论文学习|第三篇-综述-无监督深度迁移学习在智能故障诊断中的应用: (数据集、对比研究)

非常尊重并感谢科研人员做出的辛勤贡献!若有侵权,烦请联系处理!
若有翻译不当之处,恳请批评指正!
本篇综述详细阐述了智能故障诊断中比较热门的无监督学习迁移学习方法(UDTL),包括定义及分类、已有学者工作、开源基准代码等。适合迁移学习方向初学者系统学习入门。
本篇将介绍第4篇:数据集、对比研究
正文共: 9530字 24图
预计阅读时间: 24分钟
论文信息
论文题目:Applications of Unsupervised Deep Transfer Learning to Intelligent Fault Diagnosis: A Survey and Comparative Study
期刊、年份:Transaction on instrument and measurement,2021
作者:Zhibin Zhao, Qiyang Zhang, Xiaolei Yu, Chuang Sun, Shibin Wang, Ruqiang Yan, Xuefeng Chen
机构:The State Key Laboratory for Manufacturing Systems Engineering, Xi’an Jiaotong University, Xi’an 710049, China
目录
1. 引言
2. 背景和定义
2.1 UDTL的定义
2.2 基于UDTL的IFD分类
2.3 基于UDTL的IFD动机
2.4 主干网络的结构
3. 标签一致的UDTL(Label-consistent UDTL)
3.1 基于网络的UDTL(Network-based UDTL)
3.2 基于实例的UDTL(Instance-based UDTL)
3.3 基于映射的UDTL(Mapping-based UDTL)
3.4 基于对抗的UDTL(Adversarial-based UDTL)
4. 标签不一致的UDTL(Label-inconsistent UDTL)
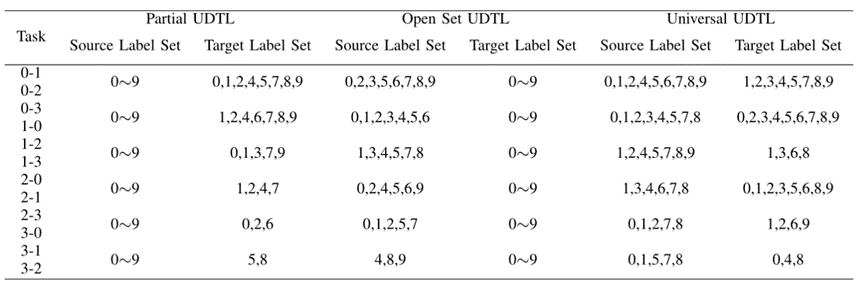
4.1 部分UDTL(Partial UDT)
4.2 开放集UDTL(Open set UDTL)
4.3 通用UDTL(Universal UDTL)
5. 多域UDTL
5.1 多域适应(Multidomain Adaptation)
5.2 域泛化(Domain Generalization)
6. 数据集
6.1 公开数据集
(1)凯斯西储大学数据集(Case Western Reserve University,CWRU)
(2) 帕德博恩大学数据集(Paderborn University,PU)
(3) 江南大学数据集(JiangNan University,JNU)
