基于非结构网格的仿真——太湖之光上的巨大挑战



结构化网格(上)与非结构化网格(下)
由于数据结构的原因,非结构网格相比于结构化网格,其算法计算访存比更低,同时访存更加离散。另一方面,随着超级计算机架构演变,相较浮点性能的大幅提升,内存带宽日益成为瓶颈,让非结构网格仿真计算更加受限。架构演变也催生了多样的编程模型和加速库。在太湖之光等先进超级计算机上,对非结构网格算法进行优化加速,往往十分复杂且开发量巨大。这四方面的问题,让非结构网格仿真计算在太湖之光上的性能,成为一个巨大的挑战。
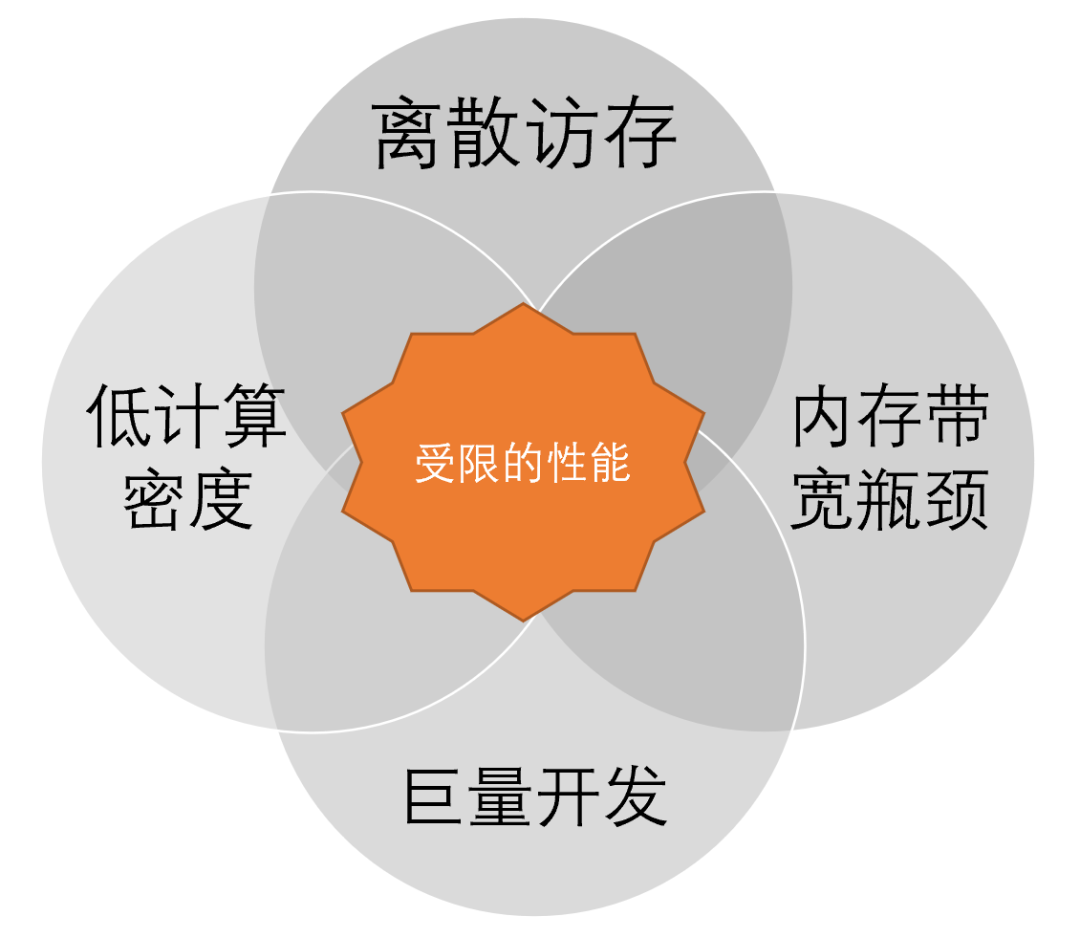
太湖之光上非结构网格“四大问题”
离散访存:非结构网格不同于结构化网格,其相关数据在内存中无法以规则的方式存储,导致访问具有分散和不连续的特性。换句话说,在仿真计算中,我们需要进行大量的临近插值积分,但是非结构网格单元的邻居却无法像结构网格一样连续规则地在内存中找到。离散访存的结果,就是让连续获取数据中有大量无效数据,或者只能跳跃地获取数据片段,从而损失有效的内存带宽。
低计算密度:非结构网格拓扑复杂,同时仿真对数值稳定性要求较高。因此,在非结构网格上进行仿真计算,一般采用紧致的数值格式,其阶数相对较低。简单来理解,就是在进行插值积分时,用尽量少的网格单元邻居,邻居的邻居以及更远的临近关系基本不考虑。这样一来,在网格单元数据上执行的计算操作就少了。因此,非结构网格上的算法往往具有较低的计算访存比。以四面体网格有限体积离散的稀疏矩阵向量乘为例,其访存与计算之比仅为1/12浮点操作/字节。
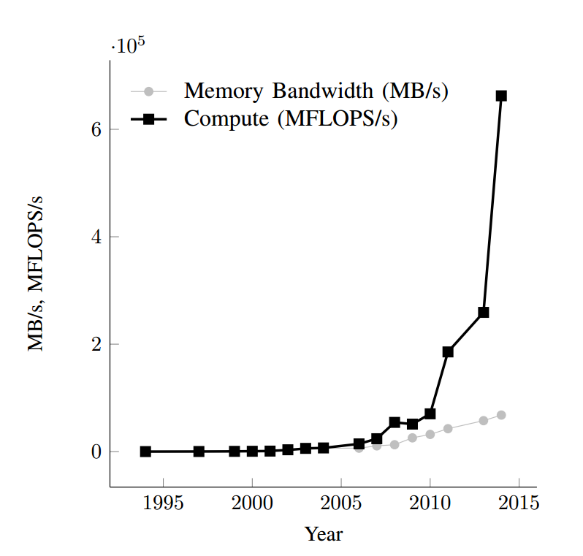
近年芯片浮点性能和内存带宽增长曲线[1]
