利用Python批量处理Abaqus时间历程数据

1. 简介
当使用Abaqus完成求解之后,常常会涉及到计算结果后处理的问题。Abaqus常用的结果输出方式有场输出(Field Output)和时间历程输出(History Output)两种。通常,场输出用于描述在特定时间上某个量随空间位置的变化,而时间历程输出用来描述特点位置上某个量随时间的变化。因此,场输出像是用在特点时间点使用相机拍摄一张全景照,而时间历程输出则更像是聚焦于某一处景色,用摄像机拍摄一部电影。在使用过程中,一般会利用场输出来输出某一增量步处大量单元和节点的结果,而时间历程输出则用来输出少量单元和节点在整个分析步内的变化曲线。
当输出时间历程数据时,大多数的输出结果如位移和应力等,只能逐条输出指定单元集或节点集上的结果,并且不能像场输出那样直接通过Report Field Result或Probe Values工具批量输出单元或节点上的计算结果。
事实上,对于此类涉及到大量重复操作的问题,最好的解决方法为利用Abaqus二次开发批量提取计算结果。因为,原则上所有能够通过Abaqus/CAE交互完成的操作,都可以在Abaqus中通过编写Python脚本来实现。因此,本文将详细介绍Python批量处理Abaqus时间历程数据的实现流程以及解决类似问题的思路。
2. 时间历程数据读取原理
前面已经提到,原则上所有能够在Abaqus/CAE中交互完成的操作,都在Abaqus的Python中有与之对应的脚本命令可供实现。因此,为了在Abaqus中实现时间历程数据的批处理,必须首先清楚与读取时间历程数据相关的命令。这些命令可以通过查阅Abaqus Scripting User's Manual以及Abaqus Scripting User's Reference Manual来获得,其中后者详细说明了Abaqus中各个对象的内置方法、路径以及输入参数的使用方法。当然,对于初学者而言,如果不具备诸如Python之类的面向对象编程和二次开发的基础,直接阅读手册难度较大。另一种可行的方法为在Abaqus/CAE中点选需要实现的功能,由于后台程序会实时将操作指令记录在当前工作目录下的Abaqus.rpy文件中,并且在每次对模型进行保存时,文件保存目录下均会自动生成与模型文件同名的.jnl文件,这两个文件中均记录有整个建模过程所用到的指令,因此用户通过直接查看rpy或jnl文件即可获得与操作对应的命令。
基于这样的原理,石油大学(北京)的焦中良博士开发了实时读取Abaqus/CAE命令的Python Reader软件,该软件通过读取当前工作路径下的rpy文件,可以在界面中实时显示与操作对应的命令。因此,本文首先在Abaqus中打开待提取数据的结果文件(.odb),并利用History Output中的Save As功能将时间历程数据保存为XYData,这里本文选择保存的时间历程数据为整个模型的伪应变能变化(Artificial strain energy: ALLAE for Whole Model)。在完成上述操作中,可以在Python Reader中获得如下所示的命令(部分与操作无关的命令已被去除)。
# -*- coding: mbcs -*-## Abaqus/CAE Release 2020 replay file# Internal Version: 2019_09_14-01.49.31 163176## from driverUtils import executeOnCaeGraphicsStartup# executeOnCaeGraphicsStartup()#: Executing "onCaeGraphicsStartup()" in the site directory ...from abaqus import *from wldConstants import *import customKernel, wldQaTests, wldModulefrom caeModules import *from driverUtils import executeOnCaeStartupodb = session.odbs['C:/Users/Desktop/crack.odb']xy_result = session.XYDataFromHistory(name='ALLAE Whole Model-1', odb=odb,outputVariableName='Artificial strain energy: ALLAE for Whole Model',steps=('Step-1', 'Step-2', ), __linkedVpName__='Viewport: 1')c1 = session.Curve(xyData=xy_result)xyp = session.XYPlot('XYPlot-1')chartName = xyp.charts.keys()[0]chart = xyp.charts[chartName]chart.setValues(curvesToPlot=(c1, ), )session.charts[chartName].autoColor(lines=True, symbols=True)session.viewports['Viewport: 1'].setValues(displayedObject=xyp)
下面我们逐条分析每一条语句的含义。在上面的命令中,带有#的内容为注释行,因此实际有效的内容是从from开始的。在Abaqus中,几乎所有的脚本都以如下的语句起始:
from abaqus import *from abaqusConstants import *
