论文学习|第六篇(2)-研究论文-基于多特征融合和Adaboost-SVM的铣削颤振检测

非常尊重并感谢科研人员做出的辛勤贡献!若有侵权,烦请联系处理!
若有翻译不当之处,恳请批评指正!
本篇研究论文针对铣削加工过程中的颤振检测问题,提出了特征融合方法,并且组合了传统手工提取的特征和基于机器学习的自动提取的特征,最后提出了改进的自适应增强算法,利用一系列支持向量机的弱分类器构建强分类器,实现了变工况和错误标签条件下的颤振检测分类。本文对颤振检测研究方法展开说明,介绍了颤振检测不同的方法和技术,包括传统的特征提取方法和基于机器学习的智能方法。适合于颤振检测、特征融合、信号处理研究领域者学习。
本篇将介绍第2篇(想回看第1篇戳这里):本篇介绍基于堆叠降噪自编码器的自动特征提取以及改进Adaboost-svm的颤振识别,并进行了实验验证和性能分析。
正文共: 6945字13图
预计阅读时间: 18分钟
论文信息
论文题目:Milling chatter detection by multi-feature fusion and Adaboost-SVM
期刊、年份:Mechanical Systems and Signal Processing,2021
作者:Shaoke Wan(a,b,*), Xiaohu Lia(b), Yanjing Yin(a,b,c), Jun Hong(a,b)
机构:(a) Key Laboratory of Education Ministry for Modern Design & Rotor-Bearing System, Xi’an Jiaotong University, Xi’an, Shaanxi, China
(b) School of Mechanical Engineering, Xi’an Jiaotong University, Xi’an, Shaanxi, China
(c) Luoyang Bearing Research Institute Co., Ltd., Luoyang, Henan, China
目录
1. 引言
2. 信号获取与特征提取
2.1 信号获取
2.2 传统特征提取
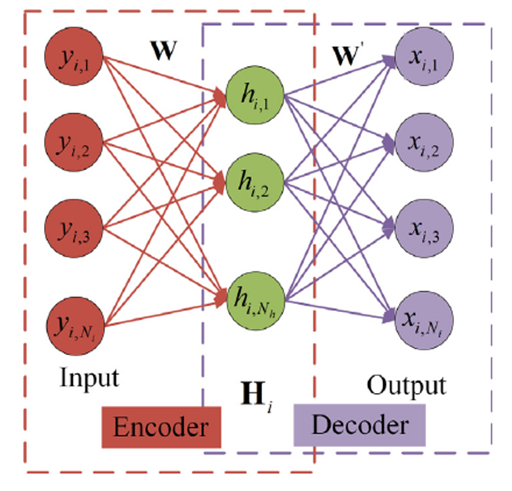
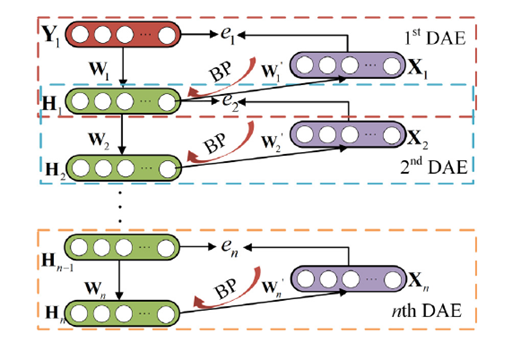
2.3 基于堆叠降噪自编码器的自动特征提取
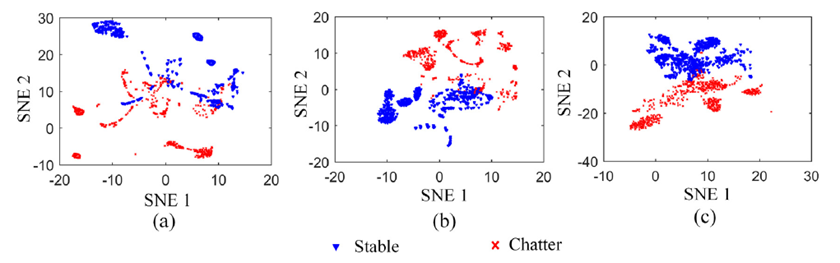
2.4 多特征组合分析
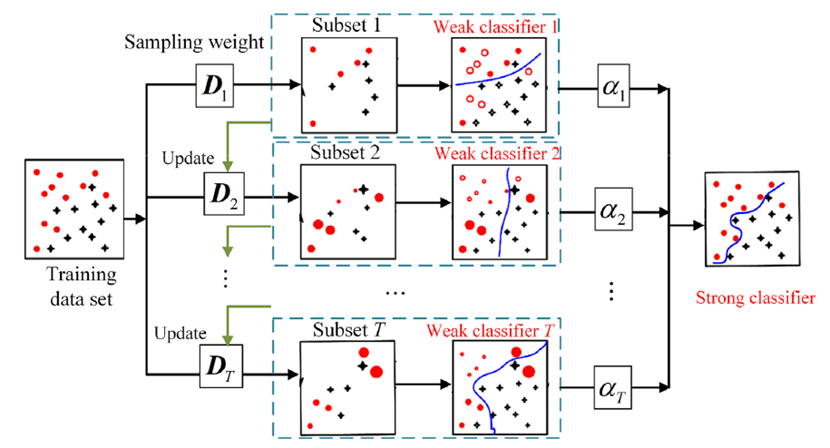
3. 基于改进Adaboost-SVM的颤振识别
4. 验证和性能分析
4.1 具有不同类型多特征的颤振分类性能分析
4.2 考虑错误标签样本的性能分析
4.3 泛化性能分析
5. 结论
摘要
Ⅱ 信号获取与特征提取

Ⅲ 基于改进Adaboost-SVM的颤振识别




Ⅳ 验证和性能分析



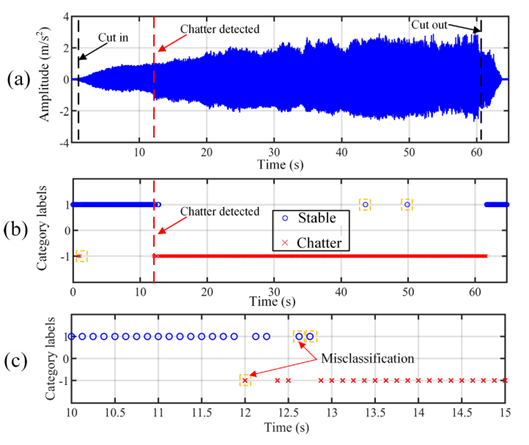
Ⅴ 结论
注明
1、本篇介绍论文的第二部分,整篇内容翻译至此结束。
2、若需引用本文的公式、专业术语等内容建议再细读原论文核实;若本文对您的论文idea有帮助,建议引用原论文~
参考文献
[1] Wan S , Li X , Yin Y , et al. Milling chatter detection by multi-feature fusion and Adaboost-SVM[J]. Mechanical Systems and Signal Processing, 2021, 156(2):107671.


