开发国产软件CAE求解器!我放弃“站在巨人的肩膀上”


导读:大家好,我是郭志鹏,适创科技创始人兼CEO,毕业于清华大学(本、博),牛津大学、英国皇家学会研究会员,长期从事数字化工业方面的研究,包括高性能算法、高能X射线检测、图像处理以及相关工业领域的材料和核心工艺开发等,立志创造有国际竞争力的自主化CAE软件,摆脱国际垄断,提升和振兴民族工业水平。曾几何时,我们团队注册了仿真秀实创科技官方认证机构,将在这里讲述适创科技CAE计算平台在铸造注塑行业,以及汽车、航空航天和核电等领域,助力整个中国工业的数字化转型的故事。
01 什么是CAE求解器?
“能不能用一句话来描述清楚什么是求解器?”很多投资人朋友都这样问过我。
讲求解器之前先要对CAE有个明确的概念。CAE,也即计算机辅助工程,通过求解器解析和模拟真实物理现象,用“虚拟”的方式再现工程生产过程。如果说CAD是我们用来辅助设计的工具,那么CAE要做的就是用“虚拟”来评估这些“实际”的设计,这也是CAE的内核和最本质的作用。作为最重要的核心元素,求解器要做的就是“精确”地把握和还原真实物理现象,进而给出评估、评判“生产过程”好坏的标准。
在此基础上,如果真用一句话来描述求解器,那我会说:“CAE求解器是一个具备描述特定物理现象能力的矩阵运算代码包。”
首先,它必须得能解决某种类型的物理问题(通过求解描述这个物理过程的PDEs——偏微分方程组);
其次,它是个代码包或者库;
再者,这个库的主要功能是做矩阵(逻辑和/或代数)运算。
这样看起来似乎很复杂,但其实CAE求解器和我们日常生活中的计算器没有本质区别,当我们在计算器上敲入一些数字和运算符号,点击下令计算的等号“=”后就会产生结果,整个计算过程就是“求解器”完成的,它内嵌到了设备中,我们看不见,但是我们知道它存在。
CAE求解器与之类似。拿流体力学求解器来讲,在求解时同样需要输入一些参数,例如材料属性参数(如粘度)、温度、初始条件(如速度、压力)、边界条件(滑移、无滑移、镜像、对称)等,将这些参数输入到软件的“计算器”中,点击下令计算的等号“=”,就可以获得结果,基于这个结果我们再做后续的分析。
与计算器简单的计算过程相比,计算流体形态的过程更为复杂。首先,流动是一个随着时间会持续演化的过程,它的解不恒定,而是在每一时刻都有一个解;其次,评估流动形态不能只靠一个数字,而是需要多维指标来评估,例如速度、压力、紊乱度、界面形态等,甚至包括涡量、旋度、能量耗散等。人们发明出一系列的无量纲数来衡量流动的状态,比较著名的有雷诺数、普朗特数、瑞利数等。之所以有这么多指标,就是因为流动本身的自由度(涉及的变量、空间和时间)很大,我们无法仅对其进行简单的“好”或“坏”的评估。
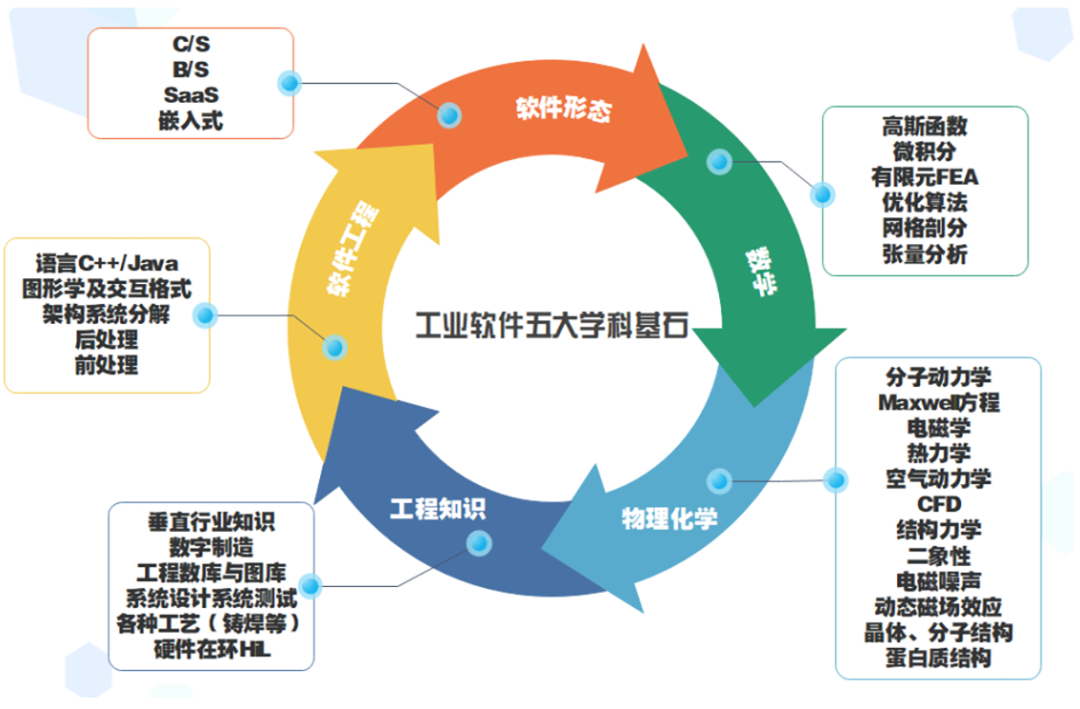
工业软件五大学科基石[1]
不难看出,CAE求解器的研发需要多学科的交叉融合再加上强大的编程能力,其研发门槛之高可见一斑。关于要不要开发自主CAE求解器,我常举的一个例子是:CAE求解器对于工业CAE软件,就像航空发动机是飞机的心脏一样重要。
GE、PH的航空发动机在技术实力上远远领先我们,买来后直接组装在飞机上不就可以了吗?但被誉为“工业皇冠上的明珠”的航空发动机,是集成众多尖端技术的核心装备,加快其自主可控国产化替代的脚步已经刻不容缓,截至2020年底,由中央国务院批准设立“航空发动机与燃气轮机”国家科技重大专项(“两机专项”)的投入已经达到3000亿元。[2]
同样的道理,CAE求解器对工业CAE软件来讲就是引擎,是心脏,而这颗心脏一直是从美国、德国等发达工业国家漂洋过海远道而来,为我国的工业制造“施舍”着血脉奔涌的动力,我们享受到了这些“美国味”、“德国味”的甜头,尽管对它们也有诸多不满,却依然在这唯一不二的选择前甘之如饴。可是华为被制裁、MATLAB禁用等事件让大家从温水煮青蛙的安逸中醒悟过来,这颗心脏已经慢慢变成了一颗“定时炸弹”,不知道什么时候就可能让依赖着它的本体遍体鳞伤。于是大家开始高举“国产化替代”的大旗,工信部也把工业软件列为十四五规划“新五基”之一,整体政策环境欣欣向荣,就等着CAE厂商及锋而试,弯道超车。