(4) PHM2009年比赛数据集
(5)东南大学数据集(Southeast University,SEU)
6.2 数据分割
7. 对比研究
7.1 训练细节
7.2 标签一致UDTL
7.3 标签不一致UDTL
8. 进一步讨论
8.1 特征可迁移性
8.2 主干网络和瓶颈层的影响
8.3 负迁移
8.4 物理先验(Physical priors)
8.5 标签一致迁移
8.6 多域迁移
8.7 其它方面
9. 总结
摘要
近年来,智能故障诊断的发展很大程度上依赖于深度表征学习和大量的带标签数据。然而,机械设备通常在不同的工作环境下运行,或者目标任务与收集到的训练数据有不同的分布(域偏移问题)。此外,新收集的测试数据在目标域通常是无标签的,基于此提出基于无监督深度迁移学习(unsupervised deep transfer learning,UDTL)的智能故障诊断(Intelligent fault diagnosis,IFD)方法。虽然它已经取得了巨大的发展,但还没有建立一个标准的开放源代码框架和基于UDTL的IFD的对比研究。在本文中,我们构建了一个新的分类方法,并根据不同的任务对基于UDTL的IFD进行了全面的综述。通过对一些典型方法和数据集的比较分析,揭示了基于UDTL的IFD中一些尚未被研究的开放性和本质问题,包括特征的可转移性、主干网络的影响、负迁移、物理先验等。为了强调基于UDTL的IFD的重要性和可重复性,将向研究界发布整个测试框架,以促进未来的研究。综上所述,发布的框架和对比研究可以作为开展基于UDTL的IFD新研究的扩展接口和基础成果。代码框架可以在https://github.com/ZhaoZhibin/UDTL上找到。
关键词: 对比研究, 智能故障诊断(IFD), 可重复性(Reproducibility), 分类和调查(Taxonomy and survey), 无监督深度迁移学习(UDTL)
Ⅵ 数据集
A 开源数据集
开源数据集对于不同算法的开发、比较和评估非常重要。在这个比较研究中,我们主要测试5个数据集来验证不同UDTL方法的性能。五个数据集的详细描述如下。
1)凯斯西储大学(Case Western Reserve University, CWRU)数据集:CWRU轴承数据中心提供的CWRU数据集[169]是IFD中最著名的开源数据集之一,已经被大量发表的论文使用。在其他论文之后,本文还使用了采样频率为12kHz的驱动端轴承故障数据,表2中列出了10种轴承状态。在表2中,1个正常轴承(NA)和3种故障类型,包括内圈故障(IF)、滚动体故障(BF)和外圈故障(OF),根据故障大小的不同,分为10类(1种健康状态和9种故障状态)。
另外,如表3所示,CWRU由4个电机负载组成,分别对应4个运行转速。对于迁移学习任务,本文将这些工作条件视为不同的任务,包括任务0、1、2、3。例如,任务0→1表示电机负载为0HP的源域转移到电机负载为1HP的目标域。迁移学习任务共有12个。
