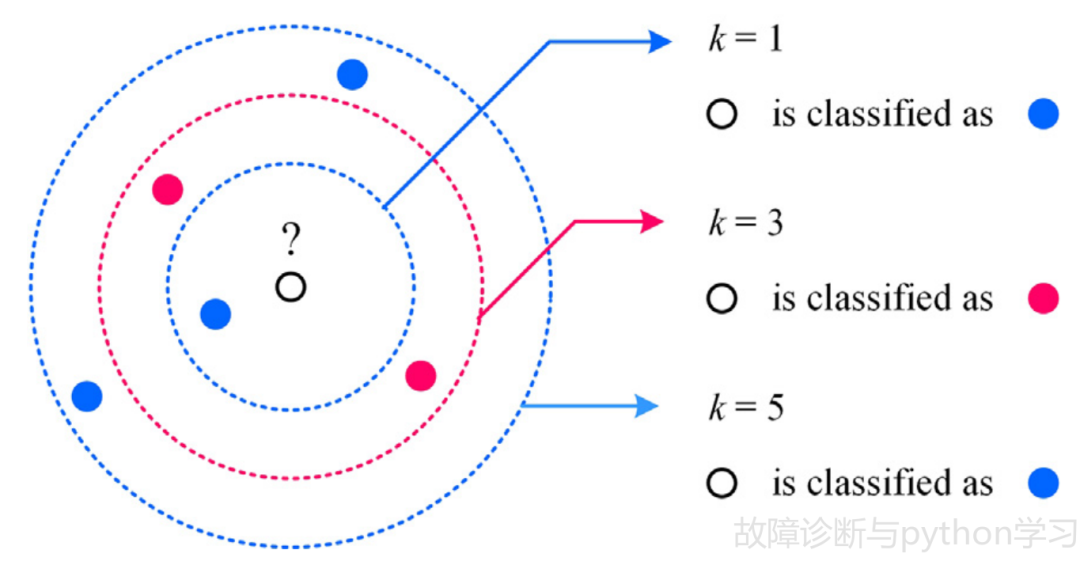
图 5 kNN算法描述
kNN是一种常用的监督学习模型,用于完成分类任务[13]。该方法利用距离度量在给定的未标记样本附近搜索
基于kNN的诊断模型易于实现。然而,处理大的进化数据集需要大量的计算。特别是收集到的数据分布不均衡,会降低这类诊断模型的诊断准确率。此外,k参数难以确定,极大地影响了诊断模型的性能。
2.4.4.2 PGM(Probabilistic Graphi-cal Model)
PGM是一种概率模型,通过图形架构来表达变量之间的关系。在模型中,notes表示一组随机变量,notes之间的联系表示变量之间的概率关系,如图6所示。
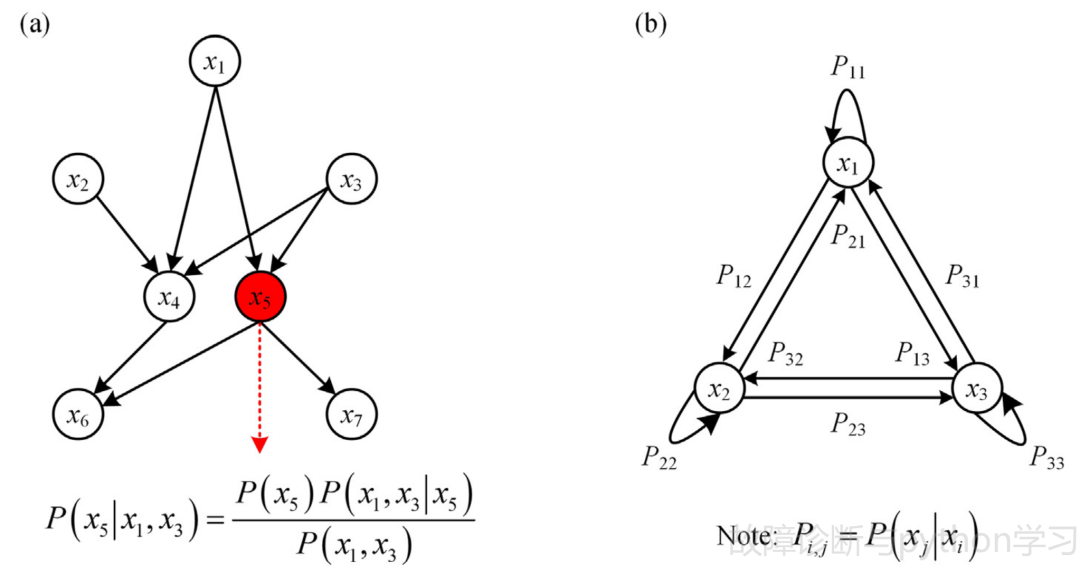
图 6 PGM的说明:
(a)贝叶斯分类器,(b)隐马尔可夫模型。
PGM可以分为两类,即贝叶斯分类器和隐马尔可夫模型。对于前者,Yuan等[284]和Yu等[285]使用朴素贝叶斯分类器分别识别滚动轴承和齿轮的健康状态。为了获得比传统朴素贝叶斯分类器更高的诊断准确率,Yu等人[286,287]进一步将普通朴素贝叶斯分类器和柔性朴素贝叶斯分类器用于齿轮故障诊断。注意到朴素贝叶斯分类器的应用受制于特征之间的独立性假设。非朴素贝叶斯分类器[288]的发展是为了释放假设,它也被用于轴承[289]和齿轮[290]的故障诊断。在轴承[291-295]、同步电机[296]和液压泵[297]的健康状态识别中,将隐马尔可夫模型作为分类器。一些研究进一步改进了隐马尔可夫模型。Xiao等人[298]提出了一种基于耦合隐马尔可夫模型的轴承故障诊断模型,该模型有利于利用多个状态序列和观测序列融合多通道信息。Huang等人[299]利用预测神经网络和直觉模糊集确定隐马尔可夫模型的观测矩阵,提高了电机驱动系统的诊断精度。
基于PGM的诊断模型可以很容易地对机器的多个健康状态进行故障诊断。它们可以很方便用来分析阶级间的差异。然而,这种诊断模型由于数据拟合能力较低,难以表达复杂的函数关系。此外,如果变量之间的概率关系不明确的话,则很难构建诊断模型。
2.4.4.3 决策树
决策树也是分类中常用的监督学习方法,它通过树形结构建立类与属性之间的关系,如图7所示。

图 7 决策树的说明
