新论文:融合自然语言处理与上下文无关文法的审图规则自动解译方法
DOI:https://doi.org/10.1016/j.compind.2022.103746
预印本链接:http://dx.doi.org/10.13140/RG.2.2.22993.45921
0 摘要
智能审图或自动设计审查是提升设计效率、质量的关键环节。实现智能审图的关键是让计算机读懂规范并像专业工程师一样进行分析、推理。也就是要把规范、标准等文本自动转换或解译为计算机可处理的逻辑规则代码,从而实现计算机自动推理。
然而,由于规范文本隐含大量领域知识、内容表述复杂,既有规则解译方法仍以人工解译和正则表达式匹配为主,耗时长、适用范围有限。因此,本研究提出一种集成自然语言处理 (Natural Language Processing NLP) 与上下文无关语法 (Context-free Grammar,CFG) 的规则自动解译新方法,可将规范条文视为特定领域语言实现高效解析。首先,研究提出了一种包含多种语义元素的语法树结构来表示规范文本中的概念角色和关系,并构建了开放的规范文本标注数据集,让计算机可以自主学习领域概念的复杂文本特征。接着,引入迁移学习技术与深度学习预训练模型,通过领域先验知识学习,实现了语义元素的自动标注。最后,提出了系列CFG文法规则,实现了标注语句向语言无关逻辑树的自动转换,支持可计算逻辑规则自动生成。实验显示,本文方法相较既有方法优势显著,简单约束句和复杂约束句的解析准确度分别达到了 99.6% 和 91.0% ,突破了既有方法不能处理规范中普遍存在的复杂条文的问题。本研究为规范条文自动解译提供了一种自动、通用的方法框架,可以从规范、标准、合同等各类文本中提取可计算逻辑规则;同时,研究开放了首个规范条文解译数据集,为领域算法开发、测试以及应用提供了重要支撑。
1 亮点总结
提出了一种新颖的规则自动解译框架,支持设计合规检查与智能审图
简单句解析准确率达99.6%,显著优于既有方法
可高效处理既有方法难以处理的复杂句,解析准确率达91.0%
支持从各种法规文本文件中自动创建可计算逻辑规则代码
开源了面向智能审图的第一个规范文本标注数据集,支持相关算法开发及验证
2 研究现状
本文将现有(半)自动规则解译方法分为三类:规则标注(rule annotation)、规则形式化(rule formalization)、规则转换(rule transformation);其中前两者为半自动,最后的为自动化方法。然而,现有方法的局限性在于:无法同时实现较高程度的自动化和较广的适用范围。半自动方法易于理解,适用范围广,但仍需要大量的人工来编写查询语言,伪代码,或标记规范文档等;因此其自动化程度较为低下。对于自动化方法,其大量依赖基于正则表达式的匹配模式,这其实是一种对映射规则进行硬编码的方式。实际上,正则表达式的表达能力较低(如无法表达递归)很容易导致其使用数量的增加(如需要使用大量的正则表达式才能表示一个简单的规则),并变得难以维护。因此,当前的自动化方法通用性与可扩展性较低,适用范围难以拓展。表1对现有规则解译方法与本文要提出的方法进行了总结对比。
表1 现有规则解译方法与本方法的比较

3 规则解译框架
本文提出的自动规则解译方法主要包括以下四个步骤,其框架如图1所示。预处理。此步骤从规则文本中选择出可以转换的句子,并对其进行预处理,例如句子分割。
语义标注。此步骤给句子中的词或短语加上标签以表达语义信息,其中的语义标签能够表示与规则与BIM相关的概念。标注方法为使用神经网络模型通过 BIO格式进行序列标记。语义标注结果可通过计算句子中每个标签的F1分数来验证。
语句解析。此步骤主要使用上下文无关文法(CFG)将带有标签的句子转换为可以表示元素层次与关系的树结构,该树结构是语言无关的,并且可以生成出可计算的检查规则代码。解析结果可通过计算标记的句子解析为树的准确性来验证。
规则生成。此步骤将树表示形式转换成特定格式的语言以便于规则执行,例如if-then语句,horn逻辑子句,编程语言等。