内存带宽瓶颈:限于单个核心性能提升的瓶颈,高性能计算机处理器架构由多核全面转向异构众核。例如,“神威·太湖之光”超级计算机就是采用纯国产异构众核芯片研制的千万核心计算系统。但是近年来,高性能处理器的浮点性能保持近似对数增长的同时,内存带宽却呈现出极为缓慢的增长态势。以太湖之光sw26010芯片为例,目前的浮点性能-内存带宽比,已高达20浮点操作/字节。这意味着1/12浮点操作/字节计算密度的稀疏矩阵向量乘,在sw26010芯片内存带宽满载时,仅能发挥出0.4%的理论浮点性能。
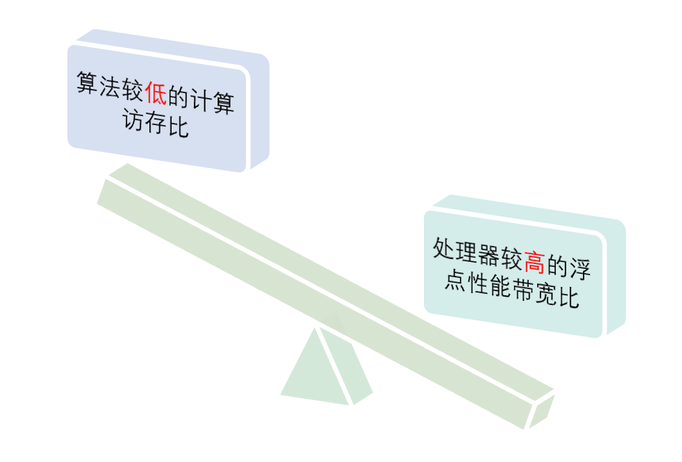
算法与硬件间失衡的性能天平
巨量开发:太湖之光绝大部分性能来自异构众核芯片sw26010上的8x8从核阵列,因此利用好从核是发挥太湖之光性能的核心。然而,以数十行代码的稀疏矩阵向量乘为例,直接利用在太湖之光上的基础加速库进行众核加速开发,如欲达到较为理想的性能,一般需要上千行代码和大量调试。对于复杂的工业仿真软件来说,这样的开发量是无法接受的。以开源CFD软件OpenFOAM为例,其代码量高达数百万行,热点核心遍布。如果全面采用手动加速开发,工作量无疑等同于再开发一个OpenFOAM。
UNAT全称为“UNstructured Acceleration Toolkit”,是在太湖之光超级计算机进行非结构网格仿真计算加速开发的工具套件。UNAT具有友好接口,方便开发者快速在太湖之光上进行加速开发。UNAT底层实现了自动的数据结构优化,自动的并行遍历算法,用户只需关心具体操作实现,并免于大量调试。这些都大大缓解了,太湖之光上非结构网格计算加速的巨量开发问题和离散访存问题。UNAT更是通过一套耦合算子机制,将热点进行分解融合,采用循环时空二维分解,跨循环数据复用等策略,有效缓解了非结构网格计算密度低的问题和硬件上的内存带宽瓶颈。其中原理较为复杂,具体可以参考文末论文[2](见文章底部“阅读原文”)。