而所有CAE厂商面前最大的拦路虎,就是求解器。
别人花了十年甚至二十年攻克的研发成果,我们想用一两年就啃下来,这在大部分人看来是不现实的,有能力也有勇气啃硬骨头的,可以说寥寥无几,屈指可数。而就是在这样残酷的现实下,我创立了适创科技,决定投身自主CAE求解器的开发。
02 “站在巨人的肩膀上” or “成为巨人本身”?

五年前,我是适创科技“第一代”也是当时唯一的算法工程师。作为一个“科研工作者”,我的想法很简单:先实现算法原型,再去优化,用fortran90编程——一个不那么规范但却高效的语言。5年的博士生涯,加上近7年的国内外工作经验,我积累了大量的对物理模型和数值算法的理解,为我带来的最直接的好处就是,针对一个工程问题涉及到的物理模型,我不再需要尝试所有的数值算法去做百里挑一的筛选,因为我已经大概率知道哪个算法对这类模型最有效。因此,在开发流体力学求解器时,我毫不犹豫地选择了LBM——格子玻尔兹曼方法。我告诉自己,绝不能让这个求解器成为呆在“实验室”里的一堆in-house代码,我们必须让这些代码成为真正的计算引擎来服务于工业客户,创造真正的价值。
当时的我站在十字路口的中央,一条路是下载开源软件库,基于这个库做二次开发,形成“自己”的求解器;另一条路是一切从0开始,解析、分解模型,选择、适配数值算法,编码、优化、迭代,最终形成自主的求解器。
选择一个好的开源软件库就可以说是“站在了巨人的肩膀上”,毕竟,这些开源软件包是由大量的算法、软件工程师编写的,其总体工作量可以达到数百人年。如果是好的库、优质的库,其代码规范、运行效率都很高,在此基础上进行二次开发、迭代的话,如果继承者团队本身实力很强,完全可以创造出更优质的代码库,这其实就是一个继承和升级的过程。但是从另一个角度上讲,这种继承和升级也存在着很大的风险。
首先,“站在巨人肩膀上”站得能有多高,取决于这个“巨人”本身有多高。我前面也提到了,这个开源软件库一定要是优质的,但是如何判断它到底是不是优质的呢?退一步讲,如果确实是优质的,能不能下载、买到也是不确定的。互联网上充斥着大量的开源代码,其中所谓的开源求解器,毫不避讳地说,它们大部分都是垃圾,并不具备实际的竞争力。真正有价值的开源库少之又少,而且大部分时候都存在因为一系列政治因素影响下的不可获取性。
其次,可以获取到的开源代码库大部分来自高校、研究院、国家实验室或一些“业余”兴趣爱好者,他们基于某些国家、政府项目编写的代码包,其实质目的是为了方便做研究,通过这些已“成形”的代码结合二次开发,便于科研人员更快速地开展各自的研究。所以总得来说,这些代码库并非为了商用,它只是提供一个框架,让科研工作者可以更高效地产生新的模型和知识。
再者,开源软件库在计算稳定上会有一系列问题。因为其重研究的属性,开发人员更多考虑的是它能不能解决某一类或某几类问题,而不会花很大精力去考虑各种情况(特别是复杂边界条件)去完善和优化代码的稳定性。在这种情况下,如果是两个完全不同的领域需要代码做适配,就会存在许多计算稳定性的隐患,最终稳定与否就完全决定于后来者的技术水平了。
所以,基于开源软件做“自己”的求解器,既取决于开源代码本身的质量或高度,也取决于继承者本身的技术水平。如果后者的水平在前者之下,那最多就发挥到前者本身的水平,而如果后水平远高于前者,那就可以发挥出两者能力乘积的倍数效应。但对于CAE求解器类型的开源软件,特别是针对难度较大的流体、结构塑形求解器来说,后一种情况非常罕见,因为对这些难度较大的CAE求解器来讲,其开发本身就已经不容易了,继承者要在技术实力上超过前辈,除非是有组织和有传承性的继承,否则其可能性是微乎其微的。
那么第二条路,也就是自己从0到1来开发呢?
