用 Mathematica 破解密码


本文译自Wolfram博客:https://blog.wolfram.com/2011/01/26/breaking-secret-codes-with-mathematica/
Mathematica可以让您感觉自己像个计算超人。带着这种态度和一些小学生的密码学知识,我本周将注意力转向了密码破解,结果却发现了埋藏的氪石。
密码的弱点(您用相同的不同字母交换消息中出现的每个特定字母)是它们不会改变字母的模式。利用这一事实的最简单的攻击是频率分析。英语中最常见的字母是“e”,因此编码消息中最常见的字符(假设消息是用英文写的)将对应于“e”。依此类推。
当伊丽莎白女王的间谍大师使用频率分析破解玛丽的密码时,苏格兰的玛丽女王失去了她的头。我想,如果 16 世纪的间谍可以手工完成,我应该能够在大约 10 分钟内在Mathematica中将其自动化。
让我们开始吧。首先,我想生成随机测试密码。

在这篇文章中,我将研究最简单的情况,将自己限制在大小写相同(即“e”和“E”)并映射到相同符号的密码中,标点符号和空格不编码。对于更大的字符集,该方法将是相同的。这是 4 X 10 26 种密码之一:

使用此密码对消息进行编码非常直接,我不会费心创建函数:

如果您知道编码密钥,则逆向过程是微不足道的。(这是密码的另一个弱点,您需要安全的密钥交换)。

好的,两分钟后,密码就实现了。现在让我们编写频率攻击代码。首先,我们需要将文本中的字母按频率顺序排序。
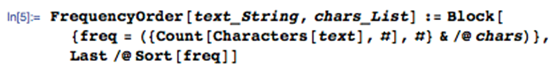
现在我们需要破解密码,就是将按频率排序的消息中的字符与一些校准文本中的字母配对,也按频率排序。通过不对频率顺序进行硬编码,只要您提供正确语言的校准文本,此代码将适用于其他语言。如果您有来自原作者的示例文本,它还会考虑写作风格。

就是如此——密码破解频率分析只用几行代码就实现了!让我们测试一下。我将对《傲慢与偏见》的前 10,000 个字符(小写)进行编码。

对于校准文本,我将使用本书的最后 341,000 个字符(大约一半)。

这是我们猜测的密钥:

这是解码的消息:

氪石!超人跪了!为什么这不起作用?
经过一些调试焦虑和一些实验后,我终于明白了,我学生时代的理论——破解密码多么容易——并不像人们说的那么容易。我对学校数学老师的钦佩之情再次受到打击!问题是一些字母之间的频率差异小于 1%,但这些字符在 10,000 个字符样本上的频率的标准偏差可能高达 0.5% 左右,这使得一个字母很可能出现在频率顺序中的错误位置。让我们在“s”和“r”处寻找示例。我们可以从文本中的连续样本中得出概率分布。

如果我们看一下“s”和“r”,与它们的标准偏差相比,它们的频率非常接近。

使用这些分布,我们看到更常见的字母“s”实际上只会在 54% 的时间内排名出现在“r”之前。换句话说,频率分析有 46% 的时间是错误的。

当您累积所有排序错误的可能性时,频率分析实际上完全解码您的消息的可能性变得非常小。随着示例文本长度的增加,情况几乎没有改善。即使我使用了整本书的前半部分,结果也令人费解。那有多大用处?
但是氪石从来没有完全阻止过超人。当我仔细查看解码后的文本时,我意识到有些字母实际上是正确的。
我们信息的第一个词应该是“chapter”,频率分析已经正确地找到了“……ter”。也许频率分析的效果比看起来的要好。我怎样才能取得进一步的进展?想到了两种方法:
1)使用进一步的频率分析——字母对的频率(“th”、“sh”、“ed”在英语中会很高),包括双字母(“oo”、“ee”、“tt”等);单词首字母和单词尾字母的频率;按单词长度划分的频率(例如,一个字母的单词主要是“I”和“a”);等等。有很多方法可以对数据进行切片。
2)我们的字母顺序可能有误,但可能很接近;我们可以尝试扰乱顺序——稍微上下移动字母,看看是否能改善结果。
但最终两个方法我都没有使用。对于这两种方法,我都需要一种方法来解决相互矛盾的建议。一个明显的答案是查看结果中有多少有效的英语单词。如果两种方法对字母映射的内容给出两种不同的建议,我们将采用一种可以提高消息中有效单词数量的方法。
这是一个提取字典中没有的所有单词的函数。(请注意,从这一点开始,我没有对标点符号进行编码很重要。在现实世界中,我需要确定子字符串是否有效,而不仅仅是整个单词,并且需要不同的标点符号方法。)

此时,面对比我计划的要多得多的工作,我想到我们可以采用更简单的方法对文本进行拼写检查,并对建议的更正使用此改进测试。好的,比拼写检查稍微复杂一点,但这是基本概念。
对于每个无效词,我们得到相同长度的字典词列表……

...并在EditDistance 中找到最近的。如果有几个同样接近,那么我们会忽略它们,因为我们更有可能在已经是猜测的过程中给自己提供虚假信息。
选择最接近的已知单词后,我们对齐字符并删除匹配的字符,以便我们进行更正。然后我们将这些变成替换规则。

下一步是采用我们通过这种方式发现的所有建议的更正规则,并根据它们的常见程度对它们进行排序。尝试应用相互矛盾的规则是没有意义的,所以我删除了所有与流行建议映射到或来自相同字符的不太常见的规则。

其中一些建议的替代品是正确的,并且会改善情况;有些是虚假的,让事情变得更糟。我的直觉是受欢迎的建议会比不受欢迎的建议好,所以我下一步是取最流行的n条建议,应用它们,并计算无效词的数量。然后我们选择最小化剩余无效词的n。

这不是我打算创建的简单代码,而且我已经超过了我的 10 分钟目标,但令人高兴的是,这种密码通常能很好地处理1万个字符的文本,尽管它可能取决于它试图破解的密码。

凭借超能力支持的一点独创性,我们的计算超人击败了他的敌人!


