本课适合哪些人学习:
1、Fluent软件用户和学习者
2、UDF并行化兴趣爱好者和研究者
3、高校学生和教师
你会得到什么:
讲解了udf并行化的具体含义和在什么情况下用udf并行化,什么情况不用udf并行化;
课程介绍:
一、认识UDF
FLUENT UDF(User-Defined Functions)是ANSYS Fluent的一个强大功能,它允许用户自定义求解过程中的一些函数或模型,从而扩展Fluent的求解能力。然而,当涉及到并行计算时,UDF的使用和编写需要特别注意,以确保并行计算的正确性和效率。
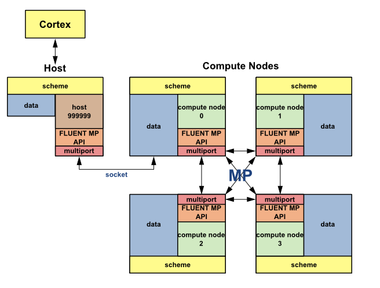
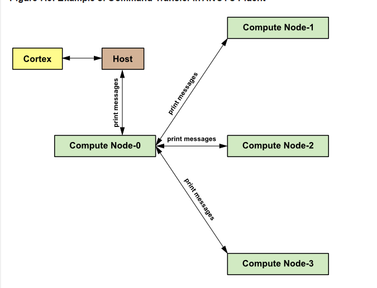
并行计算通常涉及将问题分解为多个子问题,并在多个处理器或计算节点上同时解决这些子问题。在Fluent中,并行计算通常使用基于区域的分解方法,其中计算域被划分为多个子区域,每个子区域在单独的处理器上进行处理。
当使用UDF进行并行计算时,需要考虑以下几个关键方面:
数据同步:在并行计算中,不同处理器之间的数据同步是一个重要问题。UDF必须能够正确处理并行环境中的数据共享和通信。例如,当UDF需要访问或修改全局变量或数组时,必须确保数据在所有处理器之间保持一致。
线程安全:在并行计算中,多个线程可能同时访问和修改相同的内存位置。因此,UDF中的代码必须是线程安全的,以避免数据竞争和不一致的结果。这可能需要使用互斥锁、原子操作或其他同步机制来确保线程之间的正确交互。
负载均衡:为了确保并行计算的效率,UDF应该尽可能地实现负载均衡。这意味着UDF应该避免在特定处理器上产生过多的计算负担,从而导致其他处理器处于空闲状态。
调试和验证:由于并行计算的复杂性,UDF的调试和验证可能更加困难。因此,在编写并行UDF时,建议使用详细的日志记录、断言和测试来确保代码的正确性和可靠性。
为了在Fluent中实现并行UDF,你可能需要查阅ANSYS Fluent的官方文档和UDF指南,以了解如何在并行环境中正确编写和使用UDF。此外,参与相关的社区论坛和讨论组也可能有助于解决在并行UDF开发过程中遇到的问题。
请注意,随着ANSYS Fluent的版本更新,其并行计算和UDF的功能和接口可能会有所变化。因此,建议查阅最新版本的官方文档以获取最准确的信息。
二、讲课内容
本视频课程带领用户学习Fluent UDF 并行化。讲解了udf并行化的具体含义、以及在什么情况下用udf并行化,什么情况不用udf并行化。欢迎订阅和留言互动!

课程相关图片: