LS-DYNA求解效率深度测评 │ 六种规模,本地VS云端5种不同硬件配置

以下文章来源于速石科技 ,作者灵魂工作室
如何提高求解器的计算效率?
本地和云上仿真并行计算是一回事吗?
什么类型的云端资源更适合跑LS-DYNA?
LS-DYNA大规模并行计算效率优化明显吗?
在云上运行会改变用户本地的使用习惯吗?
用户需求
实证目标
1、LS-DYNA任务能否在云端有效运行?计算效率能否优化?
2、LS-DYNA应用最适合的云端资源是哪种类型?
3、LS-DYNA大规模并行场景是否依然能保持线性?
4、fastone能否进行资源统一管理,同时保持用户本地的使用习惯?
实证参数
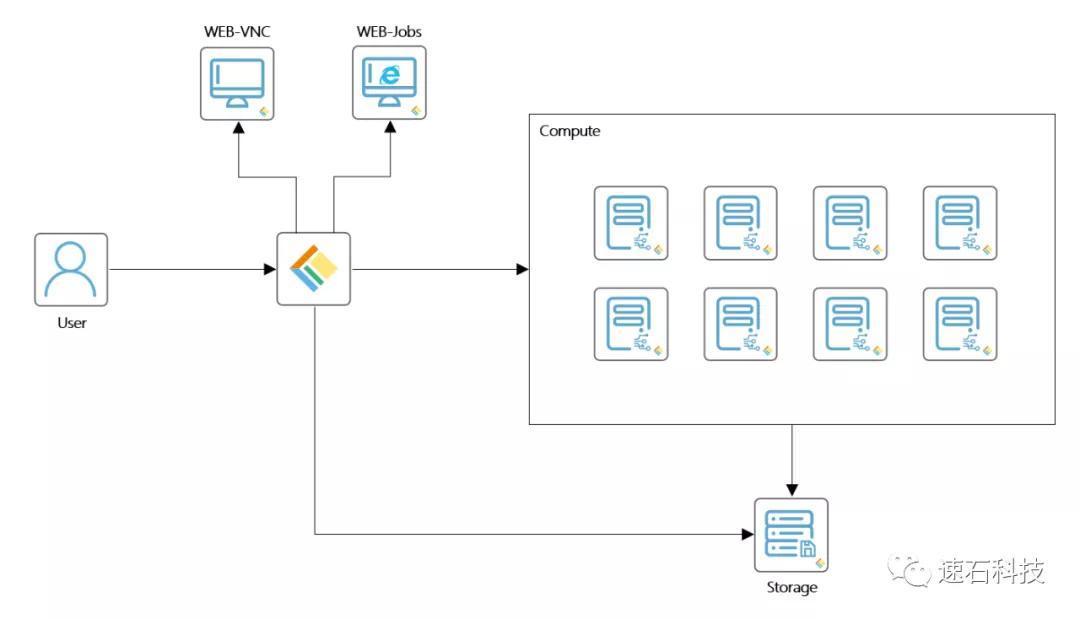

实证场景一:不同类型配置
本地 VS 云端计算优化型实例 VS 云端通用型实例 VS 云端内存优化型实例
