神威OpenFOAM——最流行的开源CFD软件与神威·太湖之光的珠联璧合

OpenFOAM(Open-source Field Operation And Manipulation,开源的场运算与操作)是一款基于C++编写的面向对象CFD类库,被广泛用于流体、传热、分子动力学、电磁流体甚至金融等领域问题的模拟,拥有广泛的用户基础。作为一款开源软件,OpenFOAM的诞生可追溯至二十世纪八十年代末期,它支持模版化编程、多面体网格与大规模并行计算,用户可以非常方便地进行二次开发。悠久的历史、活跃的用户社群、完善的文档、强大的性能与可扩展性,让OpenFOAM成为了最受欢迎的开源CFD软件。

OpenFOAM与CFD(素材来源于网络)
神威·太湖之光是世界首台峰值性能超过每秒十亿亿次量级的超级计算机,作为“国之重器”,它为超大规模的科学与工程计算、更高保真度的数值模拟提供了强有力的硬件支撑。swOpenFOAM(基于神威平台的OpenFOAM)正是与此强大硬件配套的CFD软件。它不是简单的代码移植,而是根据神威超算的架构与特性,特别为OpenFOAM量身定制了一整套的优化方案。神威与OpenFOAM二者强强联合,真正实现了1+1>2的效果。
swOpenFOAM优化之道
OpenFOAM求解CFD问题主要包括“预处理-求解-后处理”三个步骤,每个步骤的关键流程与面临的问题如下图所示。为了让swOpenFOAM充分发挥神威的性能优势,需要根据神威处理器的特点——异构众核,详细定制代码移植与优化方案。同时,OpenFOAM求解过程中的三个关键环节:并行剖分、方程离散与方程求解,其对应的负载均衡、数据访存和代数求解算法选择等问题又与处理器架构息息相关。综上所述,这“三位一体”的问题共同构成了swOpenFOAM所面临的最大挑战。
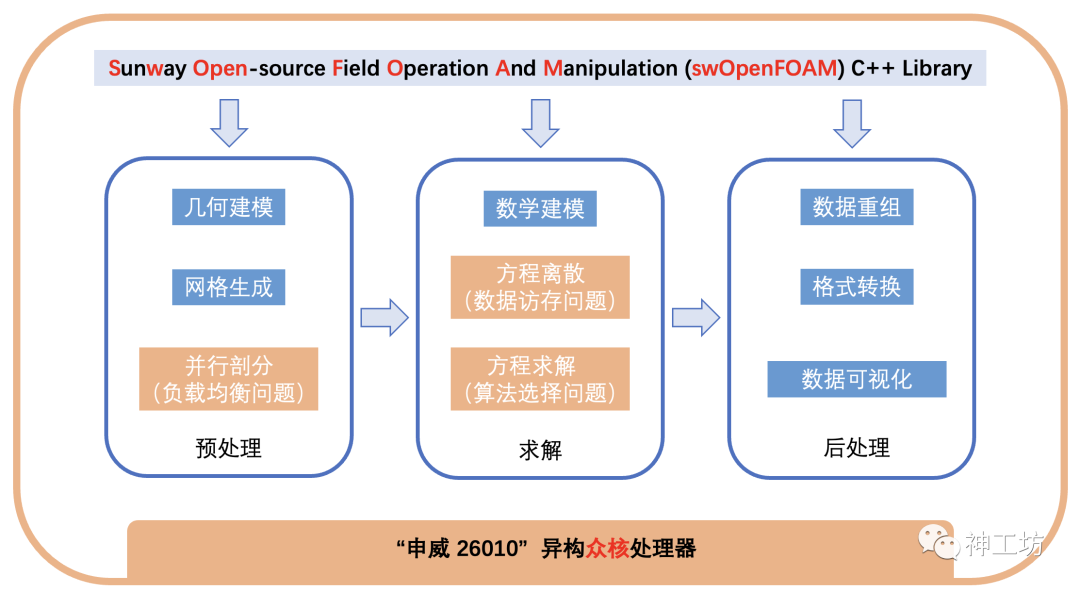
OpenFOAM在神威上的求解流程与关键性能瓶颈
神威·太湖之光使用中国自主研制的“申威 26010”处理器,其特点是片上融合的异构众核架构。每块处理器包含四个“核组”,一个核组中集成了一个主核与64个从核。一个“申威 26010”处理器总共集成了260个运算核心,因此利用好从核是发挥神威性能的关键。