图1 提出的自动规则解译框架
3.1 规则检查树和语义标签定义
建筑规范条文通常包括两种类型的要求:1)定量类要求,2)存在类要求。这两种要求都由三部分组成:1)建筑模型中被检查的元素,2)要求条件或限值,3)前两者的比较关系。BIM模型可以用具有许多属性的对象来描述,这种层次结构可以用树结构表示。因此,规则检查可以看作首先定位BIM模型树结构中的元素,然后检查相应元素是否满足要求的过程。
据此,本研究提出了七个语义元素来表示规范条文中单词或短语的不同语义角色和关系,如表2所定义。同时,提出了表示语义元素的层次结构和关系的语法树结构,称为规则检查树(RCTree):表示对象层次结构和关系的树结构,其中最多一个树节点具有多个子节点,并且至少一个节点连接到一个要求。RCTree 中的节点是一个语义元素,即带有语义标签的单词或短语。图4阐述了不同表示格式的 RCTree。图5展示了语义标注和语句解析的示例。
表2 提出的七个语义元素


图4 提出的RCTree
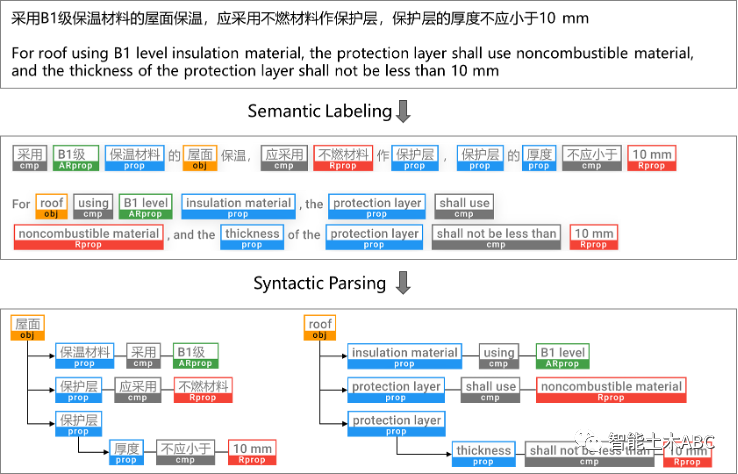
图5 语义标注和语句解析的示例
3.2 语义标注
语义标注是为句子中的单词/短语分配语义标签的过程,其中标记的单词或短语称为语义元素。本文使用深度神经网络(DNN)模型与迁移学习技术进行语义标注。标注方式采用BIO(Begin-inside-outside)格式,如图5所示。使用DNN模型(如RNN或Transformer)的标注过程为:首先,将输入语句的所有字符通过词嵌入转化为向量;然后,使用DNN模型将输入的向量编码转为带有上下文信息的向量表示;最后,这一向量将通过softmax进行分类,并转换为BIO格式以进行输出。

图6 BIO标注格式
3.3 语句解析
语句解析是通过分析带有标签的句子的结构并将其解析为RCTree的过程。本文使用上下文无关文法(CFG)作为解析的语法。CFG相比正则表达式等模式匹配方法具有更高的表达能力(例如可以表示递归)。同时CFG也是编程语言编译器的组成方法。解析步骤共分为三个过程:句子标准化,基于CFG的解析,RCTree生成;如图8所示。

图8 语句解析流程
4 实验结果
4.1 数据集构建
本文选择中国建筑消防规范进行验证。首先,将建筑法规中的文本根据分号、句号、换行符分割为单个句子。接着,对句子进行过滤以选择含有定量要求的句子(例如,“不少于”,“大于”);同时,这些句子将被人工审核以确保其适用于BIM中的规则检查,不适用的句子将被删除。然后,人工开发所选语句的语义标注,形成黄金标准。最终,建立的数据集包含611个句子,4336个语义标签。
数据集中的规范语句按复杂程度分为了两类,其定义分别如下:
现有的规则转换方法大多使用简单的单要求句进行验证和测试,例如使用的句子对于其所提出的各类元素均最多只含一个;而对于复杂的多要求句则往往不考虑。在本文中,单/多要求句一个显著的区别是:在生成的RCTree中,单要求句在obj下仅含有一棵子树,而多要求句有多棵子树。
4.2 语义标注结果
语义标注基于Python语言及Pytorch深度学习库实现,并且使用了中文BERT模型作为预训练的DNN模型。数据集根据0.8:0.2的比例随机分为训练和验证集,其中训练集用于训练和更新DNN模型,验证数据集用于测试性能。为了验证结果,将模型预测输出与黄金标准进行比较,并为每个语义标签计算精确度(Precision),召回率(Recall)和F1分数(F1-score)。经实验,模型在验证集上的测试结果如表4所示。可以看出,模型取得了86.2%,86.3%,和86.2%的综合精确度、召回率和F1分数。这一结果表明,所提出的基于深度学习的语义标注方法能够适用于大规模的长句和复杂句的语义标注,且能获得较准确的结果。表4 验证集上的语义标准实验结果