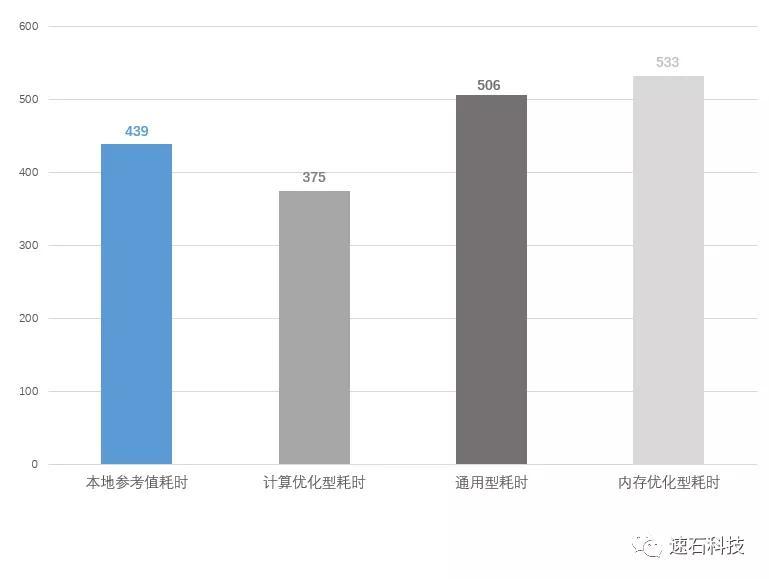
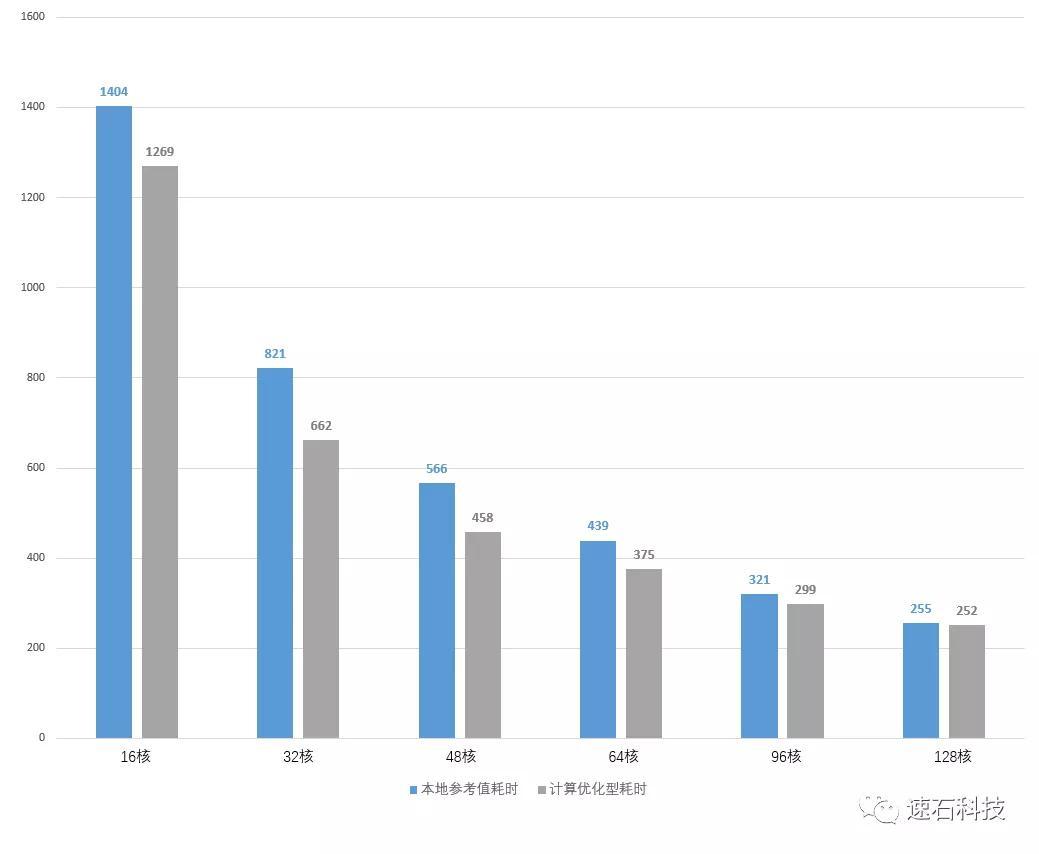
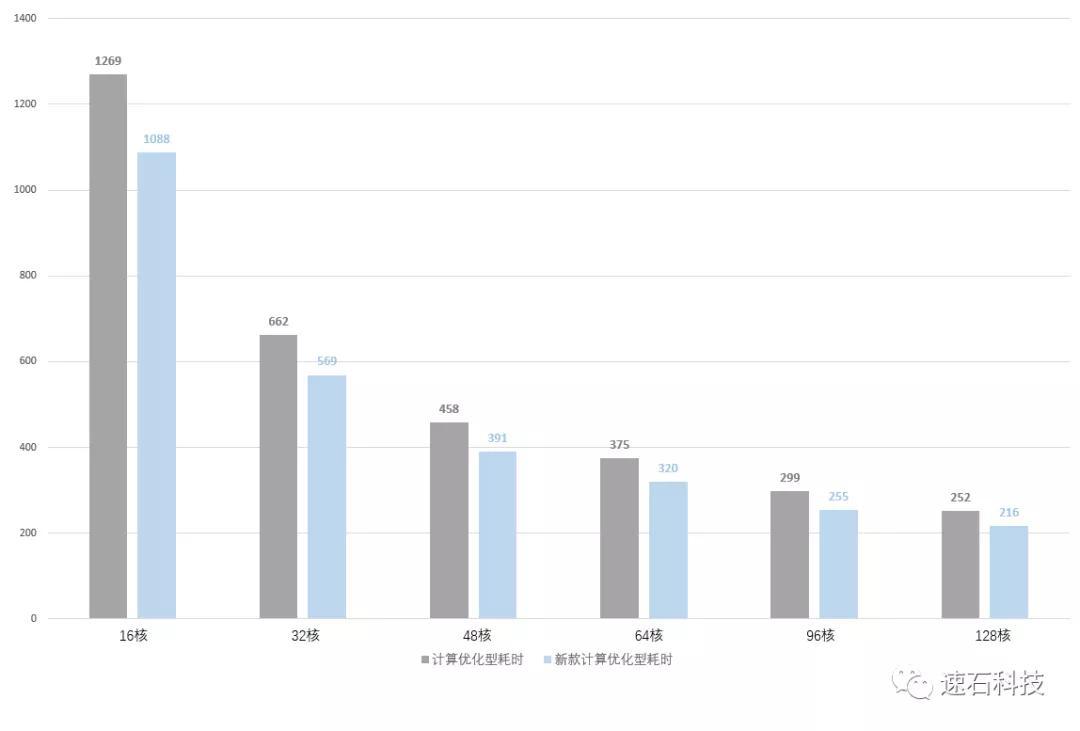
实证场景二:不同代际,同样类型配置
本地 VS 云端计算优化型实例 VS 新一代云端计算优化型实例

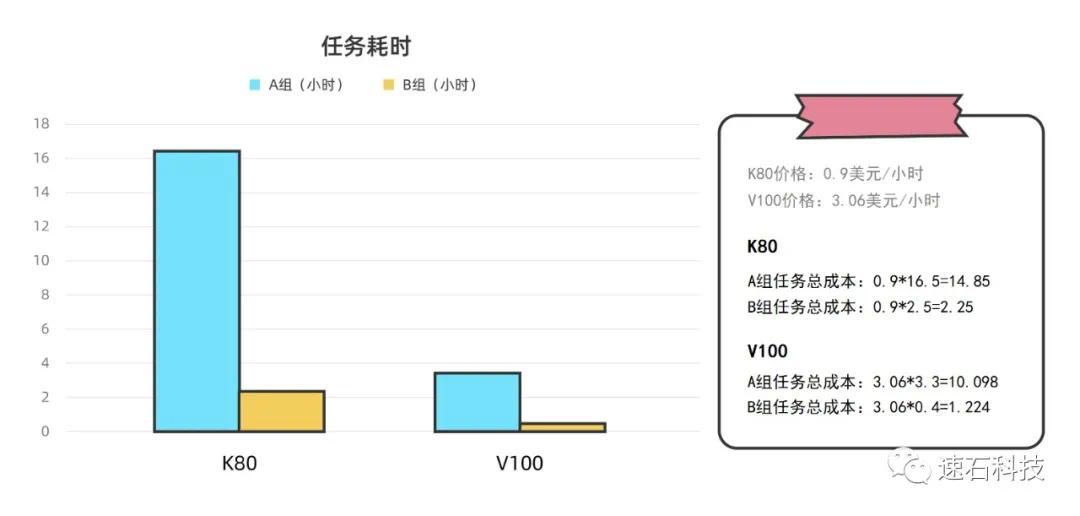
