公开课精华 | 移动机器人视觉三维感知的现在与将来

本文总结于香港科技大学王凯旋博士关于移动机器人视觉三维感知的现在与将来的公开课,其中主要介绍了基于视觉的三维环境感知方案,包括传统方法和基于深度学习的方法。
1.深度感知的研究动机
感知周围的环境是移动机器人的基本要求。而所谓的“环境”有很多层的含义,比如从相机获取的色彩信息,但是这并不能直接告诉我们环境的几何信息,例如前方是否有障碍物,路面是否平坦,也不能直接得到相关的语义信息,比如环境中有什么物体,属于什么类别等等。而在本次分享中,我们会主要关注如何从相机中获取物体的几何信息。

图1 环境能提供的三种信息
几何信息能给机器人的安全移动提供保证。机器人在移动的过程中需要避开障碍物,需要与物体交互。同时,我们也需要一些基本的场景重建,从而为人类的高级决策提供信息支持。
探究几何信息有很多的传感器供我们选择,如双目相机,RGBD相机。不同的传感器有各自的特点和缺点:双目相机两目之间需要保证一定的基线长度,因此就需要占用更多的空间资源;RGBD相机在户外或光照强的场景,其主动发出的信号通常会受到明显的干扰,深度估计会因此失效;激光雷达受限于成本,质量以及尺寸,很难在消费级产品中使用。
目前使用在无人机中的三维感知主流方案是双目相机,因为它的成本低,并且其被动接受光信号的原理可以确保室内和室外的稳定使用。针对一些无人机小型化的需求,我们也会希望双目相机的尺寸更小,但是对应基线长度的缩短也会提高算法实现的难度。
Vins-mono这一突破性的方案使我们可以使用单目相机和imu就可以实现较精准的定位。因此,单目相机在定位问题上已经能满足我们的一定需求,那单目相机是否可以进一步完成飞机的三维重建任务呢?

图2 Vins的出现改变了最小传感器的需求
回答是可以,但目前还限于静态场景。从直觉的角度思考单目进行三维重建的可能性,我们在玩一些赛车游戏的时候,通过来自一个视角的观察,就可以实现对环境的感知和对车的操控,说明单目的三维感知是可以实现的,而从理性的角度分析这个问题,单目相机和双目相机没有本质的区别,对于单目相机,在机器人移动中,相机在不同时刻也是处于不同位置。因此,如果我们能找到特征点在不同时序图片上的位置,我们就可以通过三角化的方法估计相机位置,但是不同时刻像素或者特征的数据关联,有时候也是个很难的问题。
总之,不管是单目还是双目相机,相对于激光雷达和RGBD相机而言,信息密度非常高,并且有成本低的优势,算法的实现效果上限很高,因此视觉深度感知以及很多的潜力值得我们去挖掘。
2.深度感知的一般流程
关于深度感知的一般流程,首先我们获得的是一系列的图像序列,vins算法根据这些图像推算机器人的空间位置,而深度估计模块则会推断每一个像素相对于相机的距离,也就是所谓的深度图,它会和输入图像有相同的尺寸,每一个像素包含距离信息,接着,深度图会被转化为全局的三维地图,而三维地图有很多的表达方式,比如八叉树,tsdf等方式。接着,三维模型可被用来执行路径规划等下游任务。
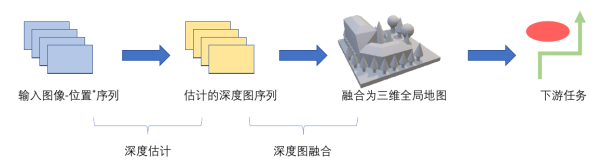
图3 深度感知一般流程
针对深度图估计,首先,我们需要找到对应点,然后三角化估计深度。但是对应点的寻找在没有纹理或者有大量重复纹理的场景都会给特征匹配带来很大的困难。造成这个问题的原因是算法往往对于场景只关注局部的特征,缺乏整体的感知,而不像人类一样从全局特征出发。
为了解决这个问题,在2011的论文 Dense Tracking and Mapping in Real-Time中,作者提出了从图像序列中估计出深度的方法。它的核心就是利用代价体积cost volume这一概念建立损失函数,同时考虑每个像素自身的匹配误差以及全局的平滑性,优化整体的代价函数进而得到深度图。
那么该如何去构建代价体积呢?首先为了保证实时性,我们需要从一系列拍摄的图片中进行筛选,而筛选得到的位置如果距离太远或者太近都不是理想的观测。此外,连续的图像往往观测的是同一场景,必然存在大量信息的冗余。如何利用这些信息进行降噪,去除异常点等也是一个值得思考的问题。
这里的介绍一个方法是利用深度滤波(depth filter)。它的引入就是就是为了解决刚刚提到的两个问题,如何去选择参考帧以及如何去融合深度图。关于深度滤波,他首先需要实现“跟踪”,也就是建立起不同帧图像像素的关联,记录下同一特征点在各帧的相对位置,并且生成Age-map来记录同一点被观测的时间,进而建立代价体积,和之前帧的信息相融合。通过时序融合,我们可以实现对于物体深度更稳定准确的估计,并且可以实现对于噪声和异常点的去除。
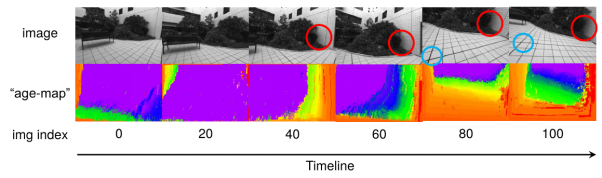
图4 深度滤波的实现效果
第二个要介绍的工作是关于深度图提取算法的优化。我们注意到深度图中很多场景,比如白墙,高分辨率的图像并不能带来更精确的深度信息,那么该如何合理的分配算力,分别给值得优化的像素以及没有优化必要的像素呢?这里用到的是一种四叉树的数据结构,这种树状结构将会在前后景交接以及纹理分布的细节区域展开更多的分支,提取出每个像素适合优化的分支节点进一步优化深度。