表2 CWRU的类别标签的描述
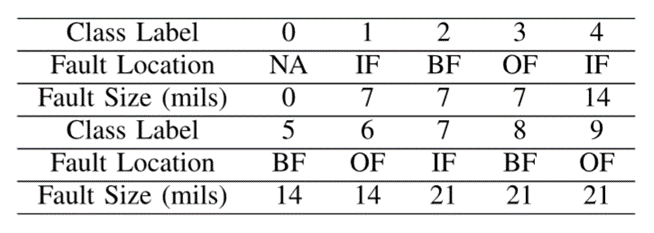
表3 CWRU迁移学习任务
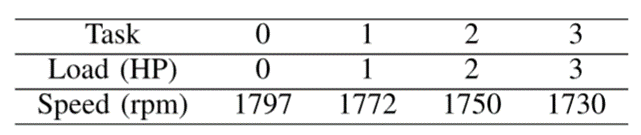
2)Paderborn University(PU)数据集:PU获得的PU数据集为轴承数据集[170],[171],由人为损伤和真实损伤两部分组成。采样频率为64kHz。通过改变驱动系统的转速、施加在测试轴承上的径向力和驱动系统上的负载扭矩,PU数据集由四种操作条件组成,如表4所示。
表4 迁移学习任务和运行参数

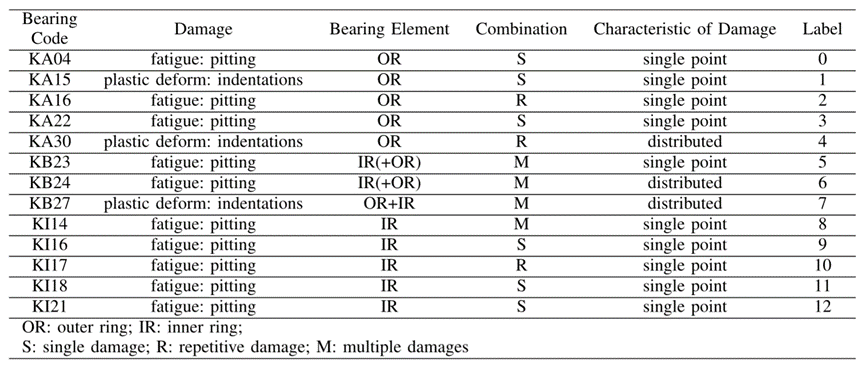
采用加速寿命试验[170]中13个存在实际损伤的轴承,研究不同工作条件下的迁移学习任务(每个轴承代码进行20次实验,每次实验持续4秒)。分类信息如表5所示(内容含义见[170])。总共有12种迁移学习设置。
表5 真实故障的轴承信息
3)江南大学数据集:江南大学数据集为江南大学获取的轴承数据集。江南大学数据集可从[172]处下载,更多详细信息可参考[173]。对NA、IF、OF、BF 4种健康状态进行了测试。在三种转速下采样振动信号(600、800和1000rpm),采样频率为50kHz。设置为600、800和1000rpm的四个转速被认为是不同的任务,分别表示为任务0、任务1和任务2。总共有六种迁移学习设置。
4)2009PHM数据挑战(PHM2009)数据集:PHM2009数据集是PHM数据挑战赛提供的通用工业齿轮箱数据集[174]。采样频率设置为200kHz;共进行了14次试验(8次直齿轮试验,6次斜齿轮试验)。
在本文中,我们利用从安装在输入轴固定板上的加速度计收集的斜齿轮数据集(六种情况)。PHM2009包含5个转速和2个载荷,但只考虑前4个轴转速在高载荷下的数据。设置为30Hz、35Hz、40Hz和45hz的四个转速作为不同的任务,分别表示为任务0、任务1、任务2和任务3。总共有12种迁移学习设置。
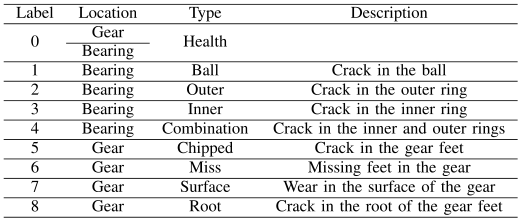
5)东南大学数据集(Southeast University, SEU):东南大学数据集是东南大学提供的齿轮箱数据集[33],[175]。该数据集由2个子数据集组成,包括轴承和齿轮数据集,这两个子数据集都来自传动系统动力学模拟器。收集了8个通道,我们使用通道2的数据。如表6所示,每个子数据集由5种轴承健康状态组成:一个健康状态和4个故障状态。
将转速负载配置为20Hz-0V和30Hz-2V的两种工况视为不同的任务,分别记为任务0和任务1。总的来说,有2种迁移学习方式设置。
表6 SEU的迁移学习任务
