跟midas了解CFD | 六

流体CFD数值分析是否可信?
对于CFD,很多人认为它是一种玄学,如何给出一个合理并严谨的答案,是每个研究此领域工程师比较头疼的事情。
误差来源分为舍入误差、迭代误差、离散误差、模型误差和系统误差,只有不断提高对误差的敏感性,总结成功案例,多学习CFD理论,才能得到合理并严谨的结果。
在CFD数值计算算法上分有限元(FEM) 、有限体积(FVM)、有限差分(FDM)三种常见的方法。三种方法各有优缺点,三种方法中有限元和有限体积对计算域(几何区域)复杂度适应性好,成为工程软件首选。
有限元法 vs. 有限体积法:哪个最好? 可能是萝卜咸菜,一直没有一个肯定的答复。
原理上的差异,可参考:https://cn.comsol.com/blogs/fem-vs-fvm/
“有限体积法对应于分段常数有限元基函数,可能对通量采用高阶插值方案,这需要采用一阶或二阶精度方法。有限体积法的局部表述可以实现局部守恒,这是该方法极具吸引力的一个特征。这意味着每个cell的净通量都保证是平衡的,进而能够以自然、直接的方法来稳定对流占主导的流动问题的离散化。通过修改cell间边界上的通量可以自然地实现所谓的逆风稳定和其他稳定。逆风在对流通量方向的离散化中产生非对称性。
有限元法的好处是能够为不同阶数的基函数制定方法。高阶基函数给出了高阶、精确的方法,这有助于提高给定网格的精度。有限体积法采用零阶基函数,但可以对通量使用高阶插值方案,这也提高了精度。当使用高阶方法时,得到的系统变得更大,相同网格的求解时间增加,不过,精度也更高。因此,我们在比较性能时,必须在给定的精度条件下进行比较。用不同的方法以相同的精度测量解决流体流动问题所需的 CPU 时间和内存是比较不同方法性能的正确方式,而不是比较cell或element的数量。”
midas 自1989年致力于CAE的研发,专注于FEM理论研究。不断的在精度、易用度、速度三个维度研发适合工程师更高效、便捷的工具。midas NFX CFD 中文版,易学、易用、亲民。结构-热-流体多物理场耦合。支持:流体流动、流体传热、共轭传热、多相流、离散相、组分传输、网格变形(MRF、嵌套网络)、单向/双向FSI(流固耦合)

程序的人性化,友好性,尤其FSI的一键式处理,深受用户的喜爱。
语言栏可随时切换 一键生成FSI模型
一键生成FSI模型

除易用度外,NFX CFD也在速度和精度上做了很大的优化和提升。
 提供湍流模型:k-ε , k-ω, k-ω(SST) , LES , SpalartAllaras等14种湍流模型以及高级湍流
提供湍流模型:k-ε , k-ω, k-ω(SST) , LES , SpalartAllaras等14种湍流模型以及高级湍流
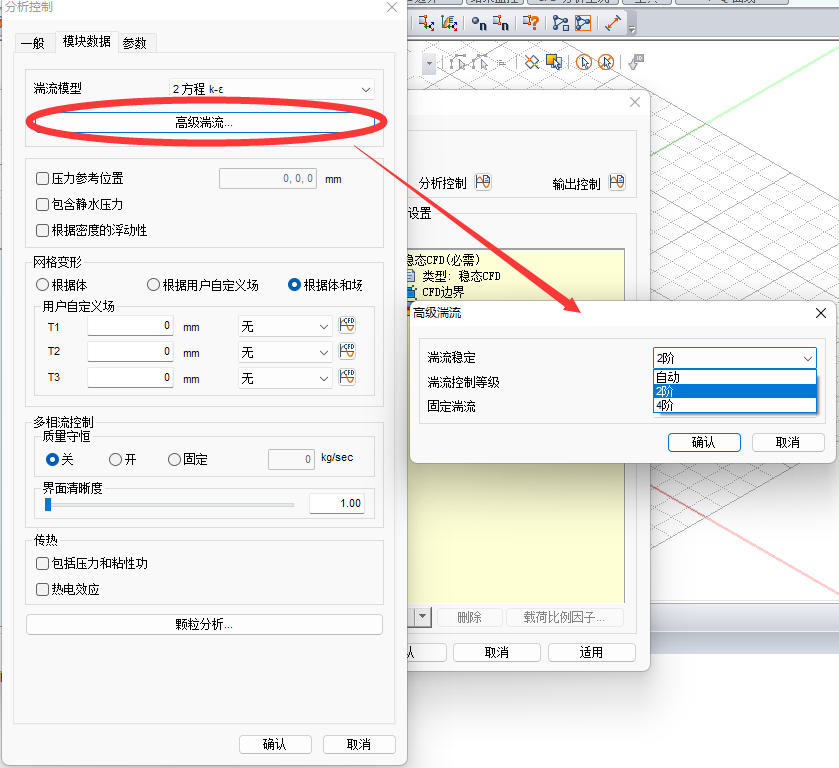