在所提出的方法中,C4.5算法被广泛用于归纳决策树进行分类,得到了满意的准确率和易于理解的分类规则[300]。将C4.5诱导决策树引入到滚动轴承[82,301,302]、齿轮箱[303]、转子系统[304]和离心泵[305]的故障诊断中。为了提高决策树的泛化性能,本文进一步研究了随机森林[306]基于多重树的分类器的集成决策。在IFD中,决策树和扩展随机森林(extended random forest)已经应用了几十年,并取得了一些成果。Yang等[307]讨论了随机森林分类器在感应电机故障诊断中的应用。Li等人[46]采用随机森林对齿轮箱上多个分类器的诊断结果进行融合,获得了比其他融合工具更高的诊断准确率。Wang等[308]提出了一种基于随机森林分类器的滚动轴承故障诊断模型。Tang等[309]采用粒子暖优化算法选择随机森林的最优参数,提高了轴承的诊断性能。
基于决策树的诊断模型具有自然解释的特点,不依赖于专家的解释,易于转换为诊断规则。此外,它们还可以完成数据缺失的诊断任务。然而,此类诊断模型容易陷入过拟合,泛化性能较差,降低了模型在诊断任务中的诊断性能。此外,树型模型大多是根据专家知识构建的。
2.5 结语
本节回顾了传统的IFD,将诊断过程分为三个步骤,即数据收集、人工特征提取和健康状态识别。这种诊断方法有两个缺点[310]。首先,人工特征提取的步骤需要人工劳动,工程师需要设计强大的算法来提取机器健康状态的敏感特征。但是,由于人工成本巨大,工程师通过专家经验从大容量的监测数据中提取专业特征仍然是不现实的。其次,传统诊断模型的泛化性能和自学习能力较差,无法有效地衔接海量采集数据与健康状态之间的关系,降低了诊断准确率。因此,研究能够同时从原始采集数据中提取特征并自动识别机器健康状态的诊断模型是当务之急。
注明
1、由于本文翻译篇幅过大,本篇到此结束,下一篇将介绍机器学习在故障诊断的现在阶段发展历程。
参考文献
[1]Y. Lei, B. Yang, X. Jiang, F. Jia, N. Li, and A. K. Nandi, "Applications of machine learning to machine fault diagnosis: A review and roadmap," Mechanical systems and signal processing, vol. 138, p. 106587, 2020-01-01 2020.