其中第一个语句保证脚本可以正常使用Abaqus中基本的对象(Object),第二个语句则保证Abaqus中定义的各个符号常量可以被脚本正确地获取(例如在Part对象中,符号常量THREE_D表示分析类型为三维)。如果对Python语言有所了解可以知道,第一条语句中的*表示从abaqus中导入所有对象。
随后的脚本还会导入具体操作使用到的模块,例如:
import partimport assemblyimport material
由于我们这里只是提取时间历程数据,并未用到上述模块,所以这些命令并未出现在上述代码中。
当然,上面的命令均没有对应的GUI操作,当我们在Abaqus/CAE中打开数据库文件后,将会在Python Reader中得到下面的语句:
odb = session.odbs['C:/Users/Desktop/crack.odb']上述语句中的Session为Abaqus中最基本的三个对象之一,另外的两个对象为Mdb和Odb对象。Session对象存在于一次Abaqus会话中,它并不能保存到CAE文件或Odb文件中。Session对象也没有对应的构造函数(Constructor),用户不能在脚本中创建一个Session对象。当用户开启一个新的Abaqus窗口时就称为创建了一个新的会话,它会建立新的一套会话对象。而Mdb对象和Odb对象则分别用于存放有限元模型和结果文件,例如在建立有限元模型时需要创建Odb对象。在这三个对象之下,又可以细分为大量的子对象。
前面提到,Session并没有对应的构造函数,这意味着用户无法完成对象的创建以及初始化,即为对象成员变量赋予相应的初始值。这一点从该命令使用的方括号也可以看出,因为在Python语言中,方括号和圆括号具有完全不同的含义。这里需要提到Abaqus中的一个命名规律,那就是对于同样名称的单词(例如上述命令中的odbs),当它首字母大写且通常为单数(Odb)时,那么这个单词对应的函数一般是作为构造函数的,而当它以全小写且通常作为复数(odbs)出现时,它一般是类似字典的容器(repository)。显然,作为字典类的容器,它需要通过方括号来使用指示符,用以匹配已经完成创建的对象(这里以字符串形式表示的文件路径实际上为指示符,通过该字符串即可匹配包含当前结果文件的Session对象);而当它作为构造函数出现时,由于后面需要提供的是待输入的参数,因此使用的是圆括号。因此,通过查看使用的是方括号还是圆括号,很容易知道该条语句是在创建对象还是匹配已经存在的对象。
xy_result = session.XYDataFromHistory(name='ALLAE Whole Model-1', odb=odb,outputVariableName='Artificial strain energy: ALLAE for Whole Model',steps=('Interference', 'Bending', ), __linkedVpName__='Viewport: 1')
在这一行语句中,Abaqus在Session对象中使用XYDataFromHistory方法创建了一个子对象。为了确认XYDataFromHistory确实为Session对象的方法,我们可以利用Session对象的成员变量(member)中的__ members __ 和 __ methods __ 来查看Session对象的相关说明以及方法,并通过 __ doc __来查看该对象的解释信息:
session.__members__session.__methods__session.__doc__
在Abaqus/CAE中输入上述命令得到的输出信息如下所示。
session.__members__['animationController', 'animationOptions', 'attachedToGui', 'autoColors', 'aviOptions', 'charts', 'currentProbeValues', 'currentViewportName', 'curves', 'customData', 'defaultAnimationOptions', 'defaultChartOptions', 'defaultFieldReportOptions', 'defaultFreeBodyReportOptions', 'defaultGraphicsOptions', 'defaultImageOptions', 'defaultLightOptions', 'defaultMesherOptions', 'defaultMovieOptions', 'defaultOdbDisplay', 'defaultPlot', 'defaultProbeOptions', 'defaultProbeReport', 'defaultViewportAnnotationOptions', 'defaultXYPlotOptions', 'defaultXYReportOptions', 'displayGroups', 'displayGroupsAssembly', 'displayGroupsOdb', 'displayGroupsPart', 'drawingArea', 'drawings', 'epsOptions', 'fieldReportOptions', 'freeBodies','freeBodyReportOptions', 'graphicsInfo', 'graphicsOptions', 'imageAnimationOptions', 'images', 'journalOptions', 'kernelMemoryFootprint', 'kernelMemoryLimit', 'kernelMemoryMaxFootprint', 'license', 'linkedViewportCommands', 