B 数据预处理和数据分割
数据预处理和分割是基于UDTL的IFD性能的两个重要方面。虽然基于UDTL的方法往往具有自动特征学习能力,一些数据处理步骤可以帮助模型达到更好的性能,如短时傅里叶变换(STFT)在语音信号分类和图像分类中的归一化。此外,在训练阶段经常存在一些陷阱,特别是测试泄漏。也就是说,测试样本在训练阶段被无意识地使用。
1)输入类型:本文测试了两种输入类型,包括时域输入和频域输入。前一种直接使用信号作为输入,采样长度为1024,不存在重叠。后一种方法是先将信号变换到频域,由于谱系数的对称性,采样长度为512。
2)归一化:数据归一化是基于UDTL的IFD的基本过程,可以将输入值保持在一定范围内。在本文中,我们使用Z-score归一化。
3)数据分割:由于本文没有使用验证集来选择最佳模型,因此这里忽略验证集的分割。在基于UDTL的IFD中,训练过程中使用目标域的数据来实现域对齐,并作为测试集。事实上,这两种情况下的数据不应该重叠;否则会出现测试泄漏。因此,如图6-1所示,我们在源域和目标域取80%的总样本作为训练集,20%的总样本作为测试集,以避免这种测试泄漏。
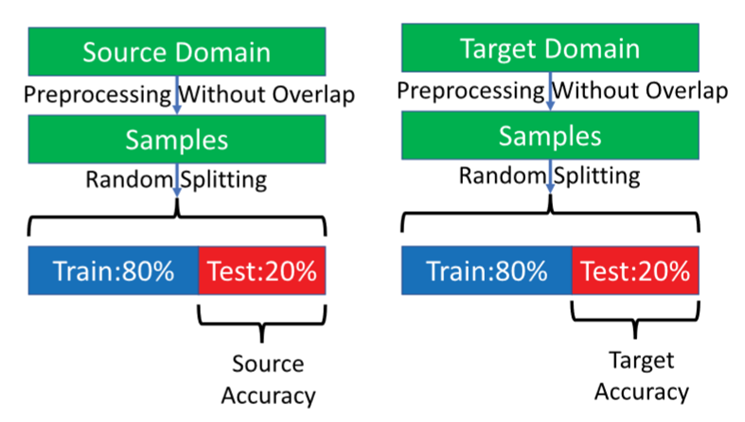
图6-1 基于UDTL的IFD的数据分割
Ⅶ 对比研究
我们将在本节中讨论评估结果。为了使准确性可读性高,我们使用一些可视化方法来呈现结果。
A 训练细节
我们在Pytorch中实现了所有基于UDTL的IFD方法,并将它们放入一个统一的代码框架中。每个模型训练300个epoch,在训练过程中模型训练和测试过程交替进行。我们采用小批量Adam优化器,批量大小等于64。采用Pytorch中的步进策略作为学习率退火方法,初始学习率为0.001,分别在150和250时衰减(乘以0.1)。我们使用一种渐进训练方法,通过乘以
B 标签一致的UDTL
对于MK-MMD、JMMD、CORAL、DANN和CDAN,我们使用前50个epoch源域样本对模型进行训练,得到所谓的预训练模型,然后激活迁移学习策略。对于AdaBN,我们用三个额外的epoch批次更新BN层的统计信息。
1)评价指标:为了简单起见,我们使用整体准确率来验证不同模型的性能,即正确分类的样本数量除以测试数据中的样本总数。为了避免随机性,我们进行了5次实验,并使用总体精度的平均值和最大值来评估最终性能,因为5次实验的方差在统计上没有用处。在本文中,我们用最后一个epoch的平均精度和最大精度(last-mean和last-max)来表示没有任何测试泄漏的测试精度。同时,我们还列出了平均精度和最大精度,在模型达到最佳性能的时期表示为best-mean和best-max。
2)数据集的结果:为了更清晰的对比,我们总结了所有方法中不同数据集的平均最高准确率,结果如图7-1所示。我们可以观察到CWRU和JNU数据集的准确率可以达到95%以上,其他数据集的准确率只能达到60%左右。值得一提的是,由于很难对每个参数进行详细的调整,精度只是一个下界。