“申威 26010”异构众核处理器架构图
与处理器架构相关的问题是数据访存。高性能处理器内存带宽的增长远滞后于其浮点性能的提升[1](如下图所示),这一性能瓶颈对于“申威 26010”处理器显得更为突出。同时,由于一些图计算或稀疏矩阵特殊的数据结构,致使其迭代运算中存在内存访问不连续的问题。在神威·太湖之光上运行时,造成从核缓存空间的浪费和内存访问次数的增多,从而导致程序性能严重下降。
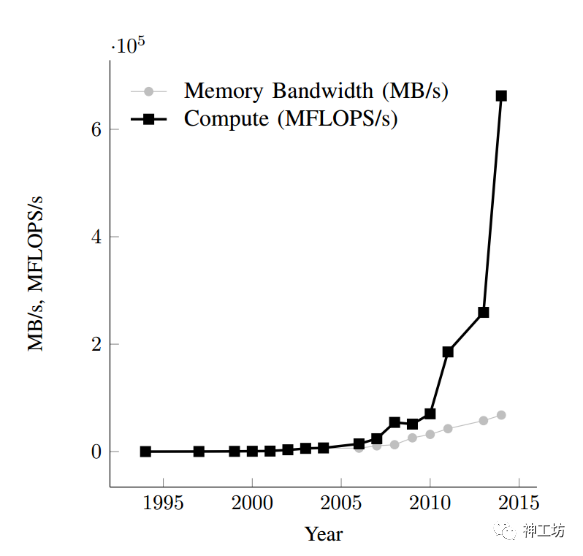
近年芯片浮点性能与内存带宽增长曲线
解决上述问题,首先需要从算法、算子和基础运算符等各个层面开展性能优化工作,其中的关键是根据众核并行的特点定制数据访存策略。其次直接利用神威上的基础加速库进行众核加速将带来巨大的开发量,针对计算模式较为类似的向量计算函数,神工坊团队通过开发统一的从核加速接口(如下图所示)有效地解决了该问题。该统一接口节省了数万行代码的开发量,且极大提升了优化代码的可维护性。最终取得了可观的加速效果,向量操作至少加速6倍,部分向量操作函数达到19倍。

向量操作统一加速接口
与此同时,针对运算中耗费时间长、资源需求大的通量计算和稀疏矩阵计算热点,专门定制众核优化加速方案。这些热点的优化涉及访存不连续的问题,神工坊团队根据“申威 26010”处理器的特点,使用行分段(Row-subsections, RSS)策略,来提升众核并行下的数据访存效率。RSS策略的核心思想是通过对矩阵非零元素建立一层索引来标记,记录若干行连续存储的非零元素对应列上元素具有局部聚集性的索引段起止地址[2]。按照列上的连续索引段起始地址进行访存,可以大大降低离散访存带来的内存带宽浪费。
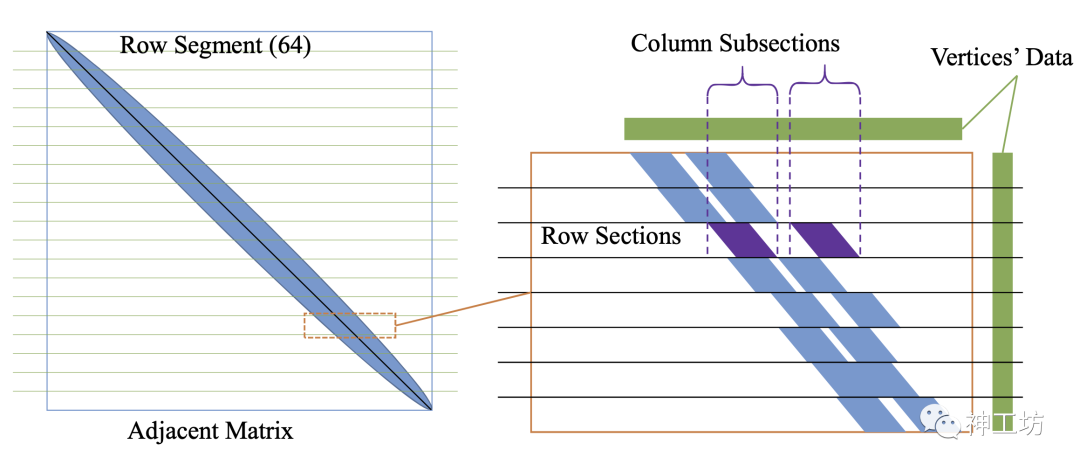
RSS策略中的两级分解