很显然,相较于继承开源,成功自主开发CAE求解器的不确定性更大,毕竟继承开源进行开发最差的情况下也肯定有一个“求解器”,但是独立摸索进行自主开发的话,有可能的结果就是0成果,什么也没开发出来,或者更可能的是开发出一个“矮子”求解器,毫无竞争力,这种求解器对研究工作来说有可能有一定意义,但是做为商用化是完全不行的。这种“矮子”不是特例,而是一种普遍现象,也是我们国内一直没有能真正商用化的求解器的最本质原因。
如果说商用求解器需要算法和软件本身成熟度达到9级(准确性、稳定性、计算效率各3级),那么我们目前所能看到的大部分求解器只能达到3-6级。真正能商用化、有产业、国际竞争力的求解器,拿流体力学来讲,全世界其实也没有几个。所以可想而知这是一个多么有挑战的事,但是完全自主开发求解器这条路最大的好处,就是我们可以从“一张白纸”开始,拥有所有的自由度,从另一个维度来理解和摸索,整个开发过程并没有任何框架或天花板,所有的天花板都取决于开发者本身。
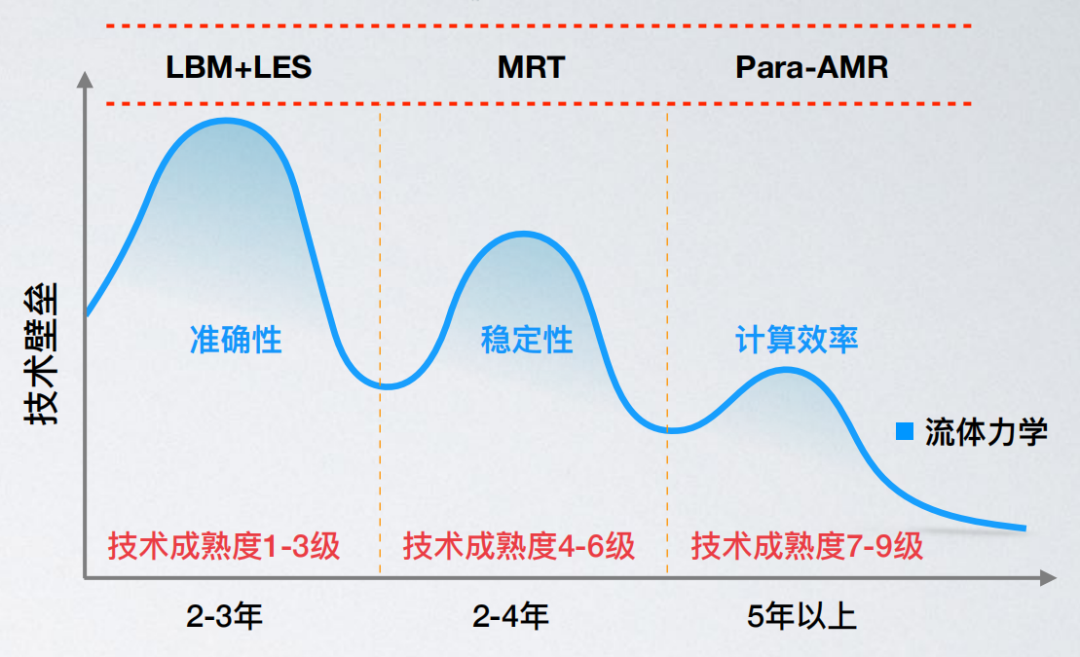
求解器的技术成熟度
对产业应用来讲,工业仿真软件最重要的产品属性其实是时效性,也就是在满足客户需要的前提下尽可能为客户节省时间、提交效率,翻译成求解器的能力,那就是计算稳定性和计算效率,在这个大前提下才能去探讨计算精度。
影响计算精度的因素非常多,相较于算法中的“数值阶数(order)”,计算精度更多地取决于边界条件或环境约束的影响,反而并不是求解算法本身。我记得一位著名学者说过:模拟计算中,如果你的输入是垃圾,那结果必定也是垃圾。不得不承认,就算有“完美”精确性的求解器,如果在输入阶段就漏洞百出,那么计算结果就完全没有参考价值。因此,想要在计算精度上做文章,我们更应该聚焦于如何能把“输入”做对,而不是过多地苛求数值计算“阶数”的提高。
我举一个热咖啡变凉的例子。
假设我们要模拟热咖啡随着与周围环境(杯子)不断热交换而变凉的过程,实现这个计算我们要知道咖啡、杯子等材质的热物性参数,也就是和传热相关的材料本身属性,包括热导率、密度、比热容等,同时,我们也要知道初始条件,包括咖啡、杯子的初始温度,然后我们做好几何模型,将参数代入传热求解器开始计算并产生结果。实际上即便我们不做计算也会感觉到,咖啡变凉的速度不完全决定于这些参数,而更重要的是取决于杯子的类型,比方说一个是普通的杯子,另一个是保温杯,显然保温杯条件下咖啡凉的慢。实际上,在这个简单的传热过程中,真正决定传热效率的是咖啡和杯子之间热阻,保温杯的热阻明显比普通杯子的大,因此整体传热更慢。但是真正的问题来了,我们在计算这样一个简单问题的时候,咖啡和杯子之间的界面热阻该怎么设置呢?显然,设置不当,计算出来结果的精确性会急剧下降。这个小的例子其实引申出来一个很重要的分析思路,也就是在模拟仿真过程中,决定计算结果精确性的是那些核心输入参数,比如上面所说的界面热阻,想提高我们对真实过程模拟的精确性,我们一定要抓住、关注这些核心输入参数,而不是眉毛胡子一把抓、捡了芝麻丢了西瓜。在这个例子中,如果材料热物性参数对计算准确性的贡献是1的话,那么界面热阻的影响就至少会达到10,甚至在一些实际生产过程可以达到100。在很多与科研工作者或实际使用仿真软件的客户交流的时候我往往能发现这个问题,就是大家过多地关注一些不是那么重要的参数,反而对那个起决定作用的输入参数或边界约束条件视而不见。其实也不是视而不见,是因为往往这些参数是最难理解和确定的。
