01 研究背景
我国是世界上水灾频发且影响范围较广泛的国家之一。全国约有35%的耕地、40%的人口和70%的工农业生产经常受到江河洪水的威胁,洪水灾害所造成的财产损失居各种灾害之首。
因此,制定合理防洪调度策略减轻洪涝灾害是我国流域管理的最为紧迫和重要的任务之一。
防洪措施分为工程措施与非工程措施,非工程措施则主要指利用包括建立洪水预报、调度和警报系统。其中,洪水预报与调度一直是颇具挑战性的课题,及时、准确地进行洪水预报并指导流域水库洪水调度,不仅可以有效减少洪水对人类生命和财产造成的损失,还可以在保证上、下游洪水安全的情况下,提高洪水资源利用率。今天将从实时洪水预报的角度切入,讲解数据同化在一维水动力洪峰预报模型中的应用。
02 案例展示
法国的马尔纳河流域属于喀斯特地貌,地形复杂,这大大增加了在模型中准确设置上游流量和横流流量的难度。当地洪水预报中心针对马尔纳流域建立了两个模型,分别为Marne Village model和 Marne Amont Model,见图1。
这两个模型虽然可以达到洪水预测的目的,但是其忽略了支流和地形的影响导致模型结果精度不够。
为了提高预测精度,法国机构CERFACS的工程师将两个模型合成为一个全局模型,并且使用软件OpenPALM与Mascaret耦合,将数据同化的算法应用到一维水动力模型中,以此来对原本忽略的喀斯特地貌和各支流带来的非线性影响进行统一的推演。
注:数据同化(Data Assimilation,下文中以DA表示)是用于减少模型不确定性的方法之一,数据同化能够结合观测数据和数值模拟结果推算出最佳估值,具有预报和降低数值模拟的不确定性这两种优点。
03 模型概述
全局模型中上游流量的边界条件根据五个上游观测站(Marnay, Louvieres, Villiers, La Crete和Humberville)的数据给定,并且设置了五个横流,横流Q1代表Suize河,Q2和Q3代表Rongon流域的Seurre河,Q4代表Mussey河上游支流以及Q5代表Chamouilley河的流量。马尔纳河流域没有对应的水文降雨-径流模型,鉴于该流域河流流量的对海洋降雨事件的齐次响应(homogenous response),全局模型中可以用观测站的监测流量乘以一个系数Ai( i∈[1,5])表示横流流量,达到在模型中包含降雨形成的径流量的目的。