4.3 语句解析结果
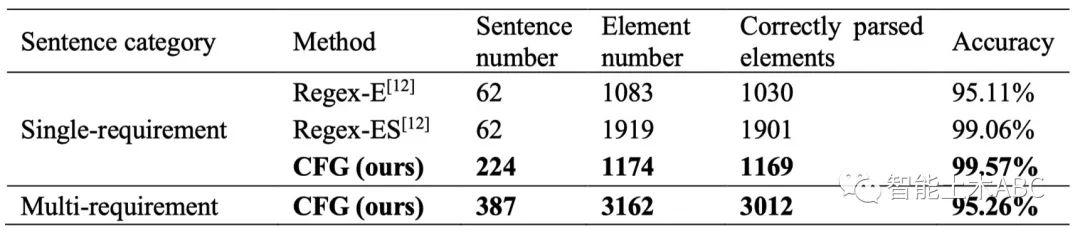
解析的测试基于Python语言实现,并使用了ANTLR4作为CFG规则的解析引擎。在测试中,解析步骤使用数据集中已打好标签的611条语句作为输入,输出相应的RCTree,并根据输出的所有RCTree中处在正确位置的元素的比例计算最终的准确率。表5展示了本方法与现有规则转换方法的解析准确率对比。其中,Regex-E是一种规则转换方法,基于正则表达式的模式匹配,并使用六个基本语义信息标签,Regex-ES是通过使用更多辅助信息标签对Regex-E进行的增强方法,为现有的性能最优的方法。Regex-E和Regex-ES的实验基于62个简单句。值得说明的是,Regex-ES使用了两倍于Regex-E的元素来描述句子中的模式并匹配,这种做法在增加准确率的同时可能会降低可扩展性。
这一结果表明,本文中提出的方法优于最新方法,包括两方面:1)对于简单的单要求句,所提出的方法达到了99.57%的解析准确率,优于当前性能最高的方法Regex-ES;更为重要的是,2)对于复杂的多要求句,当前的方法基于正则表达式而不适用,而所提出的方法可以达到95.26%的解析准确率。
表5 语句解析的元素级准确率对比
4.4 规则生成
为展示本方法的实际应用,本节通过开发规则生成算法,根据解析得到的RCTree 生成可执行规则代码,并使用Revit Model Checker在Revit BIM 模型中实现一个规则检查案例。Revit Model Checker 的可执行规则以 XML 格式指定,称为 Checkset。图12展示了通过规则生成方法将RCTree映射为XML Checkset的一个示例。
本节最终选取了四个示例规范语句,在对其进行自动化解译并生成了RCTree后,进一步应用自动化的规则生成方法得到XML Checkset;并选取一个实际的酒店建筑BIM模型,进行审查。如图13所示。图中,四条审查语句中的1、4两条未通过审查,同时每条未通过的审查下面也列出了导致未通过的元素对象,可以点击选中查看。

图12 规则生成方法示例

图13 规则审查应用示例
5 结论
本研究贡献了一种适用范围广、准确度高的自动规则解译方法,以及 ARC领域的第一个规范文本标注的开放数据集。首先,我们提出了七个语义元素和 RCTree 来表示 BIM 对象和规则检查要求。其次,使用迁移学习技术的深度学习模型进行语义标注。最后,开发了 CFG 和句子标准化规则以将标记的句子解析为 RCTree。结果表明,在语义标注方面,我们的方法适用于长而复杂的语句,并可达到 86.2% 的总体 F1 分数,并且具有进一步改进的巨大潜力。在语句解析中,我们的方法:(1)解析单要求语句的准确率高达 99.6%,(2)解析多要求语句的准确率高达 91.0%,该类句子复杂且常见,但现有方法难以适用。该结果表明我们的方法比现有方法具有更广泛的应用范围。
此外,本方法具有可解释和可理解性,这可用于指导规范文本以更规则的形式编写,或在应用中方便消除错误的解译结果。本研究还为自动规则解译的通用框架提供了一个通用框架,用于从各种规范文件和不同语言创建可计算的规则。该研究发布了第一个规范文本数据集,其中包含比现有研究更多的带有标注的规范语句,可用于ARC领域的未来探索、验证和基准测试。