最终加速效果如下图所示,某SIMPLE层流算例使用从核加速,各常用算子与函数操作实现了最低4倍,最高近16倍的性能提升。
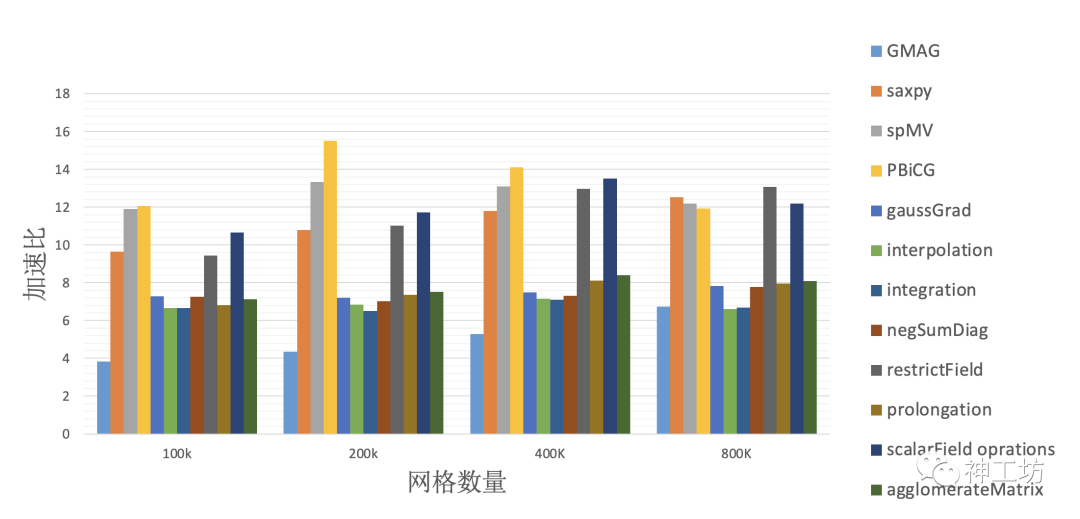
不同网格下计算热点的众核加速比

OpenFOAM使用scotch对计算域进行网格剖分,但是对于同一算例,不同的网格剖分方法对最终性能的影响很大。例如下图为某算例的各进程通信操作占比统计图,红色为等待操作,灰色为接受操作,绿色为发送操作。该算例采用scotch默认参数进行网格分割,可以看到出现了多个进程等待一个进程的情况,性能受到极大影响。虽然表面上各个进程的计算负载是均匀的,但通信负载的不均衡导致部分进程空闲等待大量时间,实际上负载极不均衡。因此需要对网格剖分进行精细参数化控制。
神工坊团队根据算例的特点,对scotch网格剖分参数进行细致调整,实现了较好的通信负载均衡,极大提升程序性能。如下图所示,使上述算例通信等待时间大大缩短至原来的十分之一。

优化scotch参数实现负载均衡
GAMG(Generalised geometric/algebraic multi-grid, 代数几何多重网格求解器)是OpenFOAM中常用的线性方程组求解方法,其关键步骤光顺(Smooth)耗时比例最大。OpenFOAM使用Gauss-Seidel迭代作为光顺过程中的算法(Smoother),如下图所示,这种算法强烈依赖于迭代产生的新值,不易在神威从核上开展并行计算,限制了系统性能的发挥,因此需要改用更易并行的算法。

Gauss-Seidel迭代不易于并行计算
神工坊团队使用Chebyshev迭代法代替了GAMG中原有的Gauss-Seidel迭代。与原Smoother 相比,Chebyshev迭代法的特点是无空间依赖,没有全局同步点,易并行且收敛速度快[3]。如下图所示,通过使用Chebyshev迭代,某算例的求解时间缩短了70%。