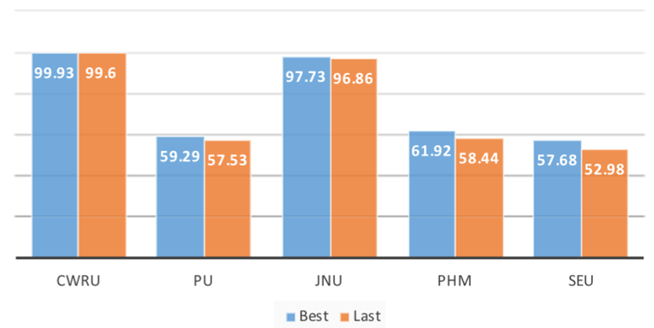
图7-1 所有方法中不同数据集的最高平均准确度
3)模型的结果:不同方法的结果如图7-2至7-6所示,图7-6没有设置为雷达图,因为有两个传输任务不适合进行这种可视化。对于所有的数据集,本文讨论的方法都可以提高基准模型的准确性,但CORAL除外。对于CORAL,其只能在频域输入或某些迁移任务中提高CWRU的精度。对于AdaBN,其改进效果比其他方法小得多。
4)总体而言,JMMD的结果优于MK-MMD,这表明源域和目标域联合分布的假设有助于提高性能。DANN和CDAN的结果普遍优于MK-MMD,这表明对抗性训练有助于对域偏移进行对齐。
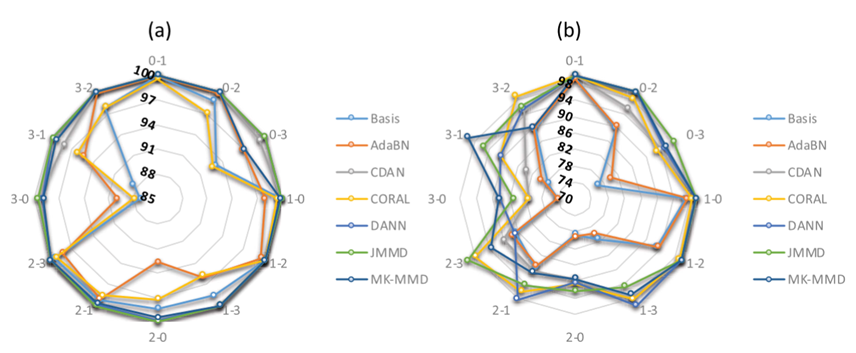
图7-2 CWRU中不同方法的精度比较。(a)时域输入(%),(b)频域输入(%)

图7-3 PU中不同方法的精度比较。(a)时域输入(%),(b)频域输入(%)

图7-4 JNU中不同方法的精度比较。(a)时域输入(%),(b)频域输入(%)

图7-5 PHM2009中不同方法的精度比较。(a)时域输入(%),(b)频域输入(%)
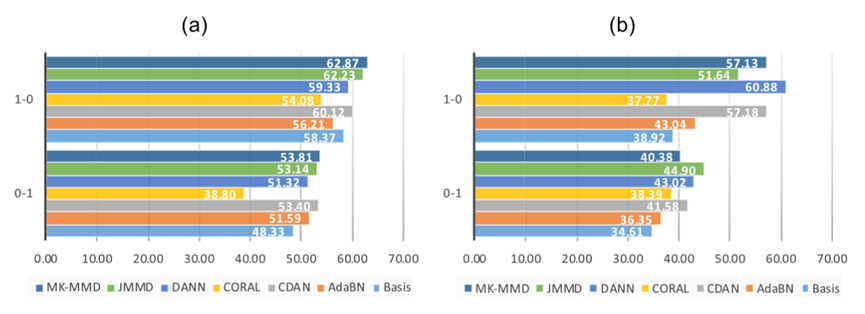
图7-6 SEU中不同方法的精度比较。(a)时域输入(%),(b)频域输入(%)
4)输入类型结果:两种输入类型的精度比较如图7-7所示,CWRU、JNU和SEU的时域输入精度较好,PU和PHM2009的频域输入精度较好。另外,这两种输入类型的准确率差距比较大,由于主干网络的影响,我们不能简单地推断出哪一种输入类型更好。因此,对于一个新的数据集,我们应该测试不同输入类型的结果,而不是仅仅使用更高级的技术来提高一种输入类型的性能,因为使用不同的输入类型可能比使用高级技术更有效地提高准确性。
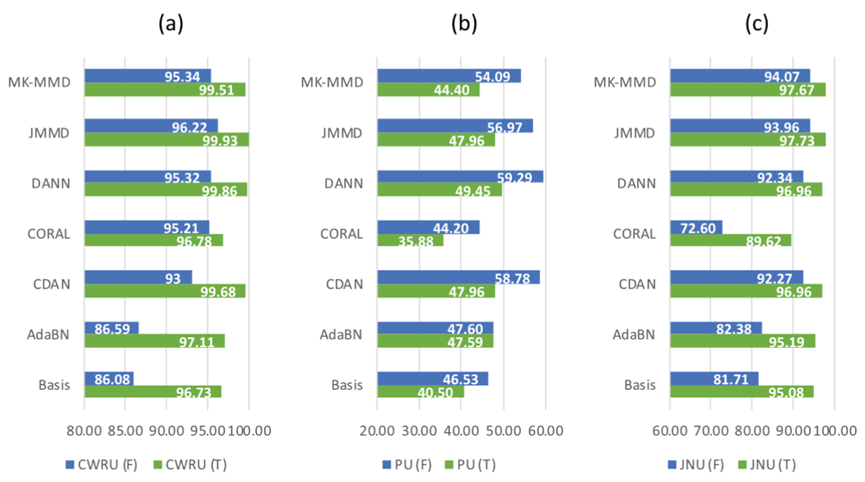

图7-7 两种输入类型与不同数据集的准确性比较。
(F)表示频域输入,(T)表示时域输入。
(a)具有两种输入类型(%)的CWRU。(b)两种输入类型的PU(%)。
(c)两种输入类型的JNU(%)。(d)具有两种输入类型(%)的PHM。
(e)两种输入类型的SEU(%)
表7 CWRU的诊断任务
5)精度类型的结果:如第七节所述,我们使用四种精度,包括best-mean, best-max, last-mean和last-max来评估性能。如图7-8所示,不同实验的波动有时较大,尤其是对于总体精度不是很高的数据集,这说明所使用的算法具有不是很好的稳定性和鲁棒性。此外,时域输入的波动似乎比频域输入的波动小,这可能是因为本文使用的主干网络更适合于时域输入。