图5 图像的不同部分有不一样的深度分辨率需求
关于传统方法,有些问题是无法回避的,比如有很多需要手动调试的参数,又比如很多工作是基于场景平滑性(smoothness-term)的假设,但是在前后景交接处,或者一些深度突然变化的场景,平滑性是否是一个很好的假设,是值得商榷的。尤其是对一些边缘的处理,我们希望保持它们的状态,而不是过度的平滑。而且,它的解空间非常大,针对每个像素分别进行处理会造成估算的计算量非常大。
3.基于学习的深度感知
面对传统方法的不足,我们自然会考虑用深度神经网络去解决问题。
神经网络是基于数据驱动的方法,相比于传统方案,它更好地引入了语义信息,在传统方案中,平滑项的调整只能根据梯度和大量调参,而在深度学习的方案中,我们就可以让网络自己去判断平滑项的大小。此外,通过了解可利用的算力大小,我们可以此为依据设计网络进行优化,达到精度与效率的平衡。
在基于深度学习的方案中,MVDepthNet是一个类似U-Net的网络,通过一系列卷积层将代价体积最后转换为深度图。而在训练时,我们也可以通过RGBD得到的深度值来训练网络。此外MVDepthNet通过显式的引入代价体积可以更有效的利用多视角的观测。
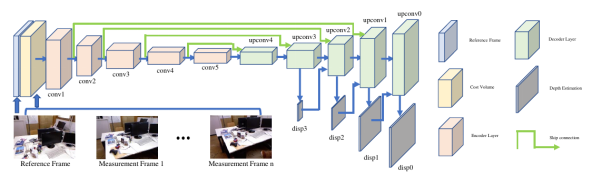
图6 MVDepthNet网络架构
另一个要介绍的深度学习方案叫Geometric-pretraining。它的工作出发点是考虑到深度网络的训练过程中,我们总是需要RGBD数据。而此前的相关工作在进行深度估计时,通常基于的假设是场景中的物体都是静止的,但是这在驾驶场景中很明显是不成立的。
所以在Geometric-pretraining这个工作中,所基于的假设就是场景中可能存在动态物体。在网络中,通过运动编码器(motion encoder),我们以连续帧的图片作为输入,得到一个包含运动信息的向量。此外,通过单帧的图像作为输入,我们还可以利用结构编码(structure encoder)得到图像中的结构信息,通过结合结构信息和运动信息,我们就可以得到场景中的光流信息。我们把训练好的结构编码器在monodepth任务上进行微调,就可以得到一个泛化性更好的网络。
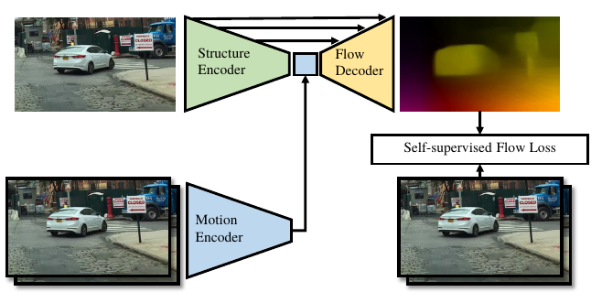
图7 Geometric-pretraining模型
4.深度图的融合策略
接下来我们来讨论一下深度图该如何融合。
在机器人领域,我们希望深度图的融合占用较小的计算量,并能实现实时的效果。为了展现融合效果,TSDF方案通过把三维空间划分成很多小格子存储表面信息,这在相对简单的场景是没有问题的。但是在较复杂的场景,当发生回环等情况时,TSDF生成的三维图就会出现鬼影等错误。
为了解决这种问题,保证在回环的同时会对地图更新主要有基于体素和基于点云的两类方法,采用体素的方法一般分为chunk-based和BundleFusion两种方式,但是第一种方法需要人工依靠经验的调参,而第二种方法则不能保证高效性。
而基于点云的方案会把场景表达成一个个无序的点,比较著名的方案有ElasticFusion。在我们的工作Surfel fusion中,我们把点云与vins系统的位姿图直接关联,当位姿图发生回环检测时,3D图也会相应变化调整。

图8 Surfel Fusion的建图效果
5.未来的发展机遇
最后我们来聊一下未来的发展机遇。
第一个趋势是关于单目相机的深度估计(monodepth),传统的基于多视角几何的估计方案通常依赖系统的内外参等标定信息,并且通过基于场景中都是静态物体的假设进行估计,但这在很多场景下是无法满足的。
此外,以往我们希望图像的分辨率越高越好,但是高分辨率带来的增益却并不是线性增加的。而目前研究的主要进展包括通过与多视角几何的结合,改善网络结构的设计,以及寻求对于特殊格式数据的应用。
不过,个人认为最重要的还是对于动态物体的处理,因为动态物体是很多三维场景都存在并且相当重要的一部分。尽管目前来看还缺乏有效的理论指导,但是一些论文已经展示了一些有效的成果。
第二个趋势就是隐式二维表达,不像传统的用像素数量的信息表达深度图,我们希望把数据进一步压缩(128维的向量)来表达场景中的独立特征,这样可以有效降低自有变量的数目。
但是,这种思路的难点在于如何确保在隐式编码(Latent Code)中的表达能力,目前的表达通常是线性的形式,线性的表达能力是相对较低的,如何转化为非线性的表达是一个值得思考的问题。此外,如何保证映射的泛化能力也是我们需要关心的。
希望这次的讲座内容对各位的研究和工作有所帮助和启发