03 从求学到创业,我的CAE追寻之路
我被问过最多的问题就是为什么要做CAE仿真,为什么选择这个方向创业?
创立适创科技并聚焦工业CAE仿真,跟我之前求学和工作的经历有很大关系。让我真正对数学,特别是应用数学产生浓厚兴趣,得益于我在大学和研究生期间接触到的课程和老师。那时的我第一次接触到数学建模、线性代数、数值分析、偏微分方程等,包括后来结合工程项目从事了多年研究,我使用CAE仿真软件(自己写的或商业软件)做了大量的针对实际工程问题的模拟计算和数据分析,也是从那时起,我发现善于使用CAE能够解决很多看起来复杂的工程问题。

我的研究记录
博士期间,我又对各种各样的物理、数学问题、数学方法着迷,沉醉在经典和量子力学、微分方程和离散、线性代数和矩阵变换、无量纲化和降维分析、复变函数和密度泛函、格林公式和数值算法、分形几何和混沌、拓扑结构和特比乌斯环这样复杂而美妙的世界里。我常常在工作之余的时间翻看这些领域的论著,旁听学校的课程,参加相关的论坛,不断地在学校各个教室间穿梭。兴趣逐渐转化为能力,线性代数(矩阵运算)和数值分析(数值算法)这两大工具已经能很好地为我所用,这也对我从事求解器开发产生了重要的推动作用。
曾经在牛津大学求学和工作时,导师对我说他很担心自己的儿子,度假时手里也捧着本量子力学,太专注学习而无法消遣。“他没问题的,他只是跟别人不同而已。”我说,因为在内心里我很理解他。
我一直认为自己更像个工程师(Engineer),而不是个纯科研工作者(Scientist),因为工程师的职责是把科学转化成应用。我的博士课题做的是反问题(inverse problem),也就是逆向计算。正常的模拟计算一般是把控制参数和边界条件输入到一个所谓的“求解器”中产生结果,从而分析结果,得出新的知识;而求解反问题则与之相反,需要将已经测量得到的实际结果,输入到“反算模型”中,求解得到与问题相关的输入条件,包括控制参数或边界条件。
没有想到的是,博士课题做的这个反算模型,在后来我们自主开发CAE软件的时候很幸运地帮我们解决了一个困扰这个行业很久的难题,可以说是意料之外却又在情理之中。

我们的第一个CAE产品叫「智铸超云」,是针对压铸行业的仿真平台,它试图解决的行业问题和前面热咖啡变凉的例子很像:在充填进入型腔的过程中,熔化的铝合金液体会不断地与模具发生热交换,整个过程金属液变凉的速度主要取决于金属液和模具壁面之间的界面热阻,或者说界面换热系数(热阻的倒数),这个参数设置的正确性显著地影响着整体传热计算的精确性。而实际上,这么多年,大家使用模拟仿真软件时这个参数都是“猜”的,甚至在很多情况下都是“乱填的”。我们发现,在这种情况下,客户计算金属液凝固(液体变成固体)预测得到的凝固时间往往是实际的2~3倍,也就是说模拟产生的误差可以达到100%~200%,但是有意思的是,大家还在基于这个结果进行后面的分析。这里面的核心问题就是几乎没有人知道换热系数应该怎么设置!