图1:马尔纳流域地形图,其中虚线圈出的为全局模型中包含的两个子模型。黑色三角形代表水利观测站S1, S2, S3和S4。横流(黑色圆点)为Q1, Q2, Q3, Q4和Q5,括号里标注的为横流对应的观测站。
施加在全局模型中的数据同化算法为扩展卡尔曼滤波法(Extended Kalman Filter)。通过这种数据同化算法,结合2001-2010年法国发生的10次洪水事件的数据,可以对横流流量进行精确的时变估计,使模型重现12次洪水事件,从而验证模型的精度。其中,为了防止测量活动中有失误,全局模型中考虑流量观测数据的标准差为5 m3/s。对于每次洪水事件,模型都会进行多次循环推演:在循环k中,前8小时先根据观测数据来预测最佳的Ai值,然后根据预测值Ai计算五个横流流量(Q1, Q2, Q3, Q4和Q5)并进行24小时的洪水预报模拟。
04 模型结果
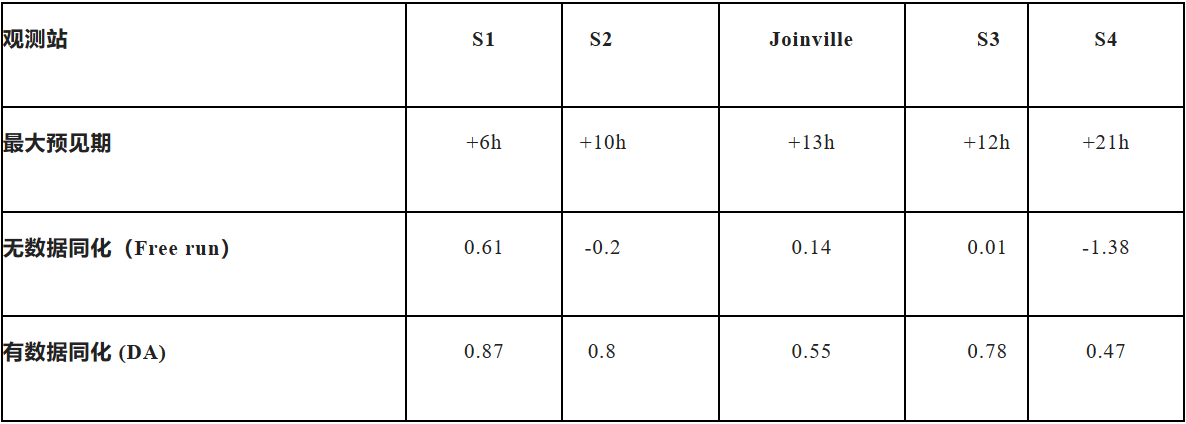
全局模型分别在无数据同化(free run)和有数据同化(DA)两种情况下运行,得出的结果表明了将数据同化应用到洪水预报中的益处。表1总结对比了10次洪水事件中,无数据同化和有数据同化两个模型在每个观测站的最大预见期(预见期越长,当局开展应急处理的时间越充分)内计算得到的平均纳什系数(Nash-Sutcliffe coefficient)。其中纳什系数是衡量模型结果好坏的标准,当纳什系数的值接近1时,表示模型质量好,结果可信度高;值接近0时,表示模拟结果接近观测值的平均值水平,即总体结果可信,但过程模拟误差大;值远远小于0时,则模型是不可信的。经过对比可以得知,使用数据同化后,模型的质量得到了显著提升。
表1:2001-2010 年期间10 次洪水事件每个观测站的最大预见期内无数据同化和有数据同化模型模拟得到的平均纳什系数
无数据同化和有数据同化这两个模型模拟的2010年12月的主要洪水事件(预见期12 h)的结果对比如图2所示,相对较粗的线段表示流量数据,对应左边的纵坐标;较细的线段表示水位数据,对应右边的纵坐标。蓝色点线为Mussey观测站的观测数据,总体来说,采用数据同化后模型的预测值(红色虚线)更接近观测值,模型得到的流量结果与观测值的吻合度比水位结果的更高。模型采用的摩擦系数Ks可能是导致此现象的原因。

图2:2010年12月预见期12h(Mussey观测站)的流量(粗曲线)和水位(细曲线)图:观测数据(蓝色点线),数值模拟无数据同化(free run)(黑色实线),数值模拟有数据同化(DA)(红色虚线)
全局模型中采用的摩擦系数Ks是在校准10次洪水事件的流量数据过程中得到的平均值。Mussey河段对应的摩擦系数为20,漫滩对应的摩擦系数为13。为了解决摩擦系数引起的不确定性,对于数据同化模型结果比观测值更高的部分(见图3,粉色阴影区域),将Mussey河段的摩擦系数改为27,漫滩的摩擦系数改为15;针对数据同化模型结果比观测值更低的部分(见图3,蓝色阴影区域),河段摩擦系数改为16,漫滩摩擦系数改为9。修正摩擦系数后,模型模拟得到的流量数据结果不变,和原模型的结果一致;而修正后的水位数据和观测值吻合度明显提高,峰值相对原模型更接近观测数据。

图3:2010年12月预见期12h(Mussey观测站)的流量(粗曲线)和水位(细曲线)图:观测数据(蓝色点线),数值模拟有数据同化(DA)(红色虚线),数据同化+调整的摩擦系数(绿点)
05 研究结论
综上所示,结果表明数据同化可以有效地减少模型不确定性,并能提高模型预测数据的精度。经过10次洪水事件的推演重现,模型的可靠度得到证明,该模型已经被国家洪水预报中心采用并整合到官方的洪水预报平台中。
06 小结
今天主要讲述将数据同化算法运用到一维水动力模型进行洪水流量和水位预报的案例。防汛工程中,使用洪水预报模型进行洪水演示,预报洪峰流量、出现时间、最高水位及洪水过程,可以为调节泄洪水位、下游洪水预报及防洪调度提供依据。
更多资讯可登录格物CAE官方网站
或关注服务号【远算云学院】
期待您的关注