'mdbData', 'memoryReductionOptions', 'movies', 'networkDatabaseConnectors', 'nodeQuery', 'odbData','odbs', 'pageSetupOptions', 'paths', 'pickingExpression', 'pickingExpressionPart', 'pngOptions', 'printOptions', 'probeOptions', 'probeReport', 'probeVariableLabel', 'psOptions', 'queues', 'quickTimeOptions', 'replayInProgress', 'scratchOdbs', 'selectedProbeValues', 'sessionState', 'sketcherOptions', 'spectrums', 'streams', 'svgOptions', 'textReprOptions','tiffOptions', 'viewerOptions', 'viewports', 'views', 'xyColors', 'xyDataObjects', 'xyPlots', 'xyReportOptions']
session.__methods__['Curve', 'DisplayGroup', 'Drawing', 'EditStream', 'FreeBody', 'FreeBodyFromEdges', 'FreeBodyFromFaces', 'FreeBodyFromNodesElements', 'Image', 'ImageAnimation', 'ImageFromMovie', 'Movie', 'NetworkDatabaseConnector', 'Odb', 'Path', 'Queue', 'ScratchOdb', 'Spectrum', 'Stream', 'View', 'Viewport', 'XYData', 'XYDataFromFile', 'XYDataFromFreeBody', 'XYDataFromHistory', 'XYDataFromPath', 'XYDataFromShellThickness', 'XYPlot', 'convertNXToABQ', 'convertStepToAcis', 'curveSet', 'disableCADConnection', 'disableParameterUpdate', 'enableCADConnection', 'enableParameterUpdate', 'getLimitForXYDataPlots', 'getPathTolerance', 'imageAnimation','isCADConnectionEnabled', 'isUpgradeRequiredForOdb', 'killAllImageAnimations', 'linearizeStress', 'map', 'openAcis', 'openCatia', 'openEnf', 'openIges', 'openOdb', 'openOdbs', 'openParasolid', 'openProE', 'openStep', 'openVda', 'playImageAnimation', 'printToFile', 'printToPrinter', 'saveOptions', 'setAnimationPeriod', 'setCADPortNumber','setLimitForXYDataPlots', 'setPathTolerance', 'setSketchLinearTolerance', 'setValues', 'updateCADParameters', 'upgradeOdb', 'write3DXMLFile', 'writeFieldReport', 'writeFreeBodyReport', 'writeImageAnimation', 'writeOBJFile', 'writeVrmlFile', 'writeXYReport', 'xyDataListFromField']
session.__doc__'Session -> The Session object has no constructor. Abaqus creates the\n session\n member when a session is started.\n
可以看出,Session对象确实存在名为XYDataFromHistory的方法,查询XYDataFromHistory方法,可得到如下信息:
session.XYDataFromHistory.__doc__'Session.XYDataFromHistory(odb, outputVariableName, steps <, name, sourceDescription, contentDescription, positionDescription, legendLabel, skipFrequency, numericForm, complexAngle, stepTuple>) -> This method creates an XYData object by reading history data from an Odb object.'
session.XYDataFromHistory.__members__['__class__', '__doc__', '__name__', '_callerType', '_callerBaseTypes', 'caller', 'im_self']