怎么解决这个问题呢?其实很简单,我们需要做一些实验,在大量压铸生产过程中不断采集实际温度,然后通过反算求解出金属液和铸型之间的换热系数,再把这个数值加到模型中去实现精确求解——而这就是我博士课题的主要工作。得到这些换热系数之后,我们发现,类似于压铸这种复杂过程的换热系数不是一个固定的值,而是一个随空间位置和时间不断变化的值,我们称之为4D界面换热系数。得益于这个界面换热系数模型,智铸超云计算凝固过程温度场的精度可以达到95%以上,绝大部分情况下其计算预测的凝固时间与真实铸造过程都极其贴近。可以想象基于这个温度场结果进行后续缺陷分析,对实际工艺设计和工艺生产能够带来多大的价值。
04 第一版LBM流体求解器的诞生

几年的国外求学和工作生活让我有更多的机会去思考,同时结合不同类型的研究项目,我对各种数值算法都有了非常深入的理解,并且有机会在各种情形下编写和使用这些算法,从而细致入微地体会它们之间的差异。
这些数值算法的核心目的只有一个——用最快的方式寻找到问题的解或“根”。而在实现路径上,几乎所有算法都采用一种渐进式摇摆的方式来逼近最终的解,也就是所谓的迭代。这就像一个受到摩擦力的钟摆一样,多次左右摆动后最终滑落并稳定在最底端的位置。但如果钟摆没有稳定向下,那必然会像发疯一样地乱摆,这在数值模拟上就是计算“发散”。
大部分的工程实际问题在分解模型、离散后都可以转化成求解一个线性方程组,而评估这些数值算法优劣的最佳方式就是看它们在求解这个线性方程组的时候所表现出的计算稳定性和计算效率。在通往最终目的地的过程中,不同算法采用的思路或路径完全不同,大部分矢量算法主要是通过建立多维正交系统来寻找“根”的坐标位置,比如一个简单的三维问题,求解一个三元(Z、Y、Z)一次线性方程组的解,最终的解其实就是一个三元正交系统中的一个点,或者说特定坐标值X*、Y*、Z*。而这个三元正交系统,或者说“子集”可能是个三维空间,也可能是一个面或是一条线。
实际问题比这个要复杂的多,很多情况下我们求解的是一个“非常”多元的线性方程组的解,比如网格量如果是1000万,那就是1000万元线性方程组。三元一次线性方程组的解也许我们可以口算出来,但是1000万元呢?回到矢量算法,当求解的未知数或“元”越来越大时,由于我们对计算的精度要求越来越高,我们熟知的各种数值算**相继失效,当然不同算法失效的快慢不同,而这个快慢就体现出了算法本身的能力边界。极限的情况,如果我们求解的问题所需的精度已经超越了计算机浮点误差范围时,那所有的数值算法都失效了。所以,数值计算是一个数值算法和计算机的“联袂演出”,缺一不可。
我还记得我用MAC法求解NS方程过程中,要不断迭代求解泊松方程,如果你选用的算法能力不行,那求解这个方程就太费劲了,可能迭代了几十、上百步求解的精度也没怎么提升,如果你设定的收敛限制很苛刻,那么这个方程可能永远不会收敛,也就是“永远”没有解。

我的研究记录
为了解决这个问题,我当时尝试了几乎所有的数值算法,但都没什么效果,直到我花了很大精力写了一个多重网格(Multigrid)算法之后才如获至宝、豁然开朗。与矢量算法的理念不同,多重网格算法通过变换网格尺寸的方式来消除计算偏(误)差,在消除误差效率方面要远胜于只采用基于底层消去法的矢量算法。在这方面,多重网格算法就像是在不断变换视镜、物镜放大倍数,从而可以更加清晰地观察到各种”尺寸“的误差并消除误差,而矢量算法则是只有一副视镜和物镜,不论你把眼睛睁得多大,也看不清楚更细节的东西了。多重网格算法给我最大的启发就是:不管数值问题本身有多难,总是有解决问题最好的办法,更重要的是要敢于变换思路、变换视角去想问题,而不是一味地“蛮”算和“笨”算。
