PiFlow--GPU高性能计算来啦

PiFlow的GPU高性能计算终于集成到界面啦,小π同学迫不及待想要见识一下效果,于是以WPFS弹翼模型为例,规划了测试。
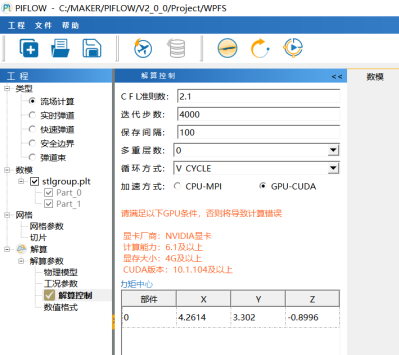
设置界面

WPFS弹翼模型
软件GPU及加速所需的硬件环境:
* 只支持NVIDIA显卡;
* CUDA版本10.1及以上;
* 显存4G。
现在让我们一起去看看结果吧。
测试一:WPFS-62万网格-GPU单层效率求比单核单层提高了20倍。

测试二:WPFS-100万网格-GPU单层效率求比单核单层提高了30倍。
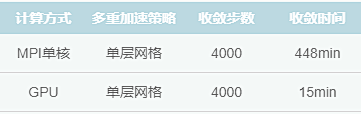
测试三:WPFS-60万网格&WPFS-100万网格GPU多重加速效率
WPFS-60万网格
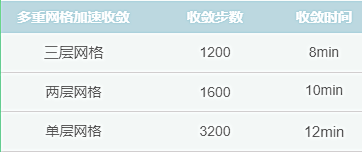
WPFS-100万网格
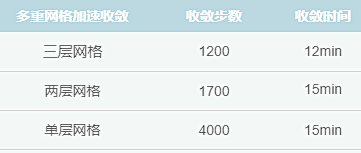
测试四:WPFS-60万网格&WPFS-100万网格GPU精度
WPFS-60万网格

WPFS-100万网格

测试结论:GPU加速效果显著,100万网格提升30倍效率,精度也满足验收标准。
哇,从这个统计表格可以看出计算速度是相当的不错,小π真的感觉像做了火箭一样,大大提高了测试效率,相信也可以帮助工程人员快速进行方案迭代。
高兴的同时,也有忧愁的地方,GPU对计算机的要求比较高,小π的计算机性能相对较好,性能差一点的计算机的计算能力也会下降,甚至有些计算机GPU无法进行计算,希望PiFlow的开发人员继续努力改善这些问题。如果有对软件感兴趣的小伙伴,请联系我们呦。
登录后免费查看全文
著作权归作者所有,欢迎分享,未经许可,不得转载
首次发布时间:2022-10-16
最近编辑:2年前

CFD 国产自主可控软件

相关推荐
最新文章
热门文章