可见,Session对象中的XYDataFromHistory方法通过读取Odb对象中的时间历程数据创建了一个XYData对象,而我们需要的时间历程数据,也应该是以对象成员的形式存储在XYData对象中。上述输出信息中还列出了使用该方法所需要提供的参数,即XYData对象名,Odb对象,输出时间历程变量名(outputVariableName)以及对应的分析步(steps)。对于本文提取的伪应变能数据,从Python Reader输出的命令中可以看出XYdata的对象名为ALLAE Whole Model-1,而Odb对象即为前一行命令所引用的Odb对象,输出时间历程变量名为Artificial strain energy: ALLAE for Whole Model,该名称与Abaqus/CAE中给出的时间历程变量名是完全一致的,而steps分别为Step-1和Step-2,注意这里steps使用了Python中的元组(tuple)数据类型。
在后续的语句中,Abaqus通过Session对象中的Curve和XYPlot方法创建了XYCurve类和XYPlot类的对象,从而实现将伪应变能曲线绘制到Abaqus界面上。由于这一部分语句已经不涉及时间历程数据的提取,因此不再解释相关的使用方法。
通过前面的分析可知,当使用Session对象中的XYDataFromHistory方法后,Odb对象中的时间历程数据应该是以对象成员的形式存储在XYData中,因此我们可以利用print函数打印输出XYData对象中的成员变量的取值:
odb = session.odbs['C:/Users/Desktop/crack.odb']xy_result = session.XYDataFromHistory(name='ALLAE Whole Model-1', odb=odb,outputVariableName='Artificial strain energy: ALLAE for Whole Model',steps=('Interference', 'Bending', ))print xy_result
打印输出的结果如下所示:
[(0.0, 0.0), (0.00100000004749745, 0.00169714575167745),(0.0020000000949949, 0.00541929947212338), (0.00350000010803342, 0.0151513451710343),(0.00575000001117587, 0.0397449545562267), (0.00912499986588955, 0.0993359461426735),(0.0141874998807907, 0.239913642406464), (0.021781250834465, 0.566149652004242),(0.0331718735396862, 1.31537020206451), (0.0502578131854534, 3.02436423301697),(0.0758867189288139, 6.90517616271973), (0.11433007568121, 15.691478729248),(0.171995118260384, 35.5423583984375), (0.258492678403854, 80.329833984375),(2.0, 1271.48364257813)]
可以看到,XYData对象的数据类型为列表(list),而时间历程数据以元组的形式存储在该列表中(在Python中列表中的取值可以修改,而元组中的取值不可修改)。实际上,这里我们已经取得了时间历程数据,因此后续只需要利用Python文件I/O函数即可将这些时间历程数据写入到文本文件中,并进行进一步的处理。
3. 时间历程数据批量处理流程
在前面一节中,我们展示了利用Python语言提取Abaqus时间历程数据的实现流程。当提取的时间历程数据较多时,我们可以利用Python的循环语句实现数据的批量提取。
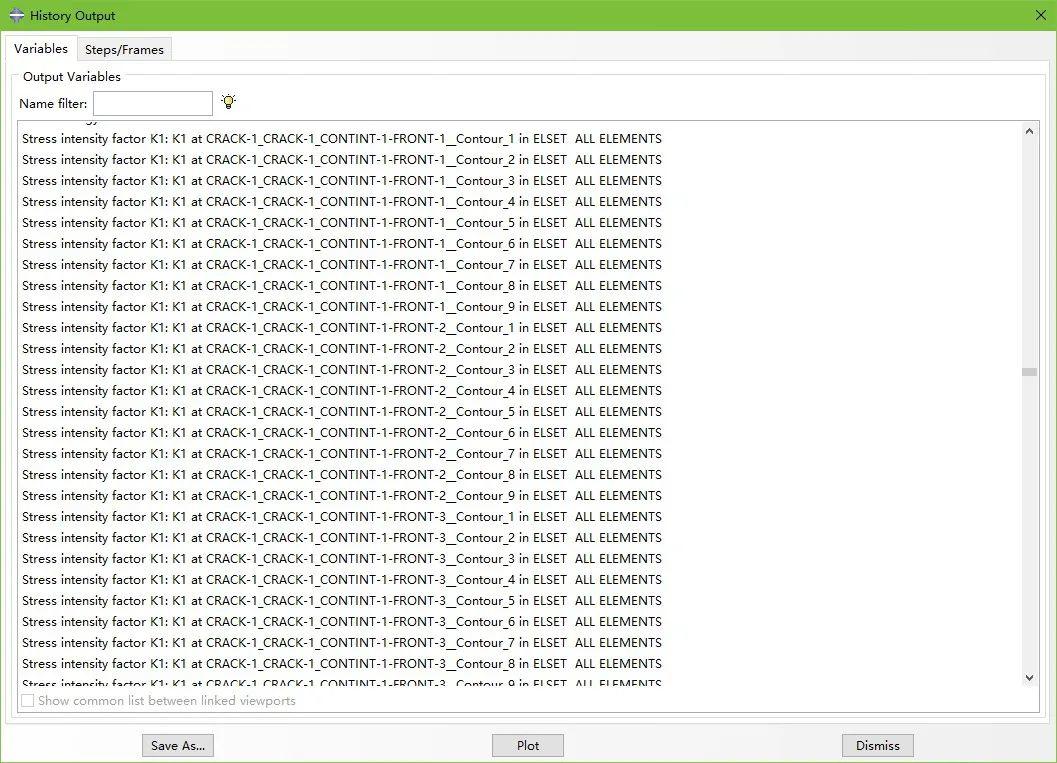
下面,本文以图1.1中的时间历程数据为例,介绍利用Python语言批量提取数据的流程。通过前面的介绍我们已经知道,提取时间历程的关键步骤为利用Session对象中的XYDataFromHistory方法创建XYData对象,通过在该方法的outputVariableName中指定不同的输出时间历程变量名,即可获得不同的时间历程变量数据。观察图1.1中时间历程变量名称可发现,Abaqus的时间历程变量命名非常具有规律性,例如,对于第i个裂纹前缘节点的第j个围道,其对应的时间历程变量名可以表示为Stress intensity factor K1: K1 at CRACK-1_CRACK-1_CONTINT-1-FRONT-i__Contour_j in ELSET ALL ELEMENTS。(注意区分单下划线、双下划线以及空格)
因此,我们可以在程序中预定义需要使用的时间历程变量名称,随后通过构造循环语句调用该名称即可实现批量提取时间历程数据。
基于这样的思路,我们首先在程序定义Odb文件路径以及裂纹前缘节点和围道数量。
#-* - coding:UTF-8 -*-#第一行语句用于在Abaqus中支持中文注释Contour_num = 9 #围道数量Crack_front_num = 201 #裂纹前缘节点数量ODB_file_directory = 'C:/Users/Desktop/' #Odb文件所在路径,注意最后一个/ODB_file_name = 'crack.odb' #Odb文件名Step_name = 'Step-1' #待提取时间历程数据所在的分析步