最早期的基于LBM的流体力学求解代码是我在英国工作的时候开发的,主要用于模拟铝合金微观组织生长过程中溶质的流动和偏析,这版代码更多的是对算法本身功能的实现,我并没有在计算效率上做过多的优化。创立适创科技的第一年,陆陆续续,我对这版代码进行了优化,首先将之前的代码从脚本语言(Matlab、Octave)转化成了fortran90语言,并对其计算效率、边界条件做了很多优化,我尝试用各种各样的网格形态和差分格式来提高计算精度、计算稳定性和计算效率,最终我们确定了一套属于自己的代码架构。
首先,我们需要确定数据格式和网格架构,这是所有向后延伸求解器的基础,一套高效的网格系统能极大增强计算精度、计算稳定性甚至计算效率。网格系统对于CAE仿真就像是底层基因,每一个网格都相当于一个细胞,细胞所能具备的形态、灵活性直接决定了后期求解能够具备的能力天花板。在谨慎的思考和选择下,最终我们采用了基于块体结构的多层加密网格系统(block structured adaptive mesh refinement architecture,BS-AMR)。因此,针对某一问题的整体网格系统是多层的,比方说对一套模具进行网格剖分,我们可能要做5-6层,描述不同组件需要的网格大小不同,对于物理现象变化没那么明显的地方我们用粗网格,而对于物理现象变化明显或是我们更加关注的地方,我们则用细网格。
这样剖分下来,整体网格像金字塔一样,越到上层,网格尺寸越小,对问题的描述越精确,但其覆盖的领域则更小。这种网格系统有一个很大的好处就是我们不需要用最小的网格剖分整个计算域而导致的极大计算规模,分层加密后剖分,整体网格量大概是全域(细)剖分状态下的1/100~1/500,这样可以极大地缩小整体计算规模,在保证精度的前提下,极大提高计算效率。同时,使用尺寸不一的多层网格结构,我有另一层思考,也是一个相对长期的铺垫,那就是在算法开发的后期基于这个多层结构使用多重网格算法,将求解器性能发挥到极致。
基于这种网格架构,我用fortran90语言重新写了一遍LBM求解代码。开始的时候只能计算2维情况,后来逐渐升级过渡到3维。开发流体力学求解器是一个不断迭代的过程,不要小看2维情况,虽然维度小,但是2维为我们提供了大量的准确性验证案例,因为一般意义上讲,维度越小的问题可能出现精确解析解的概率就越大,而有解析解就更方便我们测试求解器的准确性。
到了三维紊流问题,几乎没有任何情况有解析解,我们只能通过实验对比的方式进行验证,要注意的是,实验也不一定“准确”,因为很多情况我们需要精确控制各种实验参数才能获得有效的实验结果,而且实验一般都会不可避免地引入人为误差。
与MAC、SIMPLE算法不同,开发LBM流体求解器最难的是如何让密度函数在边界处变得更有实际物理意义,对于不同边界,我们要不断地思考、平衡各种分布函数可能存在的状态,如果边界条件做不好,那其实不光是算不算准的问题,而是能不能算的下去的问题,因为在很多情况下,如果边界条件设置不对,流体求解是会崩溃的,没有人希望一个模拟计算算到60%崩溃掉了,那样我们什么有意义的结果也获得不了,这可能是物理求解器和大部分所谓算法的最大区别。
这种会不会崩溃其实就是我们一直说的计算稳定性,一个优质的求解器,最大的特点,或者说起码需要具备的属性就是计算稳定性一定要高,商业客户是无法容忍算不下去的情况的,这造成的影响不单单是计算结果的问题,更重要的可能是牵扯到的时间成本。
开发流体力学求解器,我们所做的工作就是不断逼近真实物理情况,我们不能按照个人喜好凭空规定这个函数应该怎么写,那个模块应该怎么行为,而是要依据真实的物理规律,也就是遵循Navier-Stokes方程进行开发,所以真实的流体力学求解器开发出来,特别是针对紊流这些复杂情况,开发者其实并不能预测每一步的计算结果,所有的结果都是在物理规律的“规定”下逐渐演化出来的。

05 计算效率三年提升10倍,依然不被看好?