如图7-9所示,不同实验的波动也很大,这使得难以评估其真实性能。由于best使用测试集来选择最佳模型(这是一种测试泄漏),last可能更适合表示泛化精度。
因此,一方面,基于UDTL的IFD的稳定性和鲁棒性需要更多的关注,而不仅仅是提高准确性。另一方面,正如我们前面所分析的,当best和last之间波动较大时,最后一个epoch的精度更适合表示算法的泛化能力。

图7-8 根据最佳平均值的最大值和平均值之间的差异。
(a) 时域输入的最大值与平均值 (%), (b) 频域输入的最大值与平均值 (%)
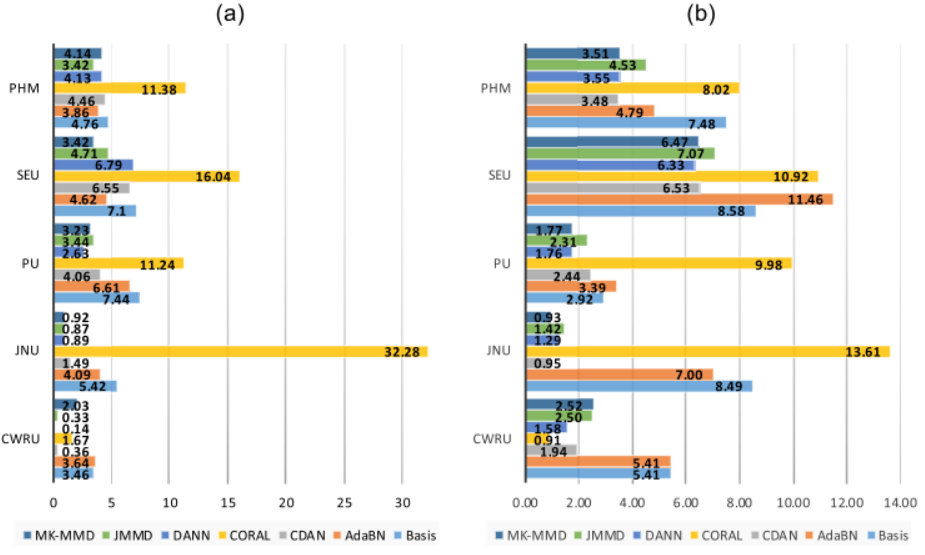
图 7-9 根据平均值,最佳平均值和最后平均值之间的差异。
(a) 时域输入的最佳与最后 (%)。,(b) 频域输入 (%) 的最佳与最后一个。
C 标签一致的UDTL
在这些方法中,迁移学习策略从一开始就被激活。对于UAN,非对抗域鉴别器损失权衡参数固定为1。对于所有任务,OSBP的值τ和UAN的阈值
1)评价指标:对于部分迁移学习,评价指标与标签一致的UDTL相同,包括last-mean、last-max、best-mean和best-max。对于开放集和通用迁移学习,由于未知类别的存在,仅凭整体精度不足以评价模型的性能。为了清楚地解释评价指标,定义了几个数学符号。
a)共享类的精度:
与标签一致的UDTL类似,总体精度的平均值和最大值用于评估最终性能。我们使用所有五个评估指标在最后一个epoch的平均精度表示为Last-Mean-ALL*,Last-Mean-UNK,Last-Mean-OS,Last-Mean-All和Last-Mean-H-score。我们使用模型在last epoch的5个测试中,即Last-Mean-ALL*,Last-Mean-UNK,Last-Mean-OS,Last-Mean-All和Last-Mean-H-score中表现最好的精度。同时,我们还列出了模型在H-score上表现最好epoch的平均精度,分别记为Best-Mean-ALL*,Best-Mean-UNK,Best-Mean-OS,Best-Mean-All和Best-Mean-H-score。我们还列出了模型在五个测试中H-score的表现最好的精度Best-Max-ALL*,Best-Max-UNK,Best-Max-OS,Best-Max-All和Best-Max-H-score。
2)数据集设置:选择CWRU进行性能测试。在[150]最近的研究中,随机选取不同的类别组成迁移学习任务,以验证模型在不同标签集上的有效性。部分迁移学习、开放集迁移学习和通用迁移学习的故障诊断任务分别在表7中给出。
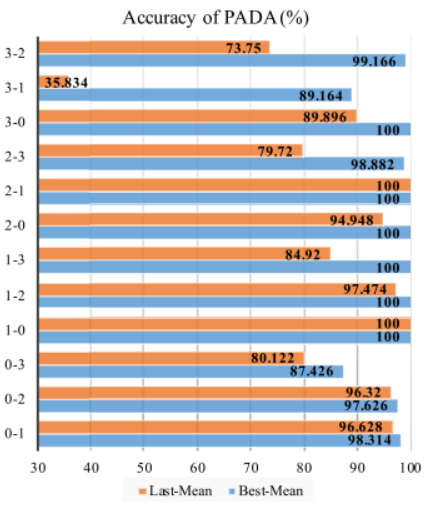