随后我们创建三个二维数组,分别用于存放XYData对象名以及对应时间历程数据变量名,预定义的时间历程数据变量名可以用于匹配时间历程数据,提取得到的时间历程数据被存放在一个单独的数组中。
SIF_KI_data_name=[['SIF_KI_data_name']*(Contour_num+1) for i in range(Crack_front_num+1)]for i in range(1, Crack_front_num+1):for j in range(1, Contour_num+1):SIF_KI_data_name[i][j]='SIF_KI_Crack-1_Front-'+str(i)+'_Contour_'+str(j)SIF_KI_outputVariable_name=[['SIF_KI_outputVariable_name']*(Contour_num+1) for i in range(Crack_front_num+1)]for i in range(1, Crack_front_num+1):for j in range(1, Contour_num+1):SIF_KI_outputVariable_name[i][j]='Stress intensity factor K1: K1 at CRACK-1_CRACK-1_' \+'CONTINT-1-FRONT-'+ str(i)+'__Contour_'+str(j)+' in ELSET ALL ELEMENTS'KI = [[0.0]*(Contour_num+1) for i in range(Crack_front_num+1)]
在完成前期的参数定义后即可开始读取Odb文件。
#Read odb filesession.openOdb(name=ODB_file_directory+ODB_file_name)Fatigue_Crack_odb=session.odbs[ODB_file_directory+ODB_file_name]
随后利用Session对象中的XYDataFromHistory方法提取时间历程数据,由于时间历程数据是一组随时间变化的数值,这里我们只提取数据中的最后一个数值(对应的列表指标为-1,在Python中表示倒数的第一个数据)存放到二维列表中,该数值对应于当前提取分析步内的最后一个增量步。如果需要提取其他时间点的数据,直接修改列表的指标即可。
for i in range(1, Crack_front_num+1):for j in range(1, Contour_num+1):SIF_KI_XYData = session.XYDataFromHistory(name=SIF_KI_data_name[i][j], odb=Fatigue_Crack_odb,outputVariableName=SIF_KI_outputVariable_name[i][j],steps=(Step_name,))SIF_XYData_length = len(SIF_KI_XYData)SIF_KI_data = [0.0]*SIF_XYData_lengthfor K_length in range(0, SIF_XYData_length):SIF_KI_data[K_length] = SIF_KI_XYData[K_length][1]KI[i][j] = SIF_KI_data[-1]
提取完成后,通过Python的I/O函数将时间历程数据写入到文本文件中:
#写入数据到文本文件file_SIF_info = open('SIF_DATA.txt','w')file_SIF_info.write('%-30s' % 'CRACK FRONT number')file_SIF_info.write('%-30s' % 'Contour number')file_SIF_info.write('%-30s' % 'KI value')for i in range(1, Crack_front_num+1):for j in range(1, Contour_num+1):file_SIF_info.write('%-30d' % i)file_SIF_info.write('%-30d' % j)file_SIF_info.write('%-30.4f' % KI[i][j])file_SIF_info.close()
将上述命令以文本格式保存为py文件,在Abaqus中通过File中的Run Script运行脚本文件,即可提取时间历程数据,并将其保存到名为SIF_DATA.txt的文本文件中,部分输出的时间历程数据如下所示。

由于输出为文本文件时是以固定格式输出的,因此这些数据很容易就可以导入到Matlab中并进行进一步的处理。这里,本文为了简单起见,只提取了分析步中最后一个增量步对应的时间历程数据。在上面的程序中,由于所有的时间历程数据都存储在SIF_KI_XYData中,只需要简单修改程序,即可提取整个分析步的时间历程数据。
需要指出的是,在Abaqus中时间历程数据的提取有很多种实现方法。例如,由于在Odb对象中储存有整个模型的结果数据,因此通过Odb对象提供的方法,同样可以获取到时间历程数据。
4. 类似问题的处理思路
在利用Abaqus中进行计算中,往往都会遇到数据提取的问题,当提取的数据量较大时,采用Abaqus内置的Python批量提取数据是一种非常简洁高效的方法。对于初学者而言,如果不清楚某个数据的提取过程如何在Abaqus中利用Python实现时,可以首先在Abaqus/CAE中完成单个数据整个提取流程的操作,随后通过查看.rpy文件来获取与之对应的命令。通过查看这些命令,我们可以比较清楚地了解各个对象之间的继承关系,并通过 __ doc __ 来查看相关对象的解释,以及__ methods __ 来查看对象所有可以使用的方法,必要时还可以通过print函数输出对象所有的成员变量。如果上述信息仍不足以弄清某个对象和其方法所具备的功能,则可以结合Abaqus Scripting User's Reference Manual来确定相关操作对应的实现语句。一旦提取到所需要的数据,即可通过Python的I/O函数将这些数据写入到文本文件中。