就是在这样的情况下我开发出了第一版三维LBM流体求解器,在计算精确性上,每次开发一个子版之后我都会与数据库中已有的测试案例进行对比,但是从计算稳定性、计算效率来讲其实并不高,我还记得在那个时候计算一个3000万网格(中等规模)的流动案例,如果计算能够完成,一般需要30-50小时,而且在很多情况下,代码在运行的过程中都会莫名其妙地崩溃,每一次的崩溃都是因为某一个网格在物理量上产生了奇异而导致的,但是对于不同的案例,出现问题的位置和时刻都不一样。在我们开发求解器的过程中,我们最怕遇到的问题就是那种飘忽不定、不明确又无法追踪的bug,这往往会让我们很头疼,调试一个算法bug可能需要1周甚至1个月都束手无策,没什么进展。而这往往是最打击人的,很多开发求解器的研究工作者都是在这种问题拖延之下放弃的,这也就是所谓开发过程存在的最大不确定性,它与纯粹软件开发不同,软件开发不存在不确定性,我们肯定知道这个一定能解决,只是能不能尽快找到这个bug的事情。而开发求解器出错,你无法确定的是你的模型错了,算法错了,还是代码本身有问题,后者还相对容易解决,前面两个才是真正的问题。有意思的是,关于流体力学,直到现在都没有“完美”的模型,光滑求解NS方程是千禧年7大难题之一,所以你必须在模型与代码之间做深度思考,不断平衡和尝试才有可能真正解决问题。
从0到1实现了,接下来最大的问题就是如何能更充分地发挥模型和代码优势,提高求解器本身的计算稳定性和计算效率。从这么多年的开发经历来看,这两个问题不是独立的问题,而一般是相随、相生的,我们没有办法先解决稳定性再提高计算效率(反之亦然),而更可能的方法是两个问题同时关注、同时解决。幸运的是,在那个时候我们团队又加入了两名核心算法工程师,读书时他们都是我的师弟,因此我们之间没有交流障碍,在他们顺利接下我这一棒后,就开始了“漫漫”的求解器优化过程。
做求解器优化的前提是他们要深入理解我之前用的网格架构、流体模型、LBM算法原理,然后在我的代码基础上做修改和升级。还记得无数个日日夜夜我们之间的讨论、争论和争吵,目的只有一个,如何能让这个求解器更好、更有竞争力。大的代码结构和框架的改变、差分格式的变换、代码规范和管理、数据结构相关的内存调用和管理,甚至只是一个细微的循环顺序修改(比如是从Z、Y循环到X?,还是先从X再到Z?)都在不断地发生、修改、优化和完善。很多次出差归来的夜晚,看到他们还在公司调试着代码,蘑菇云一样蓬乱的头发告诉我他们又经历了几个不眠之夜。一个曾是干净帅气的外企核心人员,一个曾是体面坚定的国企研究人员,现在愣是被我弄成了两个胡子拉碴的“再读博士生”。但我庆幸他们和我一起坚持着,就是在这种不断尝试、修正和规整的动作中,我们第二大版流体求解器诞生了——计算效率提高了10倍,计算稳定性从40%升级到80%。

我与两个师弟及另一个核心合伙人
此时此刻,我们第一版CAE产品终于落地了。集成着求解器、云原生的桌面版软件及SaaS智铸超云平台终于和客户见面了,而此时距离我们公司创立已经过去三年半。我们怀着忐忑的心情推出产品,希望不要出什么问题,一切平稳,客户喜欢。但现实总是残酷的,整整一年的推广,产品一堆问题等待解决,客户一堆需求无法满足,质疑与批评之声此起彼伏——客户不买单。我们甚至进不去客户的大门,保安大爷会直接轰我们出去,“哪来的回哪去”。
讲个笑话,还记得第一次向客户演示我们单机版CAE软件时,我们用车驮着一台沉重的工作站,怀着紧张又激动的心情来到工厂,在一个油腻的犄角旮旯里插上自己带的插线板,连上电脑,兴致勃勃地向客户展示着我们的成果,可忽然程序崩溃,自动退出。现在回想起来只是简单地一笑而过,但那个时候“死”的心都有。
与单机版软件不同,SaaS版软件不需要带工作站,只要联上网就能向客户展示,但是我们当时轻视了SaaS这种形态可能会产生的一系列问题:云计算、云作业调度、超大数据传输和显示(CAE仿真结果大小一般为几个G甚至几百G)会给整个产品体验带来非常大的不稳定性,网速不好呢?超算崩溃或出问题呢?那么大的数据怎么传输过来?意料之外的问题层出不穷,我们在公司的百兆网络环境中感觉不到这些问题,但大部分江浙、广东客户的网速就是10M网,有的地方甚至更低,而且工厂里所有的人都在共享使用。
再讲个笑话,我们的销售在客户工厂里展示第一版SaaS平台时,好几分钟加载不出来页面,销售急的满头大汗,不住地跟客户道歉,最后客户看着都觉得不好意思了,还反过来安慰他。销售回来后连骂产品团队的力气都没有了,全公司一片哗然。
这就是适创科技2019年底的状态,还干不干?

06 五年提速百倍,大浪淘沙中的蜕变
创立公司时我们就有一个不成文的规定:坚持做正确而难的事,要有直面问题和解决问题的魄力。所以此时不管团队有多大的怨气,没有人说不干,没有人要退出!
