SimCube对FMI联合仿真标准的实现

本文摘要(由AI生成):
本文探讨了FMI标准在联合仿真中的应用及意义。文章指出,尽管在某些情况下使用简单通信协议可能更便捷,但FMI标准对于广泛集成和高效仿真具有显著优势。随着越来越多的商业软件支持FMI标准,其已成为行业内的广泛认可的标准。文章还介绍了SimCube软件对FMI标准的实现,包括支持不同版本、位数和操作系统的FMU,以及支持混合使用和分布式计算等能力。这些功能使得SimCube能够应对复杂多变的现实情况,提高联合仿真的效率和准确性。
发展简史
在2010年的时候,我们承担了一个大项目的一部分,将搭建一个仿真平台集成多家高校自研的计算程序进行某个基于时间的动态过程仿真计算。
彼时,FMI标准刚刚发布了1.0版本。我们的项目在2014年交付时,FMI发布了2.0版本,估计在今年FMI将发布3.0版本。
在当时的项目里我们没有采用FMI标准,该项目成果后来转化为SimCube软件产品,在2015年1月正式发布1.0版本,也在同年的4月份SimCube1.2版本中,我们实现了FMI1.0,2.0两个版本中的联合仿真(Co-Simulation)标准,在16,17两年里我们又进一步完善了对该标准的支持。
纯真年代
回到刚才提到的仿真平台项目,基本需求如下图所示(使用SimCube建模的流程图):集成四个不同学科的计算模块,前三个是使用C语言开发的,第四个是使用Matlab开发的,包裹四个计算模块的大模块是总控中心,它将根据业务逻辑调度底下四个子模块的运行。
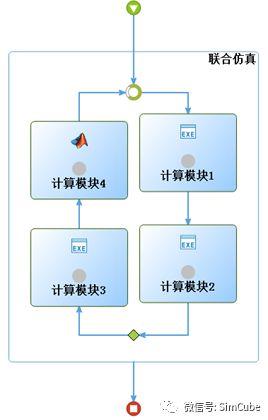
大概简述下当时的业务逻辑:从t=0开始,计算模块1将以一个时间步被调度起来持续迭代运行,当上层的联合仿真探测其某个输出满足某个条件时,将调度计算模块1与2一起计算,它们之间通过上层的联合仿真有数据通信,两个计算模块的时间步长不一致,因此上层的联合仿真在调度某个计算模块运行时需要判断两者的时间是否同步,如果一个计算模块时间上落后了,那么还需调度其再计算一次,赶上另外一个计算模块,保证有合理的物理意义。同样地,当探测到计算模块2的某个输出满足某个条件时,将调度四个计算模块一同计算。四个计算模块的时间步长都可不一样,上层的联合仿真模块确保它们几乎在同一个时间上齐头并进,步长大的会等待步长小的,每次调度都传递相应计算模块的需要的外部数据,这样四个计算模块的执行序列事先是无法预知的,最后当某个条件满足后,仿真流程计算完毕。实际过程比上面描述的复杂更多。
四个计算模块的外部特性:前三个计算模块完成一个时间步的计算非常快,不到1秒,问题在Matlab编写的第四个模块,巨慢无比,假如在每次调度它计算时重启一次,当时大概估算了整个仿真流程的计算时间将达到44小时,这是无法接受的。在对FMI标准一无所知的纯真年代里,当时制定了一个仿真平台与计算程序的通信协议,要求在整个联合仿真计算过程中,四个计算模块都不能退出来,只启动一次,美其名曰“常驻内存”,通信协议非常简单,基于标准输入输出流,发送简单的命令文本控制计算程序的计算。这种方法不仅带来计算速度的提升,大概20分钟可完成一次正常计算,而且开发量也大减,不需要每个计算模块保存/恢复计算状态了。
标准时代
联合仿真必须要用FMI标准吗?答案显然是否定的,上面项目可以佐证。如果当初我们采用FMI标准实现,那么必须在计算程序和仿真平台两端都实现该标准,将远比自定义的简单通信协议困难,也对开发者的技能门槛提高不少。但是,如果集成的计算程序不是从头开发或者自研可修改源代码的,那么标准就很有意义了。