目前,Abaqus2020中同时内置有python 2.7.15以及python 3.7.3,并且还自带有scipy和matplotlib等数学库,这意味着直接在Abaqus中即可完成相应的数据处理。同时,由于Abaqus2020使用了较高版本的python,因此可以直接使用pip来安装第三方库,这无疑极大地扩展了Abaqus的二次开发功能。
附录:时间历程数据提取完整程序
#-* - coding:UTF-8 -*-#Programed by Mr.Xu#This script can be used to extract SIF from odb file in Abaqus#Parameter should be set in main functionContour_num = 9 #Defined by user in step moduleCrack_front_num = 201 #Correspond to the number of node in crack frontODB_file_directory = 'C:/Users/Desktop/'ODB_file_name = 'crack.odb'Step_name = 'Step-1'#Creat stress intensity factor nameSIF_KI_data_name=[['SIF_KI_data_name']*(Contour_num+1) for i in range(Crack_front_num+1)]for i in range(1, Crack_front_num+1):for j in range(1, Contour_num+1):SIF_KI_data_name[i][j]='SIF_KI_Crack-1_Front-'+str(i)+'_Contour_'+str(j)#Create SIF outputVariable nameSIF_KI_outputVariable_name=[['SIF_KI_outputVariable_name']*(Contour_num+1) for i in range(Crack_front_num+1)]for i in range(1, Crack_front_num+1):for j in range(1, Contour_num+1):SIF_KI_outputVariable_name[i][j]='Stress intensity factor K1: K1 at CRACK-1_CRACK-1_' \+'CONTINT-1-FRONT-'+ str(i)+'__Contour_'+str(j)+' in ELSET ALL ELEMENTS'#Read odb filesession.openOdb(name=ODB_file_directory+ODB_file_name)Fatigue_Crack_odb=session.odbs[ODB_file_directory+ODB_file_name]#Extract stress intensity factor from odb fileKI = [[0.0]*(Contour_num+1) for i in range(Crack_front_num+1)]for i in range(1, Crack_front_num+1):for j in range(1, Contour_num+1):SIF_KI_XYData = session.XYDataFromHistory(name=SIF_KI_data_name[i][j], odb=Fatigue_Crack_odb,outputVariableName=SIF_KI_outputVariable_name[i][j],steps=(Step_name,))SIF_XYData_length = len(SIF_KI_XYData) #Obtain the length of SIF_KI_XYDataSIF_KI_data = [0.0]*SIF_XYData_lengthfor K_length in range(0, SIF_XYData_length):SIF_KI_data[K_length] = SIF_KI_XYData[K_length][1]KI[i][j] = SIF_KI_data[-1] #Extract the last value in data#Write data to text filefile_SIF_info = open('SIF_DATA.txt','w')file_SIF_info.write('%-30s' % 'CRACK FRONT number')file_SIF_info.write('%-30s' % 'Contour number')file_SIF_info.write('%-30s' % 'KI value')for i in range(1, Crack_front_num+1):for j in range(1, Contour_num+1):file_SIF_info.write('%-30d' % i)file_SIF_info.write('%-30d' % j)file_SIF_info.write('%-30.4f' % KI[i][j])file_SIF_info.close()