我已经没有太多时间直接做算法或求解器了,我必须分出很大精力集中在产品整体规划、投融资和公司团队组建上。那时公司里有一种声音——我们应该控制成本,在产品没有真正能满足客户需求前尽量保持甚至缩小团队规模。但是我的想法不同,没有产品是天生完美的,问题不能通过回避去解决。我再一次拿出这句话:“我们一定要敢于正视问题,直面问题,解决问题,不能回避,也不能退缩。”而真正解决问题的方法就在那,就是我们不能缩减,反而要加大对研发团队的投入,才能在将来可预期的时间内解决现有的这些问题,只有完善产品才能获得客户。我说服了团队,虽然每个人的心里都在打鼓。
那个时候我真正感觉到自己在践行那句话:做正确而难的事。认识到正确本身不难,敢不敢去做才最考验人。
2020年,我一边和产品团队不断梳理产品、开发路线和客户需求,一边东奔西跑地见投资人,跟他们不厌其烦地讲产品故事和我们的理想。从早晨8:30到晚上11:30,我和市场总监一天15个小时最多可以见6拨投资人,也就是在那时候,我养成了上车就睡觉的习惯,而且睡得特别踏实,从而养精蓄锐,一下车就立刻满血复活。直到现在我还是改不了这个“毛病”,一上车就哈气连天。
终于在2020年9月,我们第一次拿到了机构的投资(启迪之星和亚杰资本),团队内部士气大涨——被市场和客户反复鞭打的我们,太需要一次胜利了。
除了融资成功,与新销售总监的见面给我打了一剂新的强心针。我们一见如故,尽管相差十岁,但在市场策略和团队建设上的想法高度一致。我们花了两个月重新梳理销售策略、打法,并开始重新组建销售团队。与此同时,产品团队马不停蹄地对产品进行大刀阔斧的升级和优化。我知道,唯一能给他们争取的就是时间,事实也证明我们确实经受住了考验,计算稳定性达到100%之前,没有人会停下脚步,这就是适创科技团队所形成的共识。
随着公司的不断发展,又有许多新成员加入了我们,他们也在我师弟的肩膀上将求解器继续升华。同时通过与客户不断的交流和反馈,产品的稳定性也获得了极大的提升,这不是个一蹴而就的事情,是耐心地文火慢炖和坚定的决心换来的。我的师弟接替我成为了产品开发的负责人,我的学生也已经是产品团队的核心骨干,我自己则过渡成了一名“半路出家的销售”。在所有人的努力下,许多我们之前想都不敢想、碰都不敢碰的难题都陆续被攻克,对产品来说,我们的软件终于从一个“丑小鸭”蜕变成为一只“黑天鹅”,对销售来说,我们与客户之间建立了更加默契的关系,不仅能够顺利进入客户大门,而且企业技术负责人,甚至总经理也开始与我们进行认真深入的交流。
就在2021年11月,算法团队通过创新优化,在已有的流体求解器能力上又将计算效率提高了10倍,整体平台计算稳定性达到了至少95%以上。
从我的第一版流体求解器到现在,计算效率整整提升了100倍——2个量级的跨越。
之前一个大型薄壁件的计算需要1-2周,甚至可能因为网格量太大无法计算,现在同样的大型薄壁件,计算时间只需2-3.5小时;
之前计算10小时的案例,现在几分钟之内就能完成。
当然,这都是在保证计算精度的前提下实现的。

我们的自主CAE软件局部计算效果
我们的另一个产品团队甚至已经开发出了即时仿真算法,也就是条件变换后CAE仿真结果会立即预测出来,不需要“计算”,听起来是不是很酷,这就是我们下一代智能设计产品的原型,2022年该产品将有望推向市场。
五年,就像是经历了一场大考。每一年公司都会遇到各种各样的问题,但庆幸的是我们得到了多方强有力的支持,投资人和投资机构,创业园区和孵化器,更不用说远见卓识的国家政策。但这不是可**的经历,更不是可以抄来的作业,适创科技能够坚持下来,靠的是大浪淘沙下依然无坚不摧的团队。从创立到现在,适创科技的核心团队始终保持着一股强大的凝聚力,非但没有萎缩,反而越来越大,不管中间经历了多少起起伏伏,不管经历过多少争吵和迷茫,几乎所有入职3年以上的老员工都还站在我的背后,撑起了整个公司。
“适创科技最强的竞争力,是我们对核心求解器的理解和开发能力。”这是我对每一个投资人说过的。整个CAE领域有五大核心底层求解器:力、热、光、声、电,最难的是力学求解器,而力学又分为流体力学和结构、塑形力学。我们瞄准了流体力学并正式迈进了有力的一步,将来在开发完成热、声、电求解器后,我们的算法团队会以更大的热诚,去攻克更为艰难但应用更加普遍的可压缩流动、燃烧以及塑性变形力学求解器等,从而使适创科技CAE计算平台不仅能够打入铸造、注塑行业,同时能够深入到汽车、航空航天和核电等领域,让Supreium-CAE助力整个中国工业的数字化转型——这才是适创科技真正的理想和目标。

既已入局,便要拼尽全力。我们相信,越是困难的事越是应该我们来做,而越是做有挑战的事,才越能够让我们离心中那个伟大的公司更进一步。
“立大目标、做难而正确的事”,才能真正让我们的血液沸腾起来。
(End)
[1] 来自平安证券研究报告:《工业软件系列报告(一)》
[2] 来自财信证券研究报告《国防军工行业深度:战鹰展翅啸寰宇,飞天直上九重霄》