参数说明:




压力二阶预处理 (2-level Preconditioning for Pressure)
You will use the deflated solver. Deflated solver is a type of multigrid solver that accelerates convergence using a multigrid algorithm. Applicable only for pressure equations. Long and complex piping problems can sometimes be difficult to solve with a basic preconditioner. In this case, a two-level pressure preconditioner can be used to quickly converge. In addition, it is recommended to apply it to most problems because it can reduce the calculation time even in the case of general analysis.


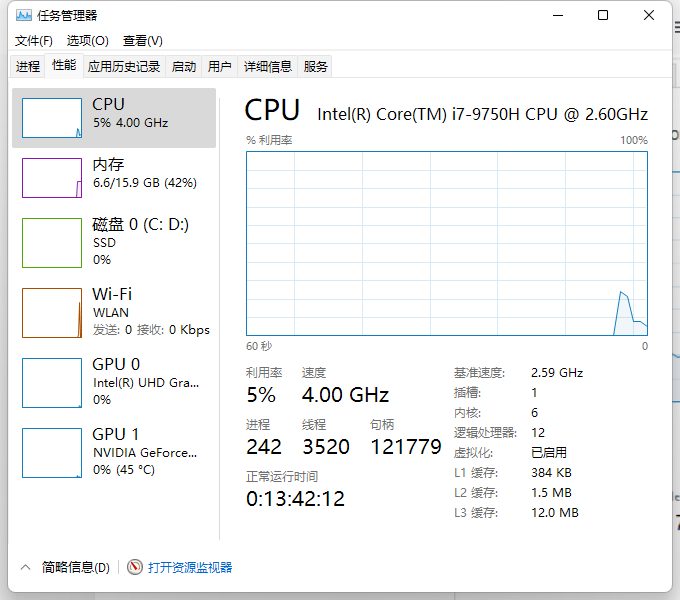
The number of processors determines the number of CPU cores used for calculation. To check the number of cores in your computer, right-click on the task bar at the bottom of the window and click "Start Task Manager". After that, if you select the Performance tab, you can check the number of cores in CPU usage status. Most recent PCs are quad (4) cores. It's a quad core, but sometimes it's displayed as eight. This is when Hyper threading is turned on and can be turned off in CMOS.
Hyper-Threading is a function that allows you to use virtually two physical CPUs. This feature is advantageous for multitasking. For computers mainly used for analysis, it is important to focus on calculations and speed up the speed rather than multi-tasking. Therefore, it is recommended to turn off Hyper-Threading for computing computers.


In order to take advantage of these GPU features, GPU calculation has also been applied to midas NFX CFD. In midas NFX CFD, GPU computation was applied to the iterative solver and preconditioner to accelerate the system of equations. For efficient GPU computation, the preconditioner uses the GPU Algebraic Multigrid (AMG) preconditioner.
If you want to calculate using GPU, you can select ‘Enable GPU Acceleration’. However, when using a commonly used graphics card, the calculation may be rather slow. When calculating using a GPU, you must use a Tesla-class or higher graphics card that supports double-precision. The following table provides recommendations for compute GPUs.

If you use a GPU with an appropriate specification, you can see an acceleration effect of 2-3 times the normal calculation speed. In terms of iterative solver computation, it accelerates up to several tens of times, but the overall speed is about 2-3 times because the matrix assemble uses CPU.
In the case of GPU, since it is a device that performs parallel operation while many cores work together, there may be a slight difference from the CPU result. This is a normal and normal phenomenon related to significant figures of the computer, and can be ignored if the difference is within the error range. However, if there is a significant difference beyond the margin of error, it is considered that there is an error in the GPU operation, so the related model needs to be tested. In particular, there is a possibility of an error if the ECC feature is removed from a GPU or Tesla that does not have the ECC feature. The ECC function is an additional option for improving computational accuracy and stabilizing the GPU. If you use this function, the GPU memory is reduced by 700Mbyte, but it is recommended to use it for numerical analysis because of stability and accuracy.
跟midas了解CFD | 五
跟midas了解CFD | 四
跟midas了解CFD | 三
跟midas了解CFD|二