实证场景三:不同规模云端扩展性验证
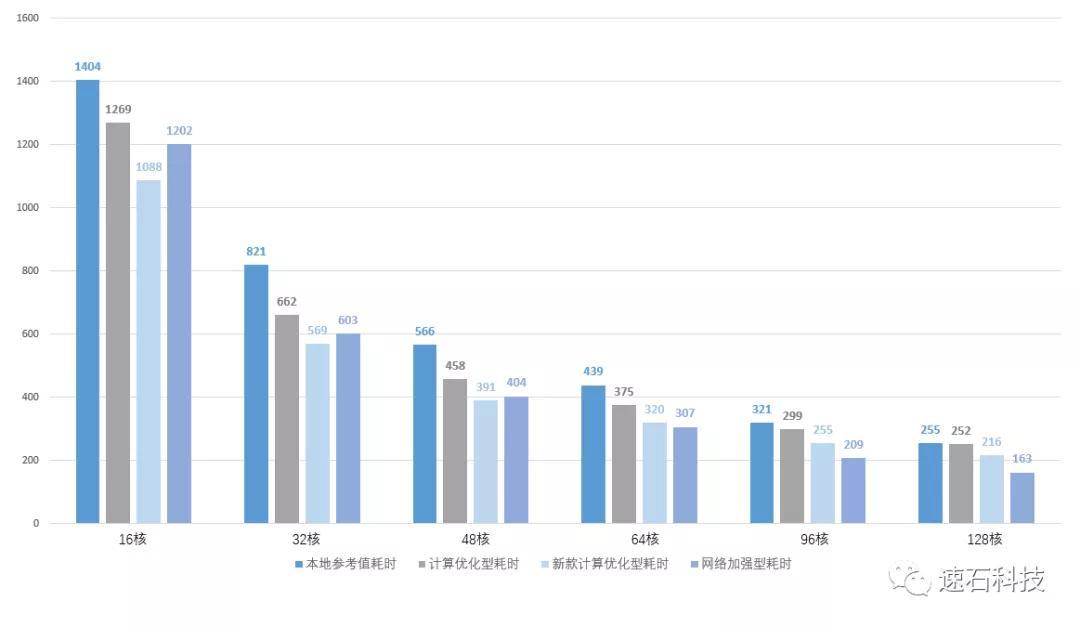
本地 VS 云端计算优化型实例 VS 云端网络加强型实例
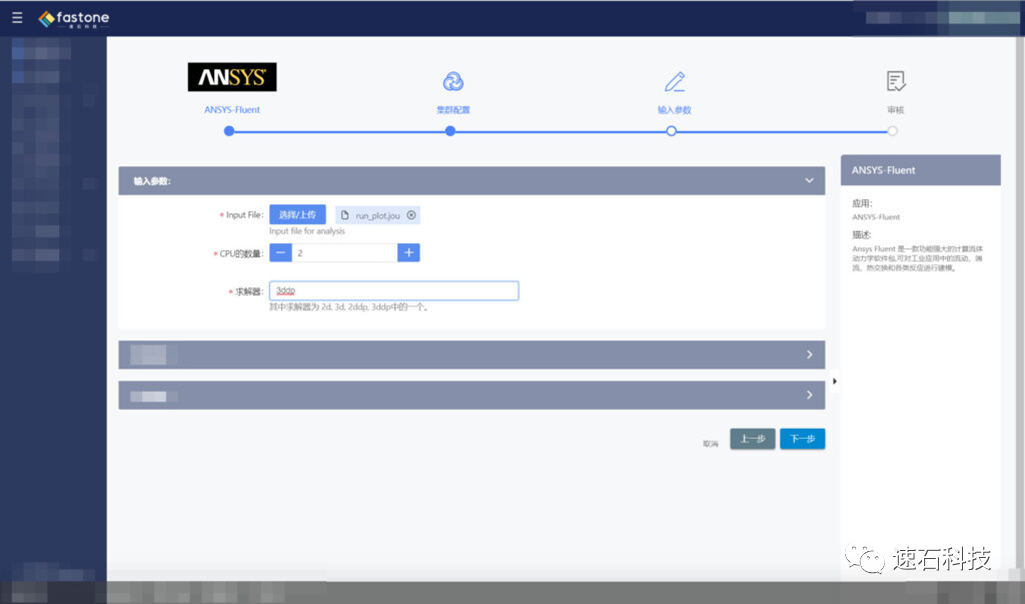
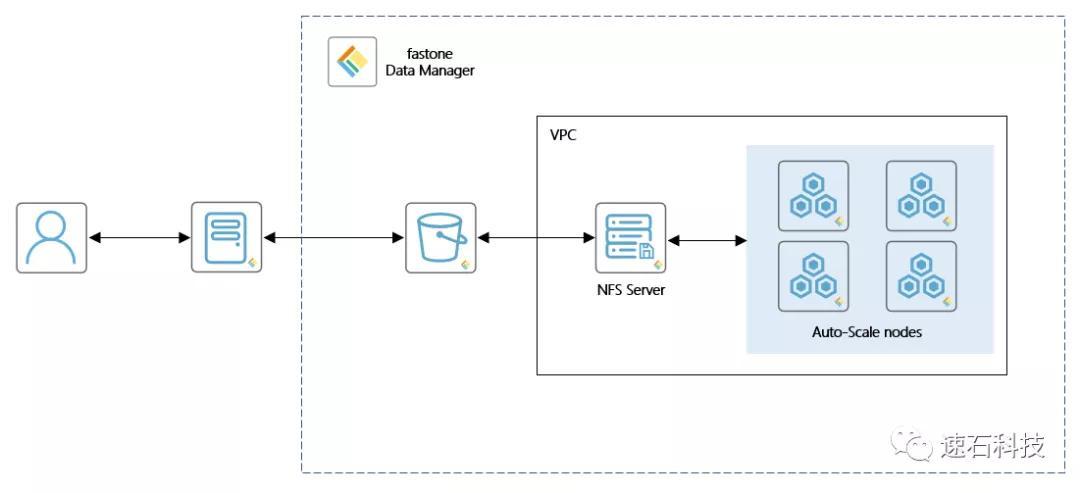