图7-10 PADA 与时域输入的整体精度
3)部分UDTL的结果:为了简单起见,如图7-10,由于时域和频域输入之间的相似性,我们只列出了时域输入的PADA的best-mean和last-mean。我们可以观察到,整个训练阶段中,PADA在大多数任务上都可以取得较好的表现。但对于任务3-1、2-3和3-2,last-mean明显低于best-mean,说明PADA不能完全解决额外源域标签造成的负迁移,在训练过程中存在过拟合问题。
4)开放集UDTL的结果:时域输入下OSBP的best-mean和last-mean精度如图7-11所示。从图7-11(a)可以看出,OSBP在大多数迁移任务上都能取得较好的性能。但是,如图7-11(b)所示,后期性能明显下降,特别是对于UNK,这表明模型对源域样本过拟合,因此无法有效识别未知类样本。此外,最低的ALL*只有50%左右,这意味着只有一半的共享类样本可以被正确分类。因此,需要更有效的模型,既能检测未知类样本,又能保证共享类的准确分类。
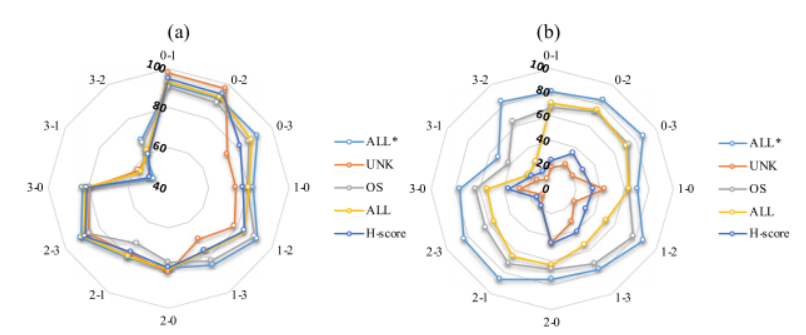
图7-11 OSBP 与时域输入的总体准确度:
(a) OSBP 的最佳均值 (%) , (b) OSBP 的最后均值 (%)
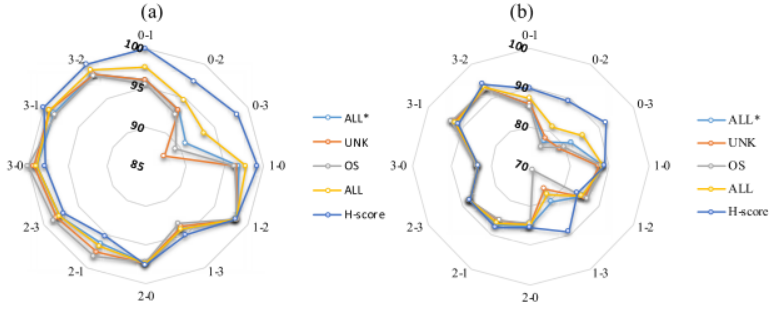
图7-12 UAN 与时域输入的总体准确度:
(a) UAN 的最佳平均值 (%) , (b) UAN 的最后平均值 (%)
5)通用UDTL的结果:基于时域输入UAN的best-maen和last-mean精度如图7-12所示。从图7-12(a)可以看出,总体而言,UAN在CWRU数据集上的表现非常出色。与OSBP的结果相似,由于过拟合问题和错误的特征对齐,UAN的性能在后期也会下降。此外,共享类的分类精度还有待提高。该模型仍然难以从目标域中分离出额外的源类和检测未知类。
6)多标准评价指标的结果:由于我们对开放集UDTL和通用UDTL有5个评价指标,所以最好有一个不同指标的最终得分,以便更好地理解结果。
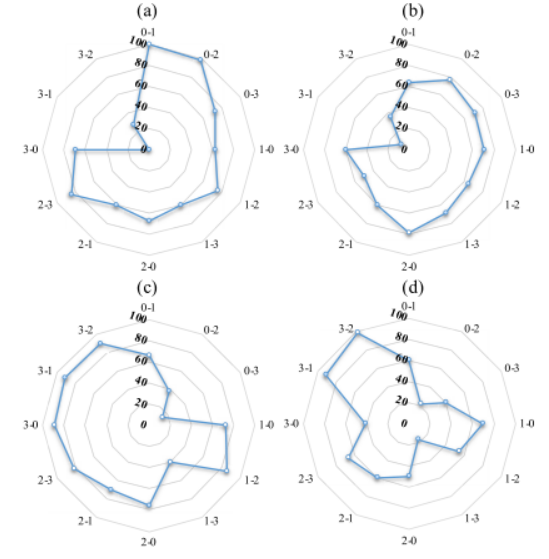
图7-13 OSBP 和 UAN 的 TOPSIS。
(a) OSBP 的best-mean (%),(b) OSBP 的last-mean (%),
(c) UAN 的best-mean (%),(d) UAN 的last-mean (%)