UNAT原理图
下面通过几个典型应用,看一下UNAT的应用效果。
稀疏矩阵向量乘:用COO格式稀疏矩阵向量乘进行测试。随着矩阵元素维度变化,UNAT最高加速比和单核组Flops分别达到近27 倍和3.5 GFlops(0.46%理论性能)。与手工优化的代码相比,UNAT API实现了其大约70%的性能。考虑到兼容性和通用性带来的额外开销,其效果是相当可观的。

COO稀疏矩阵向量乘加速比及浮点性能
某CFD求解器加速:一个开发者仅用1周时间,采用UNAT对其中主要6个热点核心进行了加速开发。热点核心众核加速比平均在19倍左右,整体加速也达到了10倍。
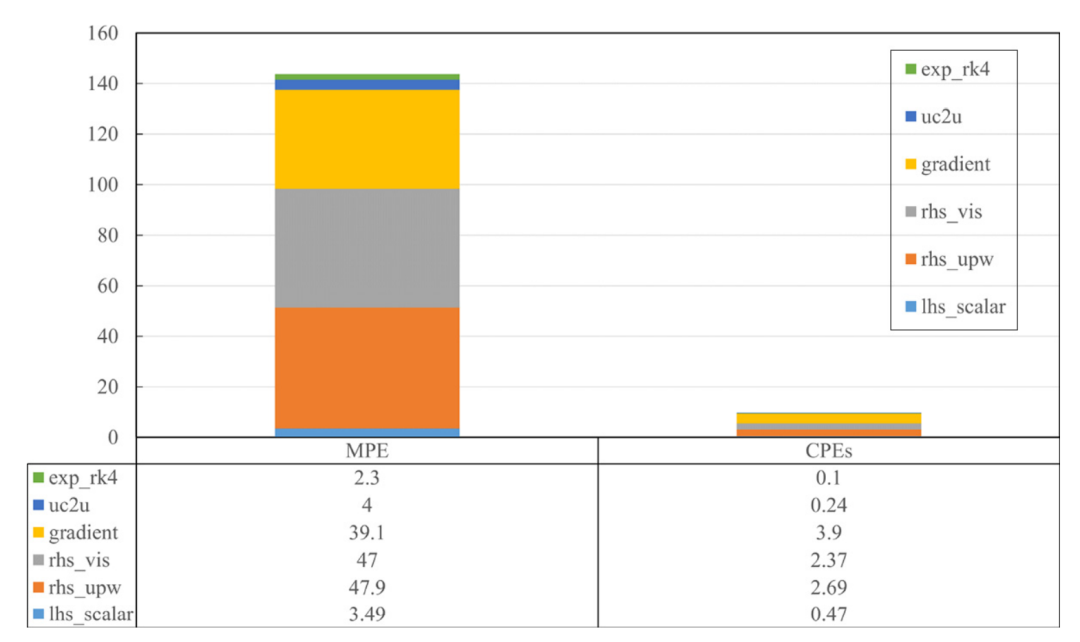
某CFD求解器优化加速
OpenFOAM风资源评估应用:利用UNAT加速工具,我们对OpenFOAM某风资源评估应用大部分热点进行了加速,众核加速比在8-15倍之间。由于UNAT卓越贡献,最终该应用在太湖之光上取得了整体4倍加速。


OpenFOAM风资源评估应用优化加速
燃烧仿真应用:利用UNAT加速工具,单个开发者 2周内完成了15万行某燃烧仿真程序优化,使得该程序最终在太湖之光上取得了整体5.4倍加速。由于性能提升,该软件可使用10亿级网格,在合理的时间内,进行航空发动机全环燃烧室高保真数值模拟。




燃烧仿真应用优化加速
(本文作者:任虎)
参考文献:
[1] Vincent, P., Witherden, F., Vermeire, B., Park, J. S., & Iyer, A. (2016). Towards Green Aviation with Python at Petascale. SC16: International Conference for High Performance Computing, Networking, Storage and Analysis. doi:10.1109/sc.2016.1
[2] Liu, H. , et al. "UNAT: UNstructured Acceleration Toolkit on SW26010 many-core processor." Engineering Computations: Int J for Computer-Aided Engineering (2020).