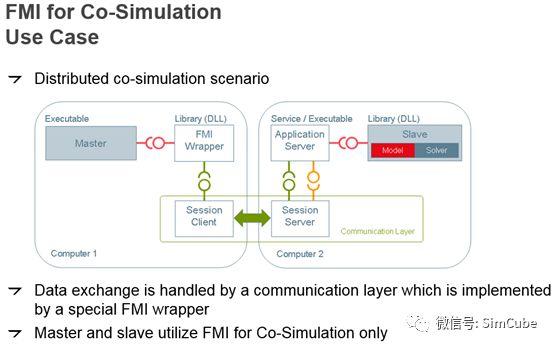
各个商业软件都在争相实现FMI标准接口,2015年在这里 https://fmi-standard.org/tools/ 看到大概有60多个软件支持,而现在有100多个了。FMI标准包含两部分:模型交换(Model Exchange)和联合仿真(Co-Simulation)。这里只讨论联合仿真,FMI标准是按主(Master)从(Slave)架构的,对标前面的项目案例,仿真平台是Master,计算模块是Slave。先看联合仿真的三个使用场景(下面两个图片来自于ModelLisar提供的一个介绍FMI的文档:The Functional Mockup Interface for Tool independent Exchange ofSimulation Models):
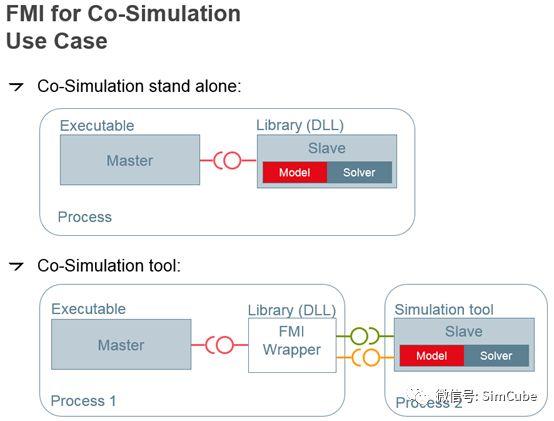
第一个应用场景主、从都在一个程序中,如果纯粹这么设计,我觉得没有意义,毕竟遵守一个标准有很多约束的,如果不需对外提供接口,只是在一个程序中完成联合仿真的计算,还是天马行空来得快些。
第二个应用场景主、从分开,部署在同一台机器。
第三个应用场景主、从可以分布部署在一个网络上。
SimCube软件支持第二、三个应用场景的Master实现,另外特别说明:FMI标准对Master的调度算法实现没有任何要求。
个人觉得,FMI标准有两大意义:
第一个意义是FMI已经成为了一个广泛使用的标准,大家都可以实现该标准,当你需要的时候拿过去就能用。
第二个意义是,各大商业软件都是自己实现FMI接口的,因此,“常驻内存”的运行模式对开发商来说很容易办到,避免了外部人员集成软件时在大量的时间步迭代中花费大量重启恢复状态的时间,这个意义非常重大。
我们刚刚完成的这个项目,有一个仿真流程集成了两个软件,一个实现了FMI标准,一个没有实现。在我们的联合仿真模块中对这两个分别集成,当初调试流程时,对系统从0-1.9秒的时间段进行仿真,整个过程大概要计算24小时,而其中大部分时间都花费在没有实现FMI标准的软件上,因为软件的频繁重启,模型状态恢复太花时间了。
当前实现
现在来谈谈SimCube当前对FMI标准的实现,前面提到了,SimCube支持FMI1.0,2.0两个版本,实现了Master的角色,也就是调度各个计算模块进行计算的功能,同时也支持上面提到的第2,3两种应用场景。应用场景虽然看上去很简单,但真正对接现实需求还是有一定难度的。下图在一个联合仿真流程中集成了四个计算模块:
有两个支持FMI标准,两个不支持,也就是说SimCube支持混搭;
两个FMU计算模块可以是支持FMI1.0,2.0任意标准,也可以是32或64位任意程序,也就是说SimCube支持混配;
还可以部署到网络上,不同的操作系统下运行,也就是说SimCube支持分布式计算。
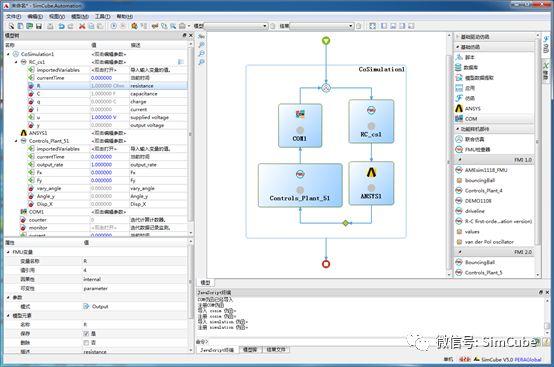
整一个列表描述SimCube在支持FMI标准的能力。
SimCube可跨操作系统运行,也即支持被集成的FMU可运行在多个系统上
支持FMI1.0,2.0两个标准,并支持在同一个流程中驱动两个不同版本的FMU
支持联合仿真中含有非FMU的计算模块
支持被集成的多个FMU分别是32或64位程序
支持分布式的FMU计算
提供脚本定制复杂的调度FMU运行逻辑
现实情况千变万化,商业软件的实现是既定的,它们可能分别支持不同FMI版本,又或者不同的位数,甚至运行在不同的操作系统上,而上面提供的能力应该能应付绝大多数情况了。