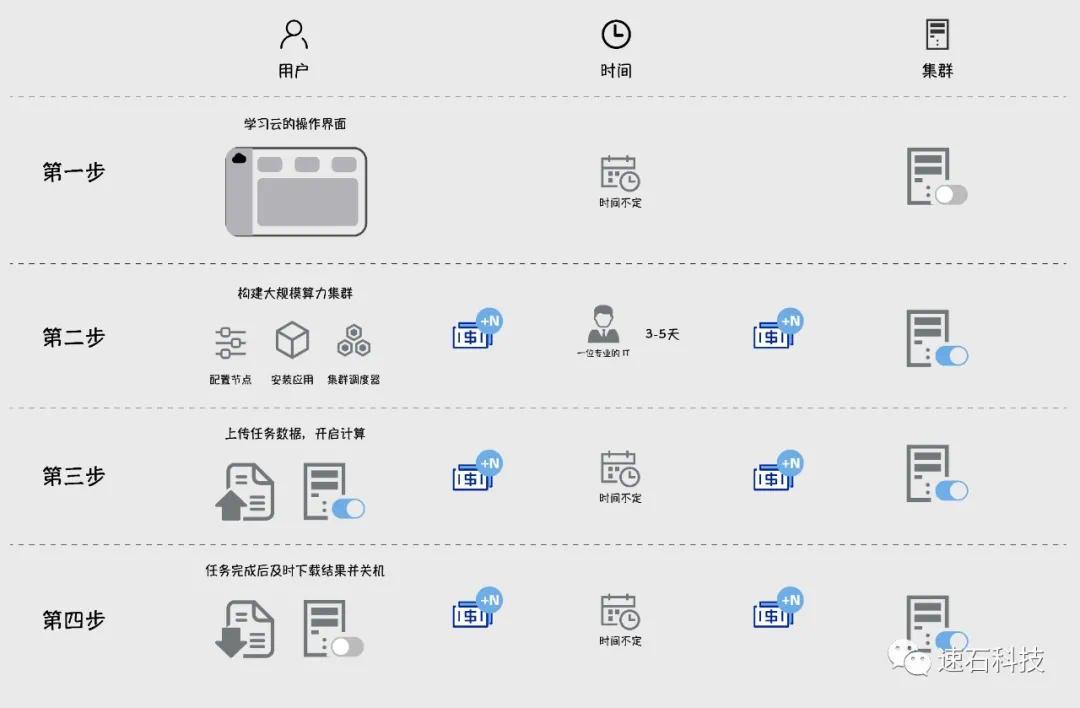
数据只需上传一次即可多次使用,其他用户在经过统一认证后也可随时共享,极大提升团队协同能力。
3、大幅提升传输效率
实证小结
登录后免费查看全文
著作权归作者所有,欢迎分享,未经许可,不得转载
首次发布时间:2021-07-15
最近编辑:3年前

硕士
|
高级工艺仿真...
每次归零重启,都是下次辉煌开始


相关推荐
热门文章