因此,我们采用多准则评价指标中著名的TOPSIS(Technique for Order Preference by Similarity to an Ideal Solution)作为最终得分。同时,TOPSIS也被广泛应用于故障诊断领域[178],[180]。在本文中,我们使用ALL*、UNK、OS、ALL和H-score来计算多准则评价的TOPSIS。为了简单起见,在TOPSIS中每个指标的权重均设置为0.25。如图7-13所示,我们可以观察到OSBP和UAN对于不同迁移学习任务的TOPSIS比较。使用TOPSIS的评估与图7-11和图7-12中的这些指标相似,这并不意外。由于过拟合问题和错误的特征对齐,在后期整体性能也会下降。共享类分类精度有较大的提升空间。此外,分离额外源类和在目标域中检测未知类的问题也没有得到很好的解决。
D 多域UDTL
对于多域UDTL,评估指标与标签一致的UDTL相同,包括last-mean、last-max、best-mean和best-max。
1)数据集设置:与标签不一致的UDTL类似,选择CWRU测试多域UDTL的性能,包括MS-UADA和IAN。输入的类型包括时域输入和频域输入。多域UDTL的故障诊断任务如表8所示。例如,123-0_T意味着任务1、2和3(如表8所示)被用作多个源域;任务0用作目标域;并将时域输入作为模型输入。需要指出的是,在测试DG性能时,我们并没有在训练阶段使用目标数据。
表8 多域UDTL的任务

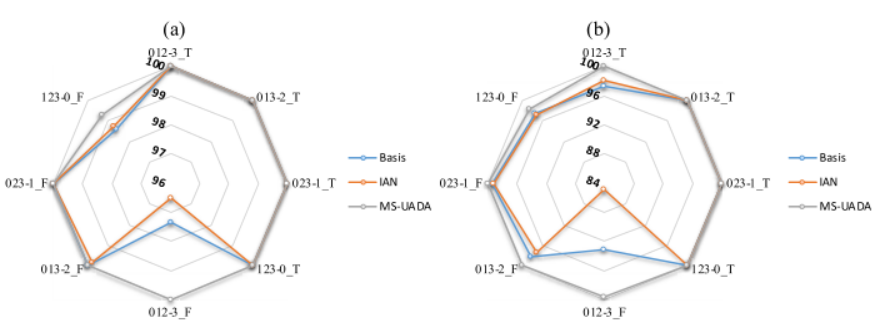
图7-14 多域 UDTL 的总体精度(F和T分别表示时域和频域输入)
(a) 多域 UDTL 的best-mean (%),(b) 多域 UDTL 的last-mean (%)
2)多域适配结果:如在图7-14(a)和(b)中,我们可以观察到MS-UADA总能提高CWRU的精度,CWRU直接将多源域训练的模型迁移到目标域。时域输入的性能略好于频域输入,但总体差别很小。
3)DG的结果:如图7-14(a)和(b)所示,我们可以观察到IAN对于CWRU的表现和大多数任务中的基准模型表现是相似的。然而,对于任务012-3_F,IAN的准确率大大降低。主要原因可能是IAN只使用多个源域来寻找域不变特征,不适合不可见的目标域。因此,需要进一步设计更复杂的DG方法来挖掘具有鉴别性和域不变性的特征。
注明
1、由于本文翻译篇幅过大,本篇到此结束,下一篇将介绍进一步讨论、总结
2、若需引用本文的公式、专业术语等内容建议再细读原论文核实;若本文对您的论文idea有帮助,建议引用原论文~
参考文献
[1]Z. Zhao et al., "Applications of Unsupervised Deep Transfer Learning to Intelligent Fault Diagnosis: A Survey and Comparative Study," in IEEE Transactions on Instrumentation and Measurement, vol. 70, pp. 1-28, 2021, Art no. 3525828, doi: 10.1109/TIM.2021.3116309.