Chebyshev伪代码及其与Gauss-Seidel的性能对比
swOpenFOAM应用案例
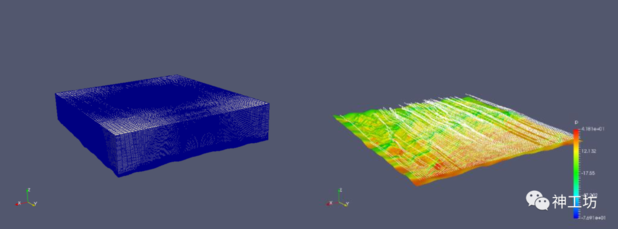
计算域网格与流场分布示意图
如上图所示为某风资源预测应用,对大小为30 km × 30 km × 7.5 km区域内的风场进行模拟。该算例在神威·太湖之光上使用256个核组,5000万非结构网格进行,具体算法与求解器参数如下表所示。
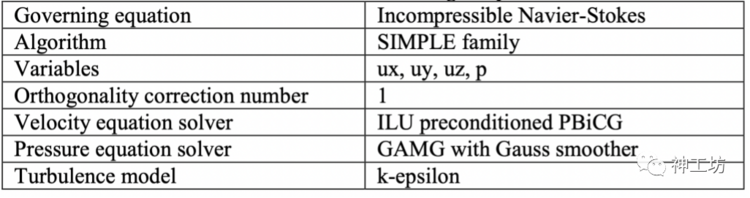
算例相关参数
该算例的性能优化过程中的效果统计如下图所示。通过一系列的加速措施,包含手动缓存、网格剖分优化,代数求解器优化,最终使算例的综合运行效率提升了4.1倍,同时神威上每核组的运行速率也达到了同期主流Intel x86处理器的1.18倍。
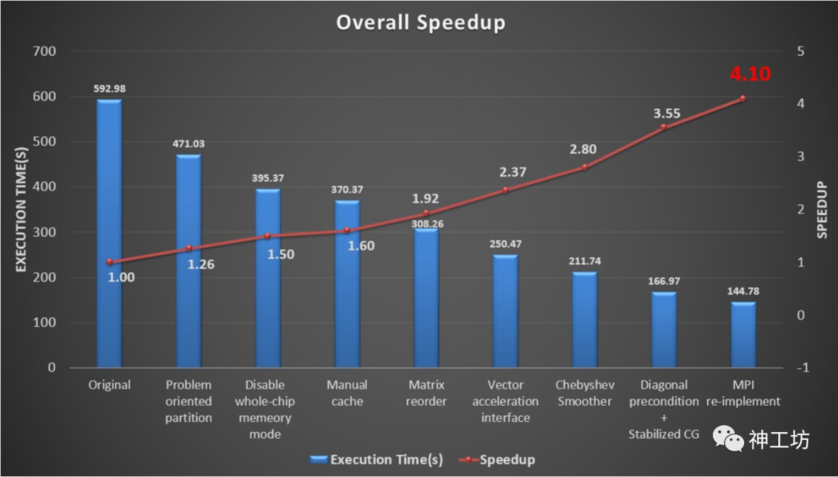
应用一系列加速方法后的算例运行时间与加速比
swOpenFOAM是神威·太湖之光上CFD模拟的重要组件,在此基础上部署的某风电场仿真平台,已完成包括中国、法国、土耳其的全球部分地区中尺度数据模拟,并产品化地为风资源工程师完成了超过2000个风资源项目的设计和评估。swOpenFOAM让最受欢迎的开源CFD软件在神威·太湖之光上焕发新的活力,成为高性能仿真计算的重要助力。

基于swOpenFOAM的某智慧风场平台
[1] Vincent, P., Witherden, F., Vermeire, B., Park, J. S., & Iyer, A. (2016). Towards Green Aviation with Python at Petascale. SC16: International Conference for High Performance Computing, Networking, Storage and Analysis. doi:10.1109/sc.2016.1
[2] Liu, H., Ren, H., Gu, H., Gao, F. and Yang, G. (2020), "UNAT: UNstructured Acceleration Toolkit on SW26010 many-core processor", Engineering Computations, Vol. 37 No. 9, pp. 3187-3208. https://doi.org/10.1108/EC-09-2019-0401.
[3] Martin H. Gutknecht, Stefan Röllin, The Chebyshev iteration revisited, Parallel Computing, Volume 28, Issue 2, 2002, Pages 263-283, ISSN 0167-8191, https://doi.org/10.1016/S0167-8191(01)00139-9.
撰搞 | 许可


