brick快速构建大的颗粒模型

1 引言
一个模型达到平衡所需的时间随着模型的增大而增加,这是因为不平衡必须在整个模型中反复传递,直至满足定义的平衡准则。当创建一个非常大的颗粒模型时,例如建立一个100万个颗粒的模型,其初始化需要非常长的时间来达到平衡状态,即使施加了阻尼,也需要反复通过calm(model calm)来加速模型达到平衡,这通常是一个非常耗时的过程。为了解决这个问题,PFC提出了一种快速构建大型模型的方法,即象堆砌砖墙一样,通过组装小的brick模型来构成大的模型。
2 brick构建原理
brick是一个压实的、粘合的小型组件,通过组合相同的brick构建一个大型模型。brick是在周期性空间(periodic space)内压实的颗粒集 合体,以紧凑的形式存储起来。然后使用这个brick进行组合,由于brick一边颗粒的几何排列是另一边的映像,因此多个brick可以无缝地连接在一起,如下图所示。

由于brick已经被压实并处于平衡状态,因此可以瞬间组装成一个大型模型,不再需要建立全局平衡,接触力储存在brick内,而且这些接触力在两个brick的交界处会自动平衡。
3 brick命令及其FISH函数
brick命令的关键字共有5个,按照使用brick的逻辑顺序,make和export用于产生和导出brick; import和assemble用于导入和组装brick,而delete关键字可以在brick产生之后的任何阶段对其删除。
brick assemblebrick deletebrick exportbrick importbrick make
brick的FISH函数共有11个,其中brick.extent,brick.lower.corner和brick.upper.corner是PFC 7.00版本新增加的函数,6.00版本没有这三个函数。
brick.assemblebrick.deletebrick.extentbrick.findbrick.idbrick.listbrick.lower.cornerbrick.maxidbrick.numbrick.typeidbrick.upper.corner
4 使用brick
为了产生brick, 必须使用周期性(periodic)边界【设置模型域 model domain;FLAC3D和3DEC导入DFN模型的域范围(model domain extent)设置】,其它步骤没有特别之处,达到平衡后使用brick命令导出文件。默认的文件名在3D中为brick.p3brk,在2D中为brick.p2brk。感觉这个文件名在随后的编程中用不上,因为它不像在DFN中既可以使用文件名也可以使用ID来获取fracture的指针,在brick中,只能通过ID获取brick的指针([brick_pnt = brick.find(1)])。
brick make id 1brick export id 1 skip-errors
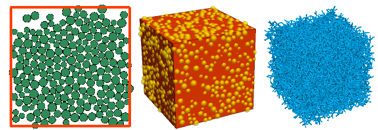
相同的代码在2D中产生出207个ball,在3D中产生出4623个ball,可见2D和3D在随后计算的运行效率上相差非常大。3D产生出18482个ball-ball接触,但在2D中没有产生接触【No objects fit the plot criteria: Contact(0)】,这是由于在ball的产生过程中,porosity 和resolution这两个关键字的取值过大,这样产生出来的brick会留有非常大的孔隙。
把导出的brick在水平方向各组装两个,然后垂直组装4个,因此如下图所示的块体模型是由16个brick组成。在3D中,共有73968个ball,可以通过4623*16=73968来得到验证;共产生了283630个接触,如果使用18482*16=295712来验证,发现少了12082个接触。这是因为brick之间的接触是共用的,理论上可以通过统计每个共用面上的接触来计算出实际产生的接触。另一方面,可以明显看出这个模型的孔隙率还很大,需要减小porosity 和resolution的值使得模型颗粒更加致密。
brick import id 1brick assemble id 1 origin -4.0 -4.0 -8.0 size 2 2 4

下图所示模型的产生过程:首先创建brick和wall, 然后按照wall的尺寸组装6个brick,最后把wall边界外的ball删除,形成最后的模型